Influence Blocking Maximization in Social Networks under the Competitive Linear Threshold Model Technical Report
In many real-world situations, different and often opposite opinions, innovations, or products are competing with one another for their social influence in a networked society. In this paper, we study competitive influence propagation in social networks under the competitive linear threshold (CLT) model, an extension to the classic linear threshold model. Under the CLT model, we focus on the problem that one entity tries to block the influence propagation of its competing entity as much as possible by strategically selecting a number of seed nodes that could initiate its own influence propagation. We call this problem the influence blocking maximization (IBM) problem. We prove that the objective function of IBM in the CLT model is submodular, and thus a greedy algorithm could achieve 1-1/e approximation ratio. However, the greedy algorithm requires Monte-Carlo simulations of competitive influence propagation, which makes the algorithm not efficient. We design an efficient algorithm CLDAG, which utilizes the properties of the CLT model, to address this issue. We conduct extensive simulations of CLDAG, the greedy algorithm, and other baseline algorithms on real-world and synthetic datasets. Our results show that CLDAG is able to provide best accuracy in par with the greedy algorithm and often better than other algorithms, while it is two orders of magnitude faster than the greedy algorithm.
💡 Research Summary
The paper addresses the problem of limiting the spread of a competing influence in a social network when two opposing ideas, products, or rumors propagate simultaneously. To capture this competitive diffusion, the authors extend the classic Linear Threshold (LT) model into a Competitive Linear Threshold (CLT) model. In CLT each node can be in one of three states—inactive, positively active (+), or negatively active (‑). Every directed edge carries two independent weights, a positive weight w⁺ and a negative weight w⁻, and each node draws two independent thresholds θ⁺ and θ⁻ from the uniform distribution. Positive and negative cascades evolve in parallel exactly as in the LT model; however, when a node would become active by both cascades in the same time step, the negative cascade dominates (the “negative‑dominance rule”). This rule reflects the well‑known negativity bias in social psychology and ensures that rumors are hard to counteract.
Given a fixed set of negative seeds N₀ (the source of the competing influence) and a budget k, the Influence Blocking Maximization (IBM) problem asks for a set S of at most k positive seeds that maximizes the expected number of nodes that would have become negatively active without S but remain uninfected when S is present. Formally, the objective σ_NIR(S) is the expectation over all threshold realizations of the size of the “influence‑blocking set” IBS(S). The authors first prove that IBM under CLT is NP‑hard via a reduction from Vertex Cover.
The central theoretical contribution is the proof that σ_NIR(S) is monotone and submodular. To establish submodularity, they construct a random live‑path graph: for each node they independently select at most one incoming positive edge with probability w⁺ and at most one incoming negative edge with probability w⁻. The resulting subgraphs G⁺ and G⁻ contain only the selected positive or negative edges, respectively. In this random graph a node becomes +active if the shortest distance from any positive seed to the node (through G⁺) is finite and strictly smaller than the shortest distance from any negative seed (through G⁻); it becomes –active if the opposite holds or the distances are equal (negative dominance). This construction yields a distribution over deterministic activation outcomes that is equivalent to the original stochastic CLT process. Using this equivalence, they adapt the classic proof technique of Kempe et al. (2003) to show the diminishing‑returns property, i.e., submodularity, for σ_NIR. Consequently, a simple greedy algorithm that iteratively adds the node with the largest marginal gain achieves a (1 − 1/e − ε) approximation guarantee for any ε > 0.
Although the greedy algorithm is theoretically appealing, each iteration requires many Monte‑Carlo simulations of the competitive diffusion, making it impractical for networks with thousands of nodes. To overcome this scalability bottleneck, the authors propose CLDAG, an efficient heuristic that exploits structural properties of the LT model on Directed Acyclic Graphs (DAGs). The key steps of CLDAG are:
- DAG Decomposition – The original directed graph is transformed into a collection of DAGs (by removing cycles or using a topological ordering). Within each DAG, influence can only travel forward, eliminating the need for repeated sampling.
- Dynamic Programming (DP) Computation – For each DAG, the algorithm computes, in a single pass, the earliest time (or distance) at which a node would be reached by the positive cascade and by the negative cascade, using the edge weights w⁺ and w⁻. The DP respects the negative‑dominance rule when the two arrival times coincide.
- Greedy Seed Selection with DP‑Based Marginals – Using the pre‑computed DP values, the marginal gain of adding any candidate node to the current seed set can be evaluated in O(1) or O(out‑degree) time, far cheaper than Monte‑Carlo estimation. The algorithm then selects the node with the highest marginal gain, updates the DP tables locally, and repeats until k seeds are chosen.
The authors evaluate CLDAG against four baselines: (i) the exact greedy algorithm (Monte‑Carlo based), (ii) a high‑degree heuristic, (iii) a random seed selection, and (iv) the state‑of‑the‑art competitive influence maximization method for the Independent Cascade model (Budak et al.). Experiments are conducted on three real‑world social networks (e.g., Facebook, Twitter, LiveJournal) and several synthetic graphs (Erdős‑Rényi, Barabási‑Albert, small‑world). The metrics are (a) the achieved σ_NIR (i.e., number of blocked negative nodes) and (b) runtime.
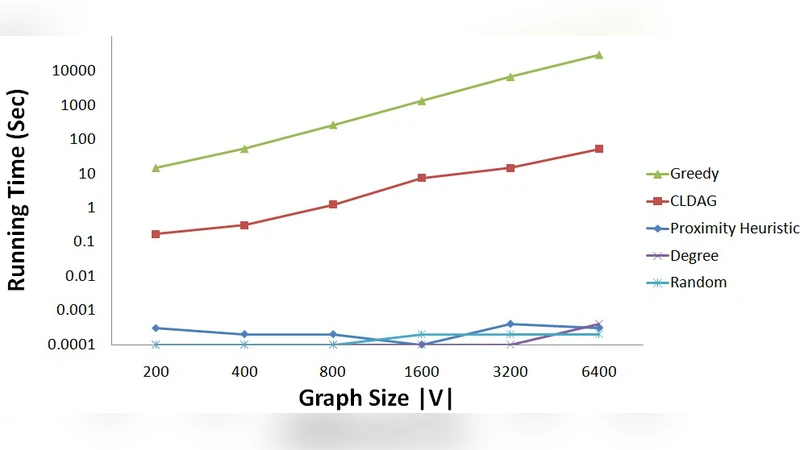
Results show that CLDAG consistently matches or slightly exceeds the greedy algorithm’s blocking performance—differences are typically within 1–3 %—while being two orders of magnitude faster. For a network of 6.4 k nodes, the greedy method needs over 8 hours to finish, whereas CLDAG completes in under 5 minutes. Even on larger synthetic graphs with 100 k nodes, CLDAG finishes within a few tens of minutes, demonstrating excellent scalability. Moreover, CLDAG outperforms the degree‑based and random heuristics by a substantial margin (often > 10 % improvement in σ_NIR).
In the discussion, the authors note that the negative‑dominance rule is not essential for the submodularity proof; a random tie‑breaking rule would also work with minor modifications. They also compare their work to related studies on competitive diffusion, emphasizing that while previous works have shown that influence maximization (i.e., maximizing the spread of one cascade) is not submodular under CLT, the complementary problem of blocking the opponent’s spread is submodular—a subtle but important distinction.
The paper concludes by highlighting several future directions: extending the model to more than two competing cascades, incorporating time‑varying edge weights, handling dynamic seed selection (online setting), and integrating user‑level attributes (e.g., susceptibility). Overall, the study makes a significant contribution by (1) formalizing a realistic competitive diffusion model with a psychologically motivated tie‑breaking rule, (2) establishing rigorous theoretical guarantees for the blocking problem, and (3) delivering a practical, scalable algorithm (CLDAG) that bridges the gap between theory and real‑world applications such as rumor control, viral marketing counter‑campaigns, and public‑health information dissemination.
Comments & Academic Discussion
Loading comments...
Leave a Comment