Building on Quicksand
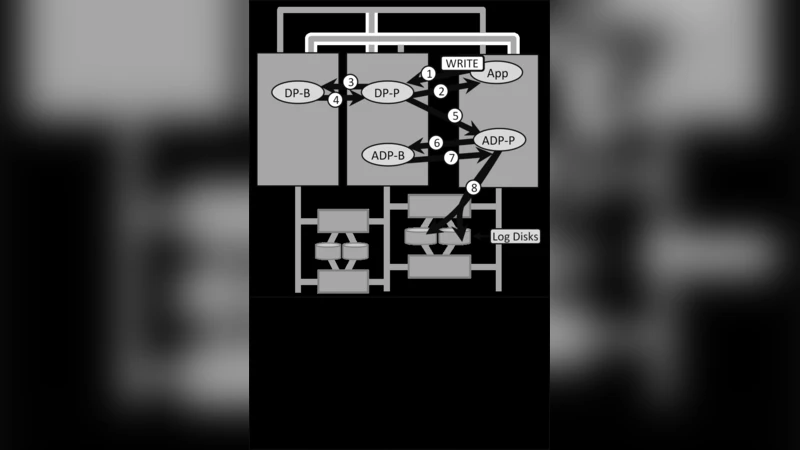
Reliable systems have always been built out of unreliable components. Early on, the reliable components were small such as mirrored disks or ECC (Error Correcting Codes) in core memory. These systems were designed such that failures of these small components were transparent to the application. Later, the size of the unreliable components grew larger and semantic challenges crept into the application when failures occurred. As the granularity of the unreliable component grows, the latency to communicate with a backup becomes unpalatable. This leads to a more relaxed model for fault tolerance. The primary system will acknowledge the work request and its actions without waiting to ensure that the backup is notified of the work. This improves the responsiveness of the system. There are two implications of asynchronous state capture: 1) Everything promised by the primary is probabilistic. There is always a chance that an untimely failure shortly after the promise results in a backup proceeding without knowledge of the commitment. Hence, nothing is guaranteed! 2) Applications must ensure eventual consistency. Since work may be stuck in the primary after a failure and reappear later, the processing order for work cannot be guaranteed. Platform designers are struggling to make this easier for their applications. Emerging patterns of eventual consistency and probabilistic execution may soon yield a way for applications to express requirements for a “looser” form of consistency while providing availability in the face of ever larger failures. This paper recounts portions of the evolution of these trends, attempts to show the patterns that span these changes, and talks about future directions as we continue to “build on quicksand”.
💡 Research Summary
The paper traces the evolution of fault‑tolerant system design from the early days when unreliable components were tiny—mirrored disks, ECC memory, and other micro‑level error‑correction mechanisms—to the present era where entire servers, storage pools, or even whole data‑centers can be the unit of failure. In the early era, replication and backup were performed synchronously: the primary would not acknowledge a client request until the backup had confirmed receipt of the state change. This model guaranteed strong consistency but became untenable as the latency to contact a distant backup grew with the size of the unreliable component.
To address this, modern platforms adopt “asynchronous state capture.” The primary accepts work, immediately returns a response, and then propagates the state change to one or more backups in the background, often via a write‑ahead log, a background replication thread, or a message‑queue. This decouples client latency from backup latency, dramatically improving responsiveness and overall availability. However, the paper emphasizes two fundamental implications of this shift.
First, the primary’s promise becomes probabilistic. A failure that occurs shortly after the primary acknowledges a request can leave the backup unaware of the committed operation. Consequently, no guarantee of “always‑correct” execution exists; instead, systems must expose a probability‑based service‑level agreement (SLA) that quantifies the chance that a given operation has been durably replicated.
Second, ordering guarantees evaporate. Because work may be buffered in the primary after a crash and replayed later, the global processing order cannot be assumed. Applications therefore must be built around eventual consistency: they must tolerate out‑of‑order execution, duplicate processing, and temporary divergence between replicas. This forces developers to design idempotent operations, conflict‑resolution strategies, and convergence mechanisms (e.g., CRDTs, last‑writer‑wins, or custom merge functions).
The authors illustrate these concepts with three concrete case studies.
-
Log‑based replication in large‑scale NoSQL stores – Writes are appended to a durable log; the primary returns success once the log entry is persisted, while follower nodes consume the log asynchronously. The system achieves low write latency but tolerates a window of inconsistency that is resolved when followers catch up.
-
At‑least‑once delivery in distributed message queues – Producers publish messages to a primary broker, which immediately acknowledges receipt. The broker then forwards messages to downstream consumers asynchronously. Consumers must handle possible duplicates, and the queue guarantees that every message will eventually be delivered, not that it will be delivered exactly once.
-
Write‑behind caching in cloud object storage – Client writes are stored locally in a fast cache; a background process flushes the cache to remote storage. The client sees a successful write instantly, while the remote copy may lag, creating a temporary divergence that is reconciled during the flush.
From these examples the paper extracts three design patterns that can help platform builders and application developers manage the new reality.
-
Probabilistic Promise Interface – APIs expose not only success/failure but also a confidence level (e.g., “99.9 % durability”) so callers can make informed trade‑offs.
-
State‑Capture Tokens – Each asynchronous replication operation is tagged with a token that the backup acknowledges when it applies the change. Tokens enable precise tracking of replication progress and simplify recovery logic.
-
Pluggable Conflict‑Resolution Plugins – Systems provide a framework where applications can declare their consistency policy (CRDT, merge‑function, custom reconciliation) and the runtime invokes the appropriate plugin when divergent states are detected.
The paper also outlines promising research directions. Quantitative modeling of probabilistic guarantees using Markov chains or Bayesian inference could allow automated SLA generation based on observed failure rates and replication latencies. Machine‑learning‑driven failure prediction could trigger proactive replication before a crash, reducing the window of inconsistency. Finally, multi‑backup collaborative protocols (e.g., quorum‑based “write‑behind” with coordinated acknowledgment) may combine the low latency of asynchronous writes with stronger durability guarantees.
In conclusion, the authors argue that building reliable services on ever‑larger unreliable components is not a paradox but an engineering discipline that requires a shift from absolute guarantees to probabilistic promises and from strict ordering to eventual convergence. By embracing asynchronous state capture, exposing confidence levels, and providing flexible conflict‑resolution mechanisms, system designers can deliver high availability while still giving applications the tools they need to achieve correct, convergent behavior. This roadmap offers a practical path forward for the next generation of distributed, cloud‑native infrastructures.
Comments & Academic Discussion
Loading comments...
Leave a Comment