Reconfiguration of Distributed Information Fusion System ? A case study
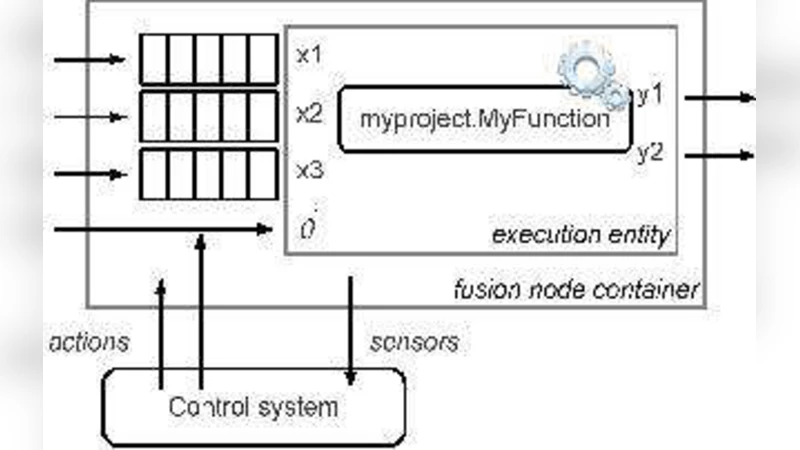
Information Fusion Systems are now widely used in different fusion contexts, like scientific processing, sensor networks, video and image processing. One of the current trends in this area is to cope with distributed systems. In this context, we have defined and implemented a Dynamic Distributed Information Fusion System runtime model. It allows us to cope with dynamic execution supports while trying to maintain the functionalities of a given Dynamic Distributed Information Fusion System. The paper presents our system, the reconfiguration problems we are faced with and our solutions.
💡 Research Summary
The paper addresses the growing need for information fusion systems (IFS) to operate reliably in highly dynamic and distributed environments such as scientific data pipelines, sensor networks, and real‑time video processing. Traditional IFS architectures are typically static: fusion operators are pre‑placed on fixed hardware, and the data flow graph is defined at design time. This rigidity makes them vulnerable to node failures, network topology changes, and sudden workload spikes, which are common in modern deployments.
To overcome these limitations, the authors propose a Dynamic Distributed Information Fusion System (DDIFS) runtime model. The model is built around three abstractions: (1) Fusion Nodes, which encapsulate physical or virtual compute resources and expose their current health, capacity, and connectivity; (2) Fusion Operators, which represent individual fusion algorithms (e.g., Kalman filters, Bayesian estimators, deep‑learning detectors) and expose input/output ports; and (3) Execution Contexts, which maintain the mapping between operators and nodes and can be re‑configured at runtime.
Reconfiguration is triggered by three classes of events: (i) Fault Recovery, when a node or operator crashes; (ii) Network Re‑routing, when link failures or latency spikes degrade the existing data paths; and (iii) Load Adaptation, when the incoming data rate exceeds the current processing capacity. For fault recovery, the system maintains a pool of standby nodes. Upon detection of a failure, a State Transfer Protocol copies the operator’s internal state to a selected standby node, while a Consistency Guard ensures that no intermediate results are lost. Network re‑routing recomputes the data‑flow graph using a cost‑aware path‑selection algorithm, guaranteeing minimal additional latency. Load adaptation dynamically clones operators or scales them out across multiple nodes; the decision is driven by a Cost Model that balances computational cost, communication overhead, and recovery time.
The implementation is realized on top of the Robot Operating System (ROS) middleware, with each Fusion Node deployed as a Docker container for portability. Real‑time monitoring agents collect metrics such as CPU load, memory usage, bandwidth, and processing latency. A central Reconfiguration Manager consumes these metrics, evaluates the cost model, and issues reconfiguration commands.
A two‑scenario case study validates the approach. In the first scenario, a large‑scale environmental monitoring network comprising thousands of temperature and humidity sensors experiences intermittent power‑related node failures. The DDIFS automatically reallocates the affected fusion operators to healthy standby nodes, achieving an average recovery time of 2.3 seconds and preserving continuous fused outputs. In the second scenario, a multi‑camera video analytics pipeline faces a sudden surge in frame rate due to an event (e.g., a crowd gathering). The system detects the overload, clones the object‑detection operators, and distributes the workload across additional nodes, limiting the increase in frame‑processing latency to less than 12 % and boosting throughput by roughly 1.8×.
Experimental results demonstrate that the proposed runtime model maintains high availability, low latency, and scalability under realistic fault and load conditions. The authors conclude that DDIFS provides a practical foundation for building resilient, self‑adapting information fusion applications. Future work will explore predictive reconfiguration using machine‑learning models, deeper integration of heterogeneous resources (edge, fog, cloud), and multi‑level orchestration strategies to further enhance robustness and performance.
Comments & Academic Discussion
Loading comments...
Leave a Comment