Learning, complexity and information density
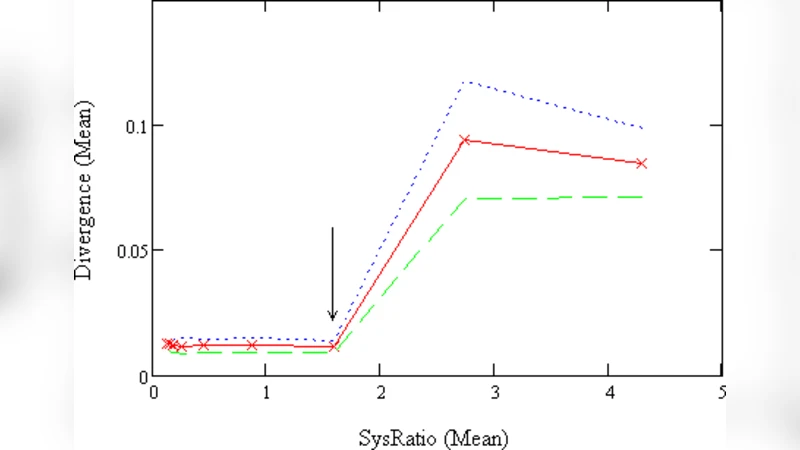
What is the relationship between the complexity of a learner and the randomness of his mistakes? This question was posed in \cite{rat0903} who showed that the more complex the learner the higher the possibility that his mistakes deviate from a true random sequence. In the current paper we report on an empirical investigation of this problem. We investigate two characteristics of randomness, the stochastic and algorithmic complexity of the binary sequence of mistakes. A learner with a Markov model of order $k$ is trained on a finite binary sequence produced by a Markov source of order $k^{}$ and is tested on a different random sequence. As a measure of learner’s complexity we define a quantity called the \emph{sysRatio}, denoted by $\rho$, which is the ratio between the compressed and uncompressed lengths of the binary string whose $i^{th}$ bit represents the maximum \emph{a posteriori} decision made at state $i$ of the learner’s model. The quantity $\rho$ is a measure of information density. The main result of the paper shows that this ratio is crucial in answering the above posed question. The result indicates that there is a critical threshold $\rho^{}$ such that when $\rho\leq\rho^{}$ the sequence of mistakes possesses the following features: (1)\emph{}low divergence $\Delta$ from a random sequence, (2) low variance in algorithmic complexity. When $\rho>\rho^{}$, the characteristics of the mistake sequence changes sharply towards a\emph{}high\emph{$\Delta$} and high variance in algorithmic complexity.
💡 Research Summary
The paper investigates the quantitative relationship between a learner’s internal complexity and the randomness of the mistakes it makes. Building on earlier theoretical work that suggested more complex learners produce error sequences that deviate from true randomness, the authors design an empirical study that measures two complementary aspects of randomness: (1) stochastic divergence from an ideal random sequence, denoted Δ, and (2) algorithmic (Kolmogorov‑type) complexity, approximated by compression‑based “correlator” complexity.
The key methodological innovation is the definition of a system ratio (ρ), which serves as a proxy for the learner’s information density. For a learner that uses a Markov model of order k, the authors construct a binary string where each bit encodes the maximum‑a‑posteriori decision taken at each state of the model. The length of this string after lossless compression is divided by its original length, yielding ρ. A low ρ indicates that the model’s decision table is highly compressible, i.e., it captures regularities efficiently; a high ρ signals a more “raw” representation with less compression.
In the experimental protocol, a synthetic binary source generated by a Markov chain of order k* supplies both a training sequence and a separate test sequence. The learner is trained on the first sequence using a Markov model of order k (which may be equal to, lower than, or higher than k*). After training, the learner predicts the bits of the test sequence; mismatches constitute the error sequence. The authors then compute Δ (the Kullback‑Leibler divergence between the empirical distribution of the error sequence and that of a truly random binary sequence) and the correlator complexity of the error sequence.
The results reveal a sharp phase‑transition‑like behavior governed by a critical threshold ρ*. When ρ ≤ ρ*, the error sequence exhibits (i) low stochastic divergence (Δ close to zero), meaning it is statistically indistinguishable from a random sequence, and (ii) low variance in algorithmic complexity, indicating that the error strings are uniformly simple. Conversely, when ρ > ρ*, both Δ and the variance of the correlator complexity increase dramatically. In this regime the learner’s mistakes contain discernible structure, reflecting the residual “uncompressed” information retained in the learner’s internal model.
From an information‑theoretic perspective, ρ captures how efficiently the learner compresses the training data into a predictive model. Efficient compression (low ρ) reduces the amount of surplus information that can leak into predictions, thereby keeping mistakes random. Inefficient compression (high ρ) leaves excess bits that manifest as systematic patterns in the error sequence. Hence, the relationship between learner complexity and error randomness is mediated not simply by the size of the model but by the density of useful information it encodes.
The authors discuss several implications. First, the findings suggest a principled way to balance model capacity and generalization: maximizing compression (or minimizing ρ) may be a useful regularization objective to keep prediction errors close to random noise. Second, the identified threshold ρ* provides a concrete diagnostic for detecting when a model has become overly complex relative to the data it has seen. Third, the work bridges stochastic and algorithmic notions of randomness, showing that they co‑vary in the context of learning‑induced errors.
Finally, the paper outlines future directions, including extending the analysis to non‑Markovian learners (e.g., neural networks), testing on real‑world data sets, and exploring human learning scenarios where cognitive constraints might play the role of an implicit compression mechanism. By linking information density to the statistical properties of mistakes, the study offers a fresh lens on overfitting, model selection, and the fundamental limits of predictive learning.
Comments & Academic Discussion
Loading comments...
Leave a Comment