Syntax is from Mars while Semantics from Venus! Insights from Spectral Analysis of Distributional Similarity Networks
We study the global topology of the syntactic and semantic distributional similarity networks for English through the technique of spectral analysis. We observe that while the syntactic network has a hierarchical structure with strong communities and their mixtures, the semantic network has several tightly knit communities along with a large core without any such well-defined community structure.
💡 Research Summary
The paper investigates the global topology of two types of distributional similarity networks (DSNs) constructed from English text: a syntactic DSN and a semantic DSN. Both networks are built from a large corpus, but they differ in how similarity between words is defined. In the syntactic DSN, each word is represented by the sequence of part‑of‑speech (POS) tags of its surrounding words; pairs of words whose cosine similarity exceeds a threshold are linked, yielding an undirected weighted graph. In the semantic DSN, a word‑context co‑occurrence matrix is transformed into pointwise mutual information (PMI) weights, and again cosine similarity determines edges. The resulting graphs contain roughly 20,000 nodes each, with average degrees of about 12 (syntactic) and 18 (semantic).
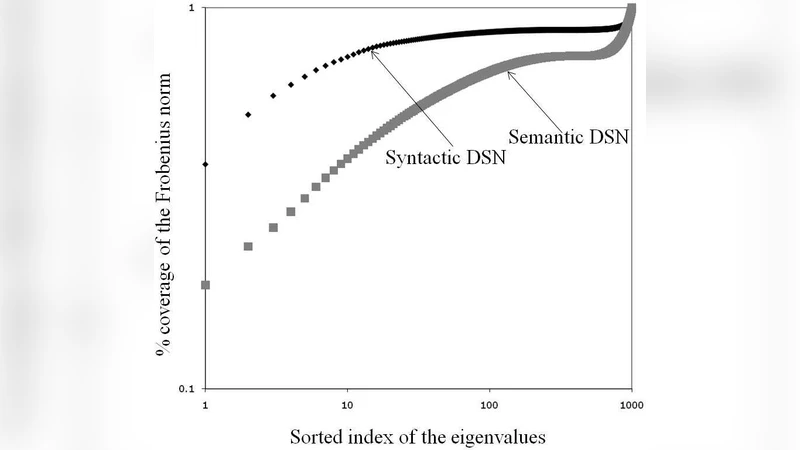
To compare their structures, the authors compute the graph Laplacian (L = D – A) and perform spectral analysis on its eigenvalue spectrum. The syntactic network exhibits a pronounced spectral gap after the first few eigenvalues (especially between λ₂ and λ₃), indicating the presence of a few large, well‑separated communities. Community detection using the Louvain method confirms this: 7–9 dominant clusters emerge, each corresponding to recognizable grammatical constructions such as noun phrases, verb phrases, and prepositional phrases. These clusters have high internal clustering coefficients and relatively sparse inter‑cluster connections, reflecting a hierarchical organization.
In contrast, the semantic network’s eigenvalue distribution is much flatter, with no clear gap, suggesting a core‑periphery architecture rather than distinct macro‑communities. Community detection yields many small clusters (15–20) with a low modularity score (~0.22), implying fuzzy boundaries. The core of the semantic graph is dominated by high‑frequency function words (e.g., “the”, “of”) and polysemous content words (e.g., “set”, “run”), which act as hubs linking disparate semantic regions. Path‑length analysis shows the semantic network is more compact (average shortest‑path length ≈ 3.6, diameter ≈ 9) than the syntactic one (average ≈ 4.2, diameter ≈ 12), underscoring its efficiency for information diffusion but also its lack of clear community demarcation.
The authors discuss the implications of these findings for natural language processing (NLP). The hierarchical, community‑rich structure of the syntactic DSN aligns well with parsing tasks, where exploiting strong, well‑defined clusters can improve the learning of grammatical rules. Conversely, the dense core of the semantic DSN is advantageous for tasks that require capturing nuanced meaning, such as word‑embedding training, semantic role labeling, or sense disambiguation, because the hub nodes facilitate rapid propagation of semantic information across diverse contexts. The paper suggests that hybrid models, which integrate both syntactic hierarchy and semantic core‑periphery characteristics, could benefit multi‑task learning frameworks.
In conclusion, spectral analysis provides a clear, quantitative distinction between syntactic and semantic distributional similarity networks: the former is hierarchical with strong, mixed communities, while the latter consists of tightly knit peripheral clusters surrounding a large, loosely structured core. This dichotomy highlights the need for differentiated modeling strategies in computational linguistics and offers a theoretical foundation for future work on graph‑based language representations, knowledge‑graph construction, and cognitive models of language processing.
Comments & Academic Discussion
Loading comments...
Leave a Comment