An Ensemble Kalman-Particle Predictor-Corrector Filter for Non-Gaussian Data Assimilation
An Ensemble Kalman Filter (EnKF, the predictor) is used make a large change in the state, followed by a Particle Filer (PF, the corrector) which assigns importance weights to describe non-Gaussian distribution. The weights are obtained by nonparametr…
Authors: Jan M, el, Jonathan D. Beezley
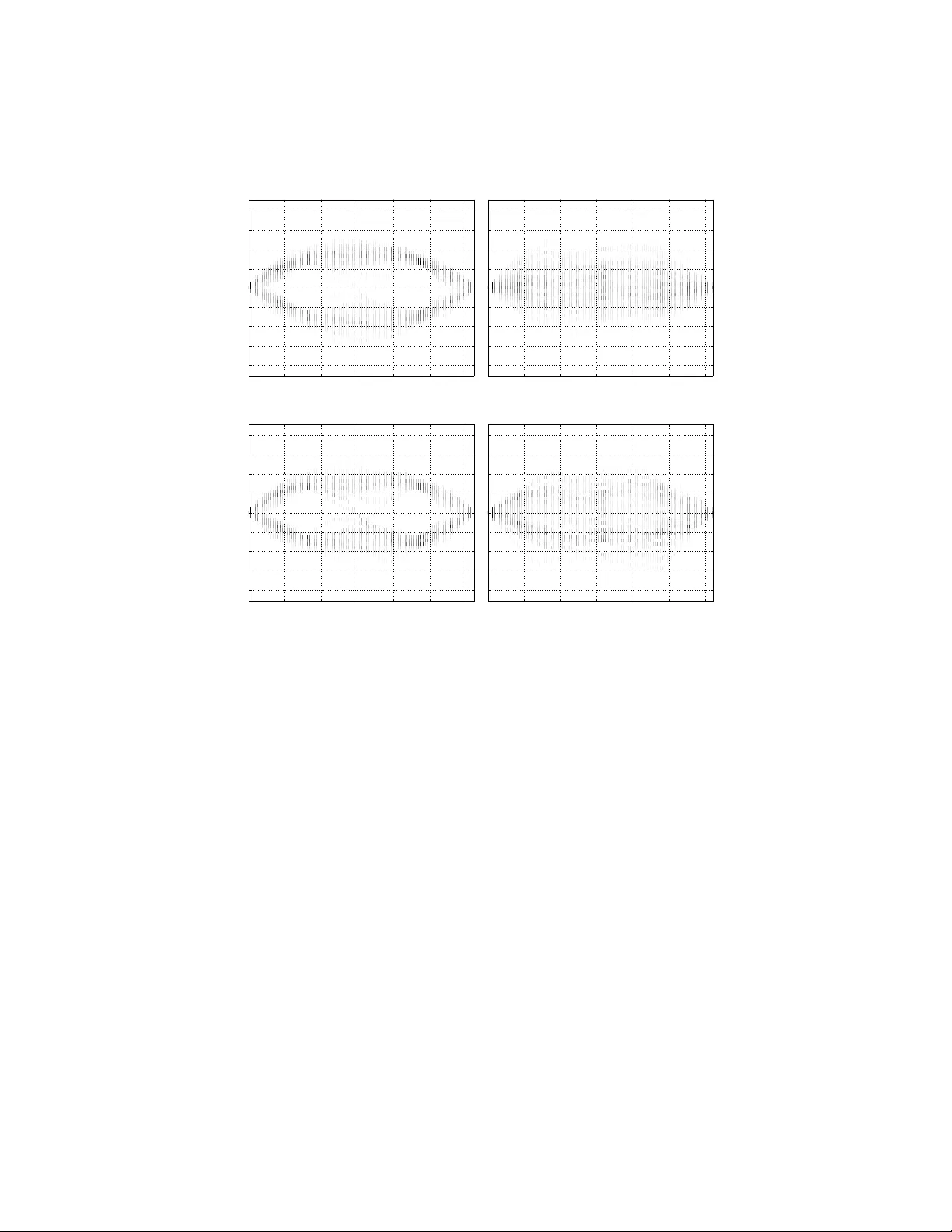
An Ensem ble Kalman-P article Predictor-Corrector Filter for Non-Gaussian Data Assimilation Jan Mandel 1 , 2 and Jonathan D. Beezley 1 , 2 1 Univ ersity of Colorado Denv er, Denv er, CO 80217-3364, USA { jon.beezley.math,jan.mandel } @gmail.com 2 National Center for A tmospheric Research, Boulder, CO 80307-3000, USA Abstract. An Ensemble Kalman Filter (EnKF, the predictor) is used mak e a large c hange in the state, follow ed b y a Particle Filer (PF, the corrector), which assigns importance w eights to describe a non-Gaussian distribution. The imp ortance weigh ts are obtained b y nonparametric densit y estimation. It is demonstrated on several n umerical examples that the new predictor-corrector filter com bines the adv an tages of the EnKF and the PF and that it is suitable for high dimensional states whic h are discretizations of solutions of partial differential equations. Key w ords: Dynamic data driv en application systems, data assimi- lation, ensem ble Kalman filter, particle filter, trac king, non-parametric densit y estimation, Bay esian statistics 1 In tro duction Dynamic Data Driven Application Systems (DDDAS) [1] aim to integrate data acquisition, modeling, and measuremen t steering in to one dynamic system. Data assimilation is a statistical technique to modify mo del state in resp onse to data and an imp ortant comp onent of the DDDAS approach. Mo dels are generally discretizations of partial differential equations and they ma y hav e easily millions of degrees of freedom. The mo del equations themselves are p osed in functional spaces, which are infinitely dimensional. Because of nonlinearities, the probabil- it y distribution of the state is usually non-Gaussian. A num ber of metho ds for data assimilation exist [2]. Filters attempt to find the b est estimate from the mo del state and the data up to the presen t. W e presen t a com bination of the Ensem ble Kalman Filter (EnKF) [3] and the Se- quen tial Imp ortal Sampling (SIS) particle filter (PF) [4]. The EnKF is a Monte- Carlo implemen tation of the Kalman Filter (KF). The KF is an exact method for Gaussian distributions. How ev er, it needs to main tain the state co v ariance matrix, whic h is not p ossible for large state dimension. The EnKF and its v ari- an ts [6, 7] replace the co v ariance b y the sample cov ariance computed from an ensem ble of sim ulations. Each ensemble member is adv anced in time b y the mo del indep enden tly until analysis time, when the data is injected, resulting in c hanges in the states of the ensemble members. Particle filters also evolv e a ensem ble of simulations, but they assign to each ensem ble member a weigh t and the analysis step up dates the weigh ts. The KF and the EnKF represen t the probability distributions b y the mean and the cov ariance, and so they assume that the distributions are Gaussian. This shows in the tendency of EnKF to smear distributions to wards unimo dal, as illustrated in Sec. 3 b elow. So, while the EnKF has the adv an tage that it can make large charges in the state and the ensemble can represent an arbitrary distribution, the EnKF is still essen tialy limited to Gaussian distributions. On the other hand, the PF can represen t non-Gaussian distributions faithfully , but it only updates the w eights and cannot mov e ensemble members in the state space. Th us a metho d that combines the adv antages of both without the disadv antages of either is of in terest. The design of more efficient non-Gaussian filters for large- scale problems has b een the sub ject of significant interest, often using Gaussian mixtures and related approac hes [8]. The predictor-corrector filter presen ted here uses an EnKF as a predictor to mo ve the state distribution tow ards the correct region and then a PF as corrector to adjust for a non-Gaussian character of the distribution. Nonparametric densit y estimation is used to compute the w eigh ts in the PF. The combined predictor- corrector metho d app ears to work w ell on problems where either EnKF of PF fails, and it do es not degrade the p erformace of the EnKF for Gaussian distribu- tions. Predictor-corrector filters were first formulated in [9, 10]. Related results and some probabilistic bac kground can b e found in [11]. 2 F orm ulation of the Metho d A common pro cedure to construct an initial ensemble is as a sum with random co efficien ts [12], u = m X n =1 λ n d n ϕ n , d n ∼ N (0 , 1) , { d n } indep enden t , (1) where { ϕ n } is an orthonormal basis in the space state V = R m equipp ed with the Euclidean norm k·k . The elemen ts of V are column vectors of v alues of functions on a mesh in the spatial domain. The basis functions ϕ n are smo oth for small n and more oscillatory for large n . If the the co efficients λ n → 0 sufficiently fast, the series (1) conv erges and u is a random smo oth function in the limit as m → ∞ . The sum (1) defines a Gaussian random v ariable with the eigenv alues of its cov ariance matrix equal to λ 2 k . Possible choices of { ϕ k } include a F ourier basis, such as the sine or cosine functions, or bred vectors [2]. On the state space V , we define another norm by k u k 2 U = m X n =1 1 κ 2 n c 2 n , u = m X n =1 c n ϕ n . (2) Note that if κ n = 1, k·k U is just the original norm k·k on V . W e generally use κ n adapted to the smo othness of the functions in the initial ensem ble, λ n /κ n → 0 as n → ∞ . A weigh ted ensemble of N simulations ( u k , w k ) N k =1 is initialized according to (1), with equal w eights w k = 1 / N . The ensemble mem b ers are adv anced b y the mo del and at giv en p oin ts in time, new data is injected by an analysis step . The data consists of vector d of measuremen ts, observ ation function h ( u ) = H u , also called forw ard op erator, here assumed to be linear, which links the mo del state space with the data s pace, and data error distribution, here assumed to b e Gaussian with zero mean and known cov ariance R . The v alue of the observ ation function H u is what the data vector would b e in the absence of model and data errors. The v alue of the probability density of the data error distribution at the data vector d for a given v alue of the observ ation function H u is called data likeliho o d and denoted by p ( d | u ). The probabilit y distribution of the mo del state b efore the data is injected is called the prior or the for e c ast , and the distribution after the data is injected is called the p osterior or the analysis . Assuming the forecast probabilit y distribution has the density p f , the densit y p a of the analysis is found from the Ba yes theorem, p a ( u ) ∝ p ( d | u ) p f ( u ) , (3) where ∝ means prop ortional. Instead of w orking with densities, the probabilit y distributions are appro xi- mated by w eighted ensembles. W e will call the following analysis step algorithm EnKF-SIS . Predictor. Giv en a forecast ensemble u f k , w f k N k =1 , w f k ≥ 0 , N X k =1 w f k = 1 , the mem b ers u a k of the analysis ensem ble are found from the EnKF, u a k = u f k + K ( d k − H u f k ) , d k ∼ N ( d, R ) , K = QH T H QH T + R − 1 where d k are randomly sampled from the data distribution, and Q is the forecast ensem ble cov ariance, Q = N X k =1 w k u k − u f u k − u f T , u f = N X k =1 w f k u f k . (4) This is the EnKF from [3], extended to w eighted ensembles by the use of the w eighted sample cov ariance (4). Corrector. The analysis mem b ers u a k are thought of as a sample from some pr op osal distribution , with density p p . Ideally , the analysis weigh ts w a k should b e computed from the SIS up date as [4] w a k ∝ p ( d | u a k ) p f ( u a k ) p p ( u a k ) . − 3 − 2 − 1 0 1 2 3 0 0.2 0.4 0.6 0.8 1 1.2 1.4 Prior Likelihood − 2 − 1. 5 − 1 − 0 . 5 0 0 . 5 1 1. 5 2 0 0.2 0.4 0.6 0.8 1 1.2 1.4 ENKF Exact Estimated posterior (a) Prior and data lik eliho o d densities (b) Posterior from EnKF − 2 − 1. 5 − 1 − 0 . 5 0 0 . 5 1 1. 5 2 0 0.2 0.4 0.6 0.8 1 1.2 1.4 SIS Exact Estimated posterior − 2 − 1. 5 − 1 − 0 . 5 0 0 . 5 1 1. 5 2 0 0.5 1 1.5 ENKF+SIS Exact Estimated posterior (c) Posterior from SIS (d) Posterior from EnKF-SIS Fig. 1. Data assimilation with bimo dal prior. EnKF fails to capture the non-Gaussian features of the p osterior, but b oth SIS and EnKF-SIS represent the nature of the p osterior reasonably well. Ho wev er, the ratio of the densities is not kno wn, so it is replaced by a nopara- metric estimate inspired b y [13], giving w a k ∝ p ( d | u a k ) P ` : k u f ` − u a k k U ≤ h k w f k P ` : k u a ` − u a k k U ≤ h k 1 N , N X k =1 w a k = 1 . The bandwidth h k is the distance from u a k to the b N 1 / 2 c -th nearest member u a ` , measured in the k·k U norm. 3 Numerical Results Fig. 1 demonstrates a failure of EnKF for non-Gaussian distributions, while SIS and EnKF-SIS do fine. W e construct a bimodal prior in 1D by first sampling from N (0 , 5) and assigning the weigh ts by w f ( x i ) = e − 5(1 . 5 − x i ) 2 + e − 5( − 1 . 5 − x i ) 2 . 0 1 2 3 4 5 6 7 − 1.5 − 1 − 0.5 0 0.5 1 1.5 time u SIS ENKF ENKF+SIS Optimal Data Fig. 2. Ensem ble filters mean and optimal filter mean for sto chastic ODE (5). EnKF- SIS was able to appro ximate the optimal solution b etter than either SIS or EnKF alone. The data lik eliho o d is Gaussian. The ensemble size w as N = 100. The next 1D problem demonstrates that EnKF-SIS is doing b etter that either EnKF or SIS alone in filtering for the sto chastic differential equation [14] du dt = 4 u − 4 u 3 + κη , (5) where η ( t ) is white noise. The parameter κ controls the magnitude of the sto chas- tic term. The deterministic part of this differen tial equation is of the form du dt = − f 0 ( u ) , where the p otential f ( u ) = − 2 u 2 + u 4 . The equilibria are given b y f 0 ( u ) = 0; there are t wo stable equilibria at u = ± 1 and an unstable equilibrium at u = 0. The sto chastic term of the differen tial equation makes it p ossible for the state to flip from one stable equilibrium p oint to another; how ever, a sufficiently small κ insures that suc h an even t is rare. A suitable test for an ensem ble filter will b e to determine if it can prop erly trac k the mo del as it transitions from one stable fixed point to the other. F rom Fig. 1, it is clear that EnKF will not be capable of describing the bimo dal nature of the state distribution so it will not p erform well when tracking the transition. Also, when the ensemble is centered around one stable p oint, it is unlik ely that some ensemble members would b e close to the other stable p oint. It is kno wn that SIS can be v ery slo w in tracking the transition and EnKF can do better [14]. Fig. 2 demonstrates that EnKF can outp erform b oth. The solution u of (5) is a random v ariable dependent on time, with densit y p ( t, u ). The evolution of the density in time is given by the F okker-Planc k equa- tion, which was solv ed n umerically on a uniform mesh from u = − 3 to u = 3 with the step ∆u = 0 . 01. A t the analysis time, the optimal p osterior densit y w as computed by multiplying the probability densit y of u by the data likelihoo d follo wing (3) and then scaling so that again R pdu = 1, using numerical quadra- ture by the trapezoidal rule. The data p oints were tak en from one solution of this mo del, called a reference solution, whic h exhibits a switch at time t ≈ 1 . 3. The data error distribution was normal with the v ariance tak en to b e 0 . 1 at eac h p oint. T o adv ance the ensemble mem b ers and the reference solution, we ha ve solv ed (5) b y the explicit Euler metho d with a random perturbation from N (0 , ( ∆t ) 1 / 2 ) added to the right hand side in every step [16]. The simulation w as run for each method with ensemble size 100, and assimilation p erformed for eac h data p oint. Finally , typical results for filtering in the space of functions on [0 , π ] of the form u = d X n =1 c n sin ( nx ) (6) are in Figs. 3 and 4. The ensemble size w as N = 100 and the dimension of the state space w as d = 500. The F ourier coefficients were chosen λ n = n − 3 to generate the initial ensemble from (1), and κ n = n − 2 for the norm in the density estimation. Fig. 3 again sho ws that EnKF cannot handle bimo dal distribution. The prior w as constructed by assimilating the data likelihoo d p ( d | u ) = 1 / 2 if u ( π / 4) and u (3 π / 4) ∈ ( − 2 , − 1) ∪ (1 , 2) 0 otherwise in to a large initial ensemble (size 50000) and resampling to the obtain the forecast ensem ble size N = 100 with a non-Gaussian density . Then the data lik eliho o d u ( π / 2) − 0 . 1 ∼ N (0 , 1) was assimilated to obtain the analysis ensemble. Fig. 4 shows a failure of SIS. The prior ensem ble sampled from Gaussian distribution with co efficients λ n = n − 3 using (1) and (6), and the data likelihoo d w as u ( π / 2) − 7 ∼ N (0 , 1). 4 Conclusion W e hav e demonstrated the p otential of a predictor-corrector filter to p erform a successful Bay esian up date in the presence of non-Gaussian distributions, large n umber of degrees of freedom, and large change of the state distribution. Open questions include con vergence of the filter in high dimension when applied to m ultiple updates ov er time, mathematical conv ergence pro ofs for the densit y estimation and for the Bay esian up date, and p erformance of the filters when applied to systems with a large n umber of different physical v ariables and mo des, as is common in atmospheric mo dels. Prior Ensemble 0 . 5 1 1. 5 2 2. 5 3 − 8 − 6 − 4 − 2 0 2 4 6 8 Posterior: EnKF 0 . 5 1 1. 5 2 2. 5 3 − 8 − 6 − 4 − 2 0 2 4 6 8 (a) (b) Posterior: SIS 0 . 5 1 1. 5 2 2. 5 3 − 8 − 6 − 4 − 2 0 2 4 6 8 Posterior: EnKF − SIS 0 . 5 1 1. 5 2 2. 5 3 − 8 − 6 − 4 − 2 0 2 4 6 8 (c) (d) Fig. 3. EnKF smears non-Gaussian distribution. The horizontal axis is the spatial co- ordinate x ∈ [0 , π ]. The vertical axis is the v alue of function u . The level of shading on eac h vertical line is the marginal density of u at a fixed x , computed from a histogram with 50 bins. While EnKF completely ignores the non-Gaussian c haracter of the p os- terior and centers the distribution around u = 0, EnKF-SIS shows darker bands at the edges. Ac knowledgemen ts. This w ork w as supported b y the National Science F oundation under grants CNS- 0719641, A TM-0835579, and CNS-0821794. References 1. Darema, F.: Dynamic data driven applications systems: A new paradigm for ap- plication simulations and measurements. In: Bubak, M., v an Albada, G.D., Slo ot, P .M.A., Dongarra, J.J. (eds.) ICCS 2004, LNCS, vol. 3038, pp. 662–669. Springer (2004) 2. Kalna y , E.: A tmospheric Mo deling, Data Assimilation and Predictability . Cam- bridge Universit y Press (2003) Prior Ensemble 0 . 5 1 1. 5 2 2. 5 3 − 8 − 6 − 4 − 2 0 2 4 6 8 Posterior: EnKF 0 . 5 1 1. 5 2 2. 5 3 − 8 − 6 − 4 − 2 0 2 4 6 8 (a) (b) Posterior: SIS 0 . 5 1 1. 5 2 2. 5 3 − 8 − 6 − 4 − 2 0 2 4 6 8 Posterior: EnKF − SIS 0 . 5 1 1. 5 2 2. 5 3 − 8 − 6 − 4 − 2 0 2 4 6 8 (c) (d) Fig. 4. SIS cannot mak e a large up date. The horizontal axis is the spatial coordinate x ∈ [0 , π ]. The vertical axis is the v alue of function u . The level of shading on each v ertical line is the marginal density of u at a fixed x , computed from a histogram with 50 bins. While EnKF and EnKF-SIS create ensembles that are attracted to the data v alue u ( π / 2) = 7, SIS cannot reach so far because there are no such mem b ers in this relativ ely small ensemble of size N = 100. 3. Burgers, G., v an Leeuw en, P .J., and Evensen, G.: Analysis scheme in the ensemble Kalman filter. Mon thly W eather Rev. 126 (1998) 1719–1724 4. Doucet, A., de F reitas, N., Gordon, N. (eds.) Sequential Monte Carlo in Practice. Springer (2001) 5. Ev ensen, G.: The ensem ble Kalman filter: Theoretical formulation and practical implemen tation. Ocean Dynamics 53 (2003) 343–367 6. Anderson, J.L.: An ensemble adjustment Kalman filter for data assimilation. Mon thly W eather Rev. 129 (1999) 2884–2903 7. Mitc hell, H.L., Houtek amer, P .L.: An adaptive ensemble Kalman filter. Mon thly W eather Rev. 128 (2000) 416–433 8. Bengtsson, T., Snyder, C., Nychk a, D.: T ow ard a nonlinear ensemble filter for high dimensional systems. J. of Geophysical Research - Atmospheres 108(D24) (2003) STS 2–1–10 9. Mandel, J., Beezley , J.D.: Predictor-corrector ensemble filters for the assimilation of sparse data into high dimensional nonlinear systems. CCM Rep ort 232, Universit y of Colorado Denv er (2006) 10. Mandel, J., Beezley , J.D.: Predictor-corrector and morphing ensem ble filters for the assimilation of sparse data into high dimensional nonlinear systems. In: 11th Symp osium on In tegrated Observing and Assimilation Systems for the Atmosphere, Oceans, and Land Surface (IOAS-A OLS), CD-ROM, P ap er 4.12, 87th American Meteorological Society Annual Meeting, San Antonio, TX, h ttp://ams.confex.com/ams/87ANNUAL/techprogram/paper 119633.htm (2007) 11. Mandel, J., Beezley , J.D.: Predictor-corrector ensemble filters for data assimilation in to high-dimensional nonlinear systems. In preparation (2009). 12. Ev ensen, G.: Sequen tial data assimilation with nonlinear quasi-geostrophic mo del using Monte Carlo metho ds to forecast error statistics. J. of Geophysical Research 99 (C5) (1994) 143–162 13. Loftsgaarden, D.O., Quesen b erry , C.P .: A nonparametric estimate of a multiv ariate densit y function. Ann. Math. Stat. 36 (1965) 1049–1051 14. Kim, S., Eyink, G.L., Restrep o, J.M., Alexander, F.J., Johnson, G.: Ensem ble filtering for nonlinear dynamics. Monthly W eather Rev. 131 (2003) 2586–2594 15. Miller, R.N., Carter, E.F., Blue, S.T.: Data assimilation into nonlinear sto chastic mo dels. T ellus 51A (1999) 167–194 16. Higham, D.J.: An algorithmic in tro duction to numerical sim ulation of stochastic differen tial equations. SIAM Rev. 43 (2001) 525–546
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment