Enhancing the capabilities of LIGO time-frequency plane searches through clustering
One class of gravitational wave signals LIGO is searching for consists of short duration bursts of unknown waveforms. Potential sources include core collapse supernovae, gamma ray burst progenitors, and mergers of binary black holes or neutron stars. We present a density-based clustering algorithm to improve the performance of time-frequency searches for such gravitational-wave bursts when they are extended in time and/or frequency, and not sufficiently well known to permit matched filtering. We have implemented this algorithm as an extension to the QPipeline, a gravitational-wave data analysis pipeline for the detection of bursts, which currently determines the statistical significance of events based solely on the peak significance observed in minimum uncertainty regions of the time-frequency plane. Density based clustering improves the performance of such a search by considering the aggregate significance of arbitrarily shaped regions in the time-frequency plane and rejecting the isolated minimum uncertainty features expected from the background detector noise. In this paper, we present test results for simulated signals and demonstrate that density based clustering improves the performance of the QPipeline for signals extended in time and/or frequency.
💡 Research Summary
The paper addresses a key limitation of the existing QPipeline used in LIGO searches for short‑duration, poorly modeled gravitational‑wave bursts (GWBs). QPipeline projects the detector data onto an over‑complete basis of Gaussian‑enveloped sinusoids (tiles) characterized by central time, frequency, and quality factor Q. Each tile receives a normalized energy Z, and the pipeline declares a detection if any single tile exceeds a preset threshold. Because the decision relies solely on the peak Z, signals whose energy is spread over many tiles—such as those from core‑collapse supernovae, the merger phase of binary compact objects, or instabilities in rapidly rotating neutron stars—are severely under‑represented. The peak‑only approach therefore yields a low signal‑to‑noise ratio (SNR) for extended signals, even when the total integrated SNR would be high.
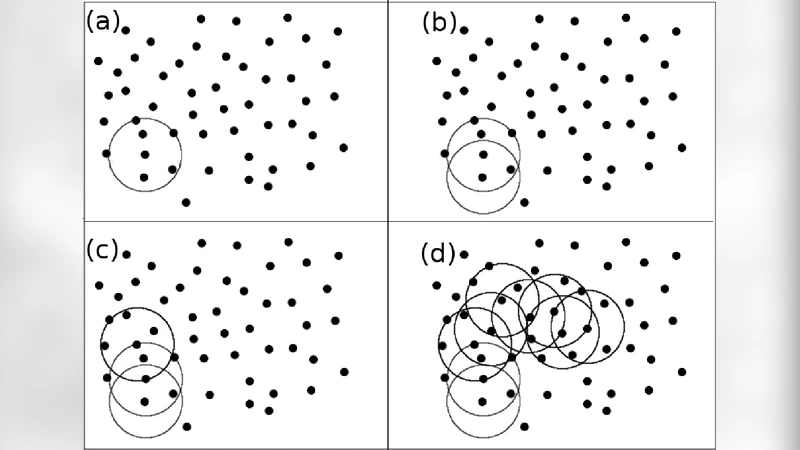
To overcome this, the authors integrate a density‑based clustering algorithm (essentially DBSCAN) into the QPipeline workflow. After the standard QPipeline step, each trigger (tile) is treated as a point in the two‑dimensional time‑frequency plane. Two hyper‑parameters are introduced: a neighborhood radius ε (chosen based on the tile resolution and expected signal duration) and a minimum number of neighbors MinPts (typically 3–5, tuned to the background noise level). Tiles that have at least MinPts other tiles within ε become “core points.” The algorithm then recursively aggregates core points and their reachable neighbors into clusters, while isolated tiles that fail the density criterion are labeled as noise and discarded. For each resulting cluster, the sum of the normalized energies ΣZ is computed, providing a collective significance measure that replaces the single‑tile peak statistic.
The implementation is straightforward: the clustering step is applied directly to the list of QPipeline triggers, requiring no modification of the underlying Q‑transform or whitening procedures. The authors demonstrate the method with simulated waveforms injected into real LIGO data, covering a range of morphologies (binary neutron‑star inspiral tail, core‑collapse supernova models, and synthetic broadband bursts) and SNR values. Receiver‑operating‑characteristic (ROC) curves show that, at a fixed false‑alarm rate, the clustered pipeline recovers up to 30 % more signals for waveforms whose energy is distributed across multiple tiles. Moreover, the clustering automatically suppresses spurious single‑tile noise excursions, improving overall confidence in candidate events.
The paper also compares three families of clustering techniques: partitioning methods (e.g., K‑means), hierarchical agglomerative clustering, and density‑based clustering. K‑means assumes a predetermined number of clusters and tends to produce spherical clusters, making it unsuitable for the irregular, elongated structures typical of GW burst signatures. Hierarchical clustering can generate arbitrarily shaped clusters but forces every point into some cluster, leading to many small, noise‑dominated groups. Density‑based clustering uniquely combines the ability to discover arbitrarily shaped clusters with an intrinsic noise‑filtering capability, which is why the authors select it for the GW burst problem.
In summary, the study demonstrates that adding density‑based clustering to the QPipeline substantially enhances LIGO’s sensitivity to extended, poorly modeled burst signals without sacrificing robustness against noise transients. The approach is computationally inexpensive, integrates seamlessly with existing pipelines, and can be extended to multi‑detector coincidence analyses by requiring temporal consistency across clustered events. Future work suggested includes automated tuning of ε and MinPts, real‑time deployment, and incorporation of additional dimensions (e.g., Q factor) into the clustering space to further refine the discrimination between astrophysical signals and instrumental artifacts.
Comments & Academic Discussion
Loading comments...
Leave a Comment