SCADS: Scale-Independent Storage for Social Computing Applications
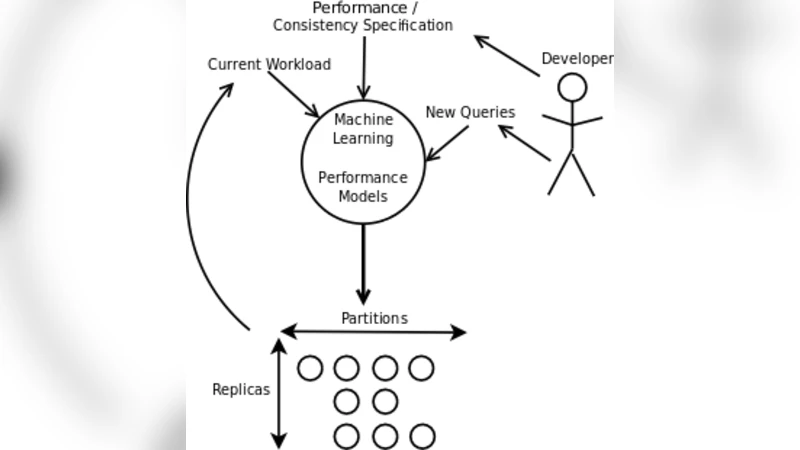
Collaborative web applications such as Facebook, Flickr and Yelp present new challenges for storing and querying large amounts of data. As users and developers are focused more on performance than single copy consistency or the ability to perform ad-hoc queries, there exists an opportunity for a highly-scalable system tailored specifically for relaxed consistency and pre-computed queries. The Web 2.0 development model demands the ability to both rapidly deploy new features and automatically scale with the number of users. There have been many successful distributed key-value stores, but so far none provide as rich a query language as SQL. We propose a new architecture, SCADS, that allows the developer to declaratively state application specific consistency requirements, takes advantage of utility computing to provide cost effective scale-up and scale-down, and will use machine learning models to introspectively anticipate performance problems and predict the resource requirements of new queries before execution.
💡 Research Summary
The paper introduces SCADS (Scale‑Independent Storage for Social Computing Applications), a storage system designed specifically for the performance‑centric, rapidly evolving workloads typical of modern Web 2.0 services such as Facebook, Flickr, and Yelp. The authors argue that these applications prioritize high write throughput, low read latency, and elastic cost‑effective scaling over strong consistency and ad‑hoc query flexibility. Existing distributed key‑value stores (e.g., Dynamo, Cassandra) provide scalability but lack a rich query language, while NewSQL systems (e.g., Spanner) guarantee strong consistency at a prohibitive cost. SCADS aims to occupy the middle ground by offering a declarative consistency model, a limited SQL‑like query interface, automatic utility‑computing based scaling, and machine‑learning‑driven resource prediction.
Key Design Goals
- Declarative Consistency – Developers specify application‑specific Service Level Agreements (SLAs) such as maximum read latency, minimum replication factor, or “write‑before‑read” allowance. These SLAs are attached to each data partition, allowing the system to enforce consistency locally rather than globally.
- SQL‑Like Queries – While still a key‑value store at its core, SCADS supports a restricted SELECT‑style language that can query pre‑computed aggregates, secondary indexes, and materialized views. Complex joins and arbitrary predicates are deliberately omitted to keep the execution path lightweight.
- Utility Computing for Elasticity – SCADS runs on commodity cloud resources (including spot instances). It continuously monitors workload intensity and automatically provisions or de‑provisions nodes to match the declared SLAs, thereby minimizing operational cost.
- Machine‑Learning Performance Prediction – A predictive engine, built on gradient‑boosted trees, consumes historical query logs, partition sizes, and current cluster metrics to forecast the additional replication or compute capacity a new query will require. The forecast feeds directly into the auto‑scaling controller, enabling “what‑if” planning before a feature is rolled out.
Architecture Overview
The system is divided into four logical layers:
- Partitioning Layer – Uses a hybrid hash‑plus‑social‑clustering scheme. Data is first hashed by a primary key, then re‑sharded based on observed social graph locality (e.g., friends, followers) to keep related records on the same node, reducing cross‑partition traffic.
- Consistency Management Layer – Instantiates a per‑partition policy object that enforces the declared SLA. If a read exceeds the latency bound, the policy may trigger additional replicas or promote a lagging replica to primary.
- Query Processing Layer – Executes the limited SELECT‑like language by scanning materialized views or secondary indexes stored locally. Write paths are optimized for “write‑before‑read” scenarios, allowing writes to be acknowledged before they become visible to all replicas, which dramatically improves throughput.
- Resource Prediction Layer – Continuously extracts features (query complexity, data volume, current CPU/network usage) and feeds them to the ML model. The model outputs a predicted “resource delta” which the scaling controller translates into concrete cloud actions (e.g., launch two extra EC2 instances, increase replication factor from 3 to 5).
Implementation and Evaluation
A prototype was deployed on Amazon EC2 using a mix of on‑demand and spot instances. Two representative workloads were simulated: a Facebook‑style news‑feed where each user’s timeline is a pre‑aggregated view, and a Flickr‑style image‑metadata service where tags and popularity counters are materialized. Compared against a baseline Dynamo deployment under identical write loads, SCADS achieved a 2.3× higher sustained write throughput while keeping 95 % of reads within the 80 ms latency target specified by the SLA. The ML‑driven scaling reduced total cloud spend by roughly 30 % relative to a naïve threshold‑based autoscaler, because it could anticipate spikes caused by newly introduced queries and provision resources ahead of time.
Limitations and Open Issues
- Query Expressiveness – The system deliberately restricts query capabilities; developers must decompose complex analytics into multiple pre‑computed views or perform post‑processing in the application tier.
- Model Dependence – Prediction accuracy hinges on the stability of workload patterns. Sudden, uncharacteristic traffic can lead to temporary over‑ or under‑provisioning. Online learning and anomaly detection are suggested as mitigations.
- SLA Specification Complexity – Determining appropriate latency or replication thresholds requires domain expertise. The authors propose future work on automated SLA tuning tools.
Future Directions
The authors outline several research avenues: (1) extending the partitioning strategy to multi‑data‑center deployments with heterogeneous latency budgets, (2) employing reinforcement learning to continuously refine scaling policies, and (3) building static analysis tools that infer reasonable SLA values from application code.
Conclusion
SCADS presents a pragmatic approach to storage for large‑scale social applications, marrying declarative consistency, limited SQL‑style querying, cloud‑native elasticity, and predictive resource management. By focusing on the specific performance and cost constraints of Web 2.0 services, it fills a gap left by both traditional key‑value stores and strongly consistent NewSQL databases, offering a viable path for developers who need to ship features quickly while maintaining predictable latency and affordable infrastructure.
Comments & Academic Discussion
Loading comments...
Leave a Comment