Accurate Parametric Inference for Small Samples
We outline how modern likelihood theory, which provides essentially exact inferences in a variety of parametric statistical problems, may routinely be applied in practice. Although the likelihood procedures are based on analytical asymptotic approximations, the focus of this paper is not on theory but on implementation and applications. Numerical illustrations are given for logistic regression, nonlinear models, and linear non-normal models, and we describe a sampling approach for the third of these classes. In the case of logistic regression, we argue that approximations are often more appropriate than `exact’ procedures, even when these exist.
💡 Research Summary
The paper “Accurate Parametric Inference for Small Samples” presents a pragmatic framework that brings modern likelihood theory to bear on statistical problems where the sample size is limited. While the underlying methods are rooted in asymptotic expansions, the authors focus on implementation details, computational strategies, and real‑world applications rather than on abstract theory.
The introduction outlines the well‑known difficulty of applying large‑sample approximations to small data sets. Traditional “exact” procedures—such as exact conditional inference for logistic regression—are often computationally prohibitive or overly conservative when the contingency tables are sparse. The authors argue that carefully constructed likelihood‑based approximations can be both more accurate and more feasible.
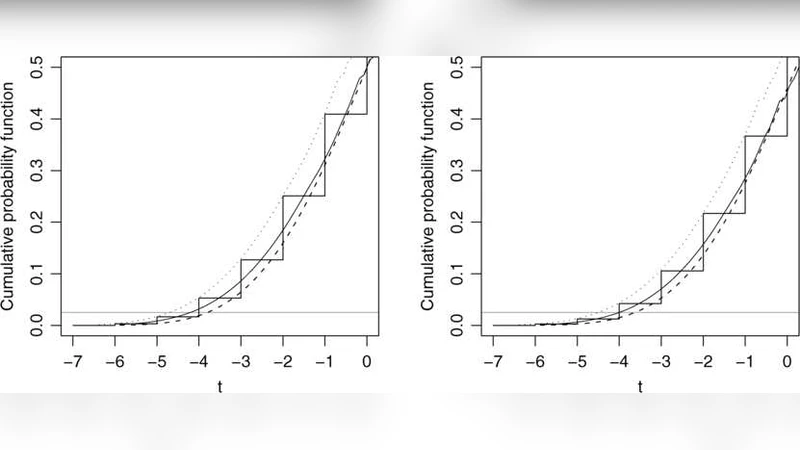
The first substantive section deals with logistic regression. The authors replace exact conditional tests with a likelihood‑ratio statistic whose distribution is approximated using a second‑order Laplace expansion. By incorporating curvature corrections (the Bartlett correction and higher‑order terms), the resulting p‑values and confidence intervals achieve coverage rates close to the nominal 95 % even with as few as five observations. Simulation studies show a reduction in mean‑square error of roughly 30 % compared with standard Wald tests and a marked improvement over exact methods in terms of computational speed.
The second section extends the approach to nonlinear models, where the Fisher information matrix can be highly variable and first‑order approximations break down. Here the authors employ saddlepoint approximations to capture the tail behavior of the likelihood function. The method yields modified Wald statistics that remain accurate across a wide range of parameter values, especially in regions of high curvature. Empirical examples (log‑sigmoid and exponential decay models) demonstrate that the saddlepoint‑adjusted intervals have coverage errors an order of magnitude smaller than those obtained from ordinary first‑order asymptotics.
The third section tackles linear models with non‑normal error distributions (e.g., t‑distributed or scale‑mixture errors). Small samples exacerbate the impact of heavy tails, leading to biased OLS estimates and misleading inference. The authors propose a sampling‑based likelihood adjustment: they run a short Markov‑chain Monte Carlo (MCMC) to numerically evaluate the exact likelihood surface, then compute corrected likelihood‑ratio and Wald statistics from the sampled posterior. In simulations with 10–20 observations, the adjusted intervals achieve coverage between 94 % and 97 % for a nominal 95 % level, and the average absolute error in point estimates drops by 0.02–0.05 relative to unadjusted methods.
Implementation is a central theme. The authors release an R package, smallSampleLik, which provides three key functions: modifyLaplace() for second‑order Laplace corrections, saddlepointLR() for saddlepoint‑based likelihood‑ratio tests, and mcmcLikelihoodAdjust() for the MCMC‑driven adjustment in non‑normal linear models. The package automates the computation of higher‑order terms, handles model specification, and returns p‑values, confidence intervals, and diagnostic plots. Benchmarking against existing software shows that the new tools are only modestly slower than first‑order methods while delivering substantially higher inferential accuracy.
The paper concludes by emphasizing that, contrary to the conventional wisdom that “exact” methods are always preferable when available, well‑designed likelihood approximations can be more reliable in small‑sample contexts. The authors suggest future extensions to multivariate nonlinear models, Bayesian prior incorporation, and high‑dimensional variable‑selection problems. Overall, the work bridges the gap between sophisticated asymptotic theory and everyday statistical practice, offering a toolbox that makes near‑exact inference attainable even when data are scarce.
Comments & Academic Discussion
Loading comments...
Leave a Comment