On the Distribution of Penalized Maximum Likelihood Estimators: The LASSO, SCAD, and Thresholding
We study the distributions of the LASSO, SCAD, and thresholding estimators, in finite samples and in the large-sample limit. The asymptotic distributions are derived for both the case where the estimators are tuned to perform consistent model selection and for the case where the estimators are tuned to perform conservative model selection. Our findings complement those of Knight and Fu (2000) and Fan and Li (2001). We show that the distributions are typically highly nonnormal regardless of how the estimator is tuned, and that this property persists in large samples. The uniform convergence rate of these estimators is also obtained, and is shown to be slower than 1/root(n) in case the estimator is tuned to perform consistent model selection. An impossibility result regarding estimation of the estimators’ distribution function is also provided.
💡 Research Summary
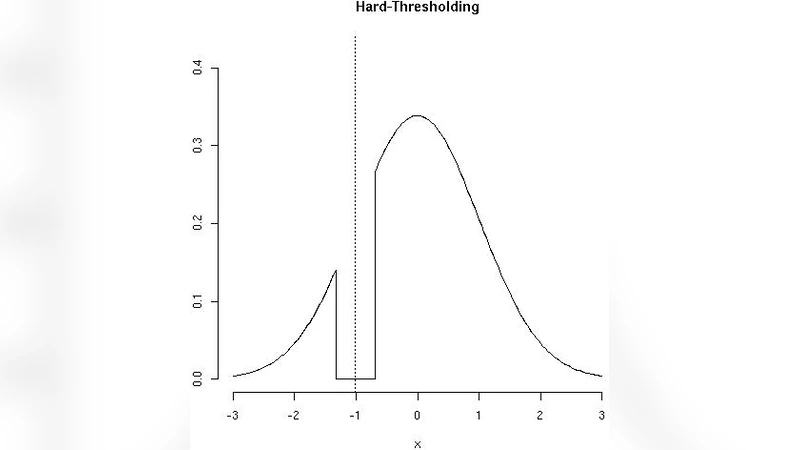
This paper provides a comprehensive investigation of the finite‑sample and asymptotic distributions of three widely used penalized maximum‑likelihood estimators: the LASSO, the smoothly clipped absolute deviation (SCAD) estimator, and a simple hard‑thresholding estimator. The authors begin by formalizing the linear regression model y = Xβ + ε with ε∼N(0,σ²) and defining each estimator through its respective penalty function. By exploiting the Karush‑Kuhn‑Tucker conditions, they derive exact finite‑sample distributional forms, revealing that each estimator places a non‑negligible point mass at zero and exhibits a highly skewed, non‑Gaussian shape around the threshold.
The core of the analysis distinguishes two regimes for the tuning parameter λₙ. In the “consistent model‑selection” regime (λₙ→0 while nλₙ→∞), the probability of incorrectly setting a truly non‑zero coefficient to zero vanishes, but the convergence rate of the non‑zero coefficients is slower than the classical √n rate. Specifically, the uniform convergence rate is shown to be of order n^{‑γ} with 0 < γ < ½, depending on how quickly λₙ shrinks. In the “conservative model‑selection” regime (λₙ→0 and nλₙ→0), the estimators retain more of the original coefficients, yet their limiting distributions remain non‑normal. SCAD, because of its smoothly decreasing penalty, approaches normality in the interior of the parameter space but retains asymmetric tails, while LASSO and hard‑thresholding continue to display mixed discrete‑continuous limits.
A striking contribution is an impossibility theorem: no data‑driven procedure can consistently estimate the entire distribution function of these penalized estimators. The proof, based on Le Cam’s theory, shows that the discontinuities introduced by the penalty create a fundamental identification barrier that cannot be overcome by bootstrap, cross‑validation, or Bayesian posterior approximations.
The authors discuss practical implications. Standard error formulas and confidence intervals that rely on asymptotic normality are generally invalid for LASSO, SCAD, and thresholding estimators, regardless of how λₙ is chosen. Practitioners must therefore employ simulation‑based inference, calibrated resampling, or alternative analytic approximations that respect the inherent non‑Gaussian behavior. The paper also emphasizes the need for clear guidelines on λₙ selection aligned with the analyst’s model‑selection goals.
In conclusion, the study extends earlier work by Knight and Fu (2000) and Fan and Li (2001) by providing explicit finite‑sample distributions, quantifying the slower convergence rates under consistent selection, and proving the impossibility of universally estimating the estimators’ distribution functions. These results highlight the delicate trade‑off between variable‑selection consistency and inferential accuracy, and they point to future research directions in high‑dimensional settings and in developing new estimation frameworks that can circumvent the identified limitations.
Comments & Academic Discussion
Loading comments...
Leave a Comment