Thoughts on new statistical procedures for age-period-cohort analyses
Age-period-cohort analysis is mathematically intractable because of fundamental nonidentifiability of linear trends. However, some understanding can be gained in the context of individual problems.
Authors: Andrew Gelman
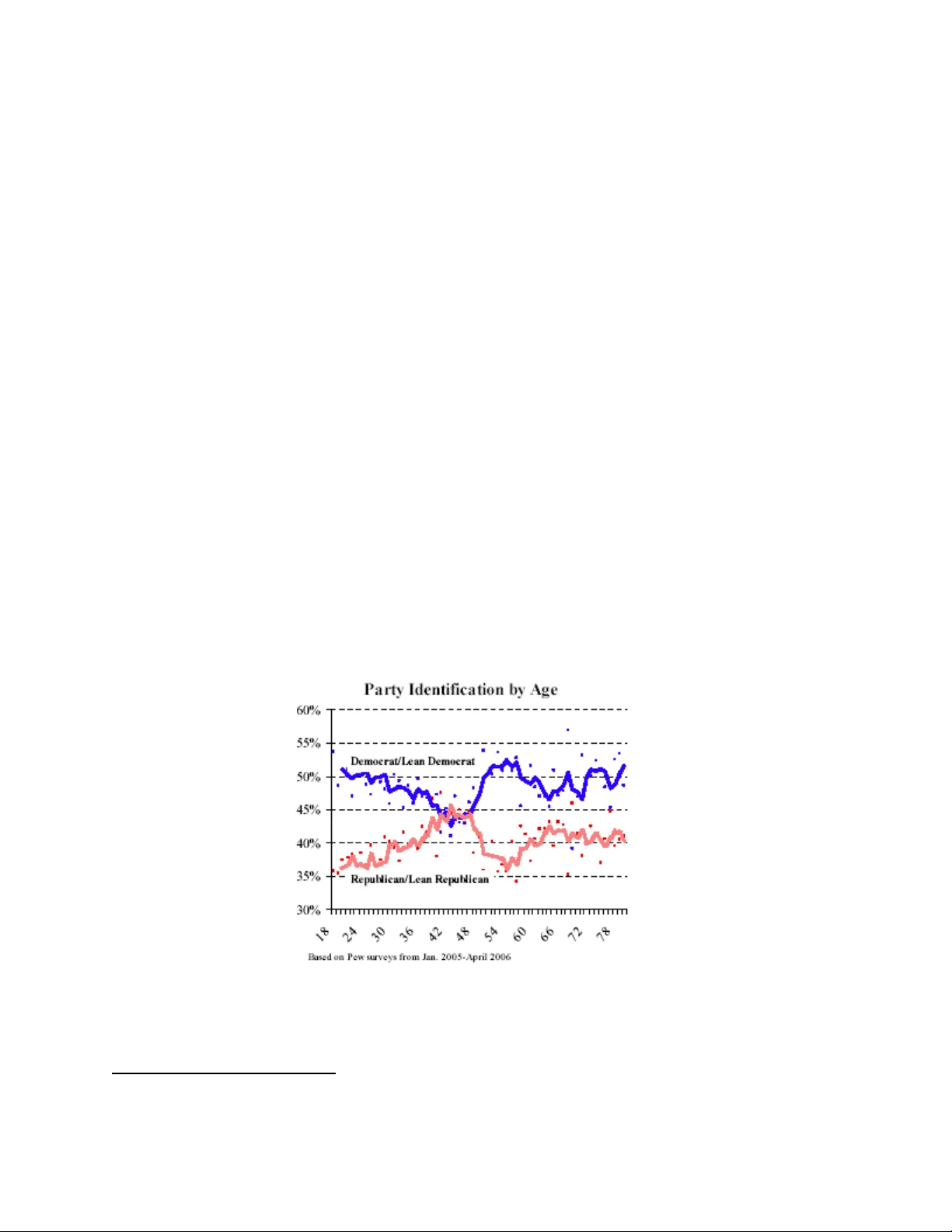
Thoughts on new statistical procedures for age-period-cohort analyses 1 Andrew Gelman, Department of Statistics and Dep artment of Poli tical Science, Columbia University 14 June 2008 1. Introduction: young Dem ocrats and middle-aged Republicans I first read about the age- period-cohort problem m any years ago, but I didn’t think seriously about it until recently, when I saw some survey results showing party identification by age (see Figure 1). Americans in their forties are the most R epublican group, a pattern that I would attribute to this g roup coming of political age during the pres idencies of Jimmy Carter and Ronald Reagan. Older Americans mig ht be more likely to associate the Republica ns with Richard Nixon and Wate rgate, whereas younger voters associate the Democrats wi th Bill Clinton and the Republicans with George W . Bush. Thus can the difference in popularity of s uccessive presidents propagate into sy stematic patterns of po litical attitudes by age. But do I really have the evidence to m ake this claim? Im plicitly I am following a model in which voters lock in their party identifica tion early, perhaps between the ages of 15 and 25, and then stay with this (perhaps with small changes) throughout thei r lives. How could we test th is model? If we had longitudinal data, following up v oters for decades, we could track the stabili ty of their party identification over the years (and also try to identify th e characteristics of those who switch and those who stay ). Another approach would be to analyz e repeated cross sections: I f we were to make a graph, similar to Figure 1, but based on data from 2002, would the red and blue lines simply be shifted four years to the left, so that the party identif ication of 40-year- olds in 2006 matches that of the 36-y ear-olds in 2002? If such a pattern happened consistently ov er time, this would support the hypothesis of a cohort effect . Figure 1. Survey data show ing party identification in 2006 for different age groups, from Keeler (2006). The most Republican group is people in their mid-forties, who cam e of political age during Jimm y Carter’s and Ronald Reagan’s pres idencies. 1 Invited discu ssion for Ame rican Journa l of Socio logy of two p apers on age-period -cohort a nalyses. Another possibility that could be rev ealed by additional data is an age effect : Suppose that the equiv alent to Figure 1, constructed four or eight o r twelve years earlier, looked identical to the 2006 pattern with no age shift. Then we would be inclined to believe that party identification is associ ated with age, rather than cohort, with new voters starting out as str ong Democrats, mov ing toward the Republican Party in their middle age, and then m oving back to the Demcorats. It would not be d ifficult to construct a story consistent with this pattern (were i t to in fact appear in the data), poss ibly associated with life- course changes involving m arriage, children, and participation in the workforce. Finally, the 2006 pattern may be part of a pe riod effect . Figure 1 shows, overal l, a strong Dem ocratic advantage, but these polls were tak en during a period when the Repub licans have been on the defensive. Did the Democrats have such an adv antage five or ten years ago? May be not. In this particular exam ple, we are less interested in period effects—our p rimary goal here is to understand the big difference between today’s young and middle-ag ed voters—but we certainly hav e to be aware of the possibility of period effects, if only to adjust for them in estimating age and cohort effects. 2. The difficulty of age- period-cohort analyses Given this background, I was excited to have t he opportunity to discuss this article on age- period-cohort analysis. I spoke with a colleague and fo rmulated the following plan: I would send him a file with National Election Study data on party id entification and age in each elect ion year from 1948 through 2004, and he would then perfo rm the following steps: 1. Create graphs of party ident ification vs. age for each year, following th e pattern of Figure 1. 2. Fit the model described in the paper under dis cussion and see if the estim ates make sense. 3. Play around with adding lin ear trends to the age, period, and co hort effects to get equivalent estimates that are equally consistent with the data. The idea was to use the part y identification problem as an appli ed test case for the new estim ator. My further plan, after successful com pletion of the three steps abov e, was to review the literature on p arty identification by age and to underst and our results in light of this literature and any av ailable longi tudinal surveys. Unfortunately, for personal reasons my colleague was not able to carry out the above plan, nor did I have the time to do it myself. I hav e thus illustrated one of the k ey difficulties with age- period-cohort effects, which is the practical effort required to put together a dataset and fit a model. The tasks are not hug ely complicated but neither are they as simple and codified as running a regression analysis. In this case, the bottom line is that my comments on the proposed new m ethod will be restricted to the theoreti cal, and I will postpone my eng agement with the age and voting li terature to a later date (at which point, perhap s, young people will be voting Republican again). 3. Conclusions The discussants of the paper at hand correctly note that there can be no g eneral solution to the age- period- cohort problem: as has been noted by Fienb erg and Mason (1979), Holford (1983 ), and many others, the likelihood function has a ridg e that no amount of analy tical manipulation can evade. For any dataset, there is a space of possible estim ates, all equally consistent with th e data, but with different linear trends in age, period, and cohort, a nd no way from the data alone to choose am ong these. On the other hand, some of the estim ates seem to mak e more sense than others. For exam ple, consider a model which adds the following three trends: (i) since 1948, an increase of 1 % per year in the overall probability of Democratic i dentification, (ii) starting at ag e 18, an increase of 1% per year in the probability of an individual being a Republ ican as he or she gets older, and (i ii) for each cohort, a inc rease of 1% in the probability of being Repub lican, compared to the cohort that was bo rn one year earlier. Add these three trends together and you g et zero—the combination has no effect on an y observable data—but they do not mak e much political sense. What does it really m ean to talk about a linear time trend toward the Democrats if it is exactly canceled by each cohort being m ore Republican than the last? To put it another way, some m ethods of constraining the possible space of sol utions seem more reasonable than others. I n the party identification exam ple, it might make sense to assume a zero overal l trend in period effects, or ev en a very slight trend toward the Republicans; this wo uld make m ore sense than imposing a zero overall t rend in age effects, or imposing som e sort of arbitrary constraint on some endpoints, of the sort that is sometimes done to impose identifi ability. For these reasons, I am open to persuasion that a method su ch as presented in the paper under discussion can be of practical use. My preference would be for so mething slightly more general—a fram ework for imposing sensible constra ints, rather than a single automatic p rocedure—but I suspect that it is through exam ples that we will see if the method provides real benef its beyond existing approaches. I conclude with a comm ent about possible Bayesian extensions. In classical l ikelihood inference, reparameterization has no e ffect and is merely a matter of convenience—in this case, dete rmining a particular preferred solutio n to the model. In Bay esian inference, however, a chang e of parameters can change the model if the form of the prior distribution is fixed (Gelm an, 2004). In practice, prior distributions and likelihood s are chosen for mathematical convenience. F or example, it is standa rd to assume independence of pa rameters in the prior distribution, and thu s a transformation that ro tates parameter space can change posterio r inferences. For that reason, I am not completely skeptical of the potential for new methods that can he lp us analyze age- period-cohort phenomena. Acknowledgments I thank Andy Abbott for inv iting this article and the National Science Found ation, National Institutes of Health, and Columbia Univ ersity Applied Statistics Center for financial suppo rt. Additional references Gelman, A. (2004). Param eterization and Bayesian model ing. Journal of the American S tatistical Association 99, 537-545. Keeler, Scott (2006). Politi cs and the “DotNet” generation. Pew Res earch Center, 30 May. http://pewresearch.org/pubs/27/politics- and-the- dotnet-generation
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment