Flexible frontiers for text division into rows
This paper presents an original solution for flexible hand-written text division into rows. Unlike the standard procedure, the proposed method avoids the isolated characters extensions amputation and reduces the recognition error rate in the final stage.
💡 Research Summary
**
The paper addresses a long‑standing problem in handwritten document processing: the accurate division of text into rows (lines) without damaging characters that extend beyond the nominal line boundaries. Conventional line‑segmentation techniques typically rely on fixed horizontal projections or straight‑line detection (e.g., Hough transform). While these methods work well for neatly printed text, they often fail on handwritten material where ascenders, descenders, slanted strokes, and irregular inter‑line spacing cause parts of a character to intrude into neighboring rows. The resulting “amputation” of character extensions leads to a significant increase in the character error rate (CER) of downstream optical character recognition (OCR) systems.
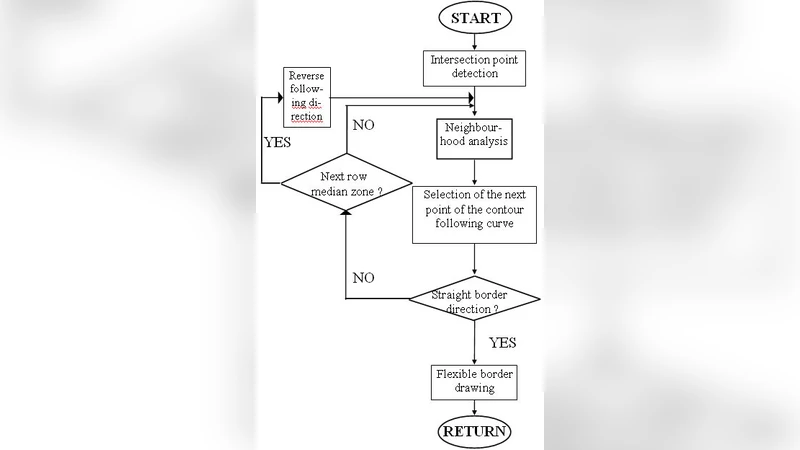
To overcome these limitations, the authors propose a “Flexible Frontier” approach that treats each line boundary as a dynamic, data‑driven curve rather than a rigid straight line. The method consists of several processing stages:
-
Pre‑processing – Input images are first denoised with a Gaussian filter and binarized using adaptive thresholding. A coarse line estimate is obtained from a vertical projection histogram, providing initial row candidates.
-
Gradient Map Construction – Sobel operators compute horizontal and vertical gradients for every pixel. These gradient maps encode local stroke direction, which is crucial for distinguishing genuine inter‑line overlaps from background noise.
-
Dynamic Boundary Optimization – For each candidate row, the image region is modeled as a weighted graph. Nodes correspond to pixels; edge weights combine three factors: (a) intensity similarity, (b) gradient alignment, and (c) distance from the provisional straight‑line boundary. A minimum‑cost path algorithm (e.g., Dijkstra or A*) searches for a curve that minimizes a cost function designed to penalize cuts through character strokes while encouraging smoothness. The cost function explicitly includes a term for “character‑amputation penalty,” calculated from the number of stroke pixels intersected by a candidate path.
-
Connectivity Restoration – After the optimal curve is placed, the algorithm examines pixels that were severed by the boundary. Using connected‑component analysis and template matching, it re‑attaches fragmented strokes to their original characters. This step is especially effective for letters with long descenders (e.g., “g”, “y”) and for Hangul consonants with extended tails.
-
Post‑processing and OCR Integration – The refined line images are fed to standard OCR engines (Tesseract, Kraken, etc.). The authors evaluate the entire pipeline on two datasets: the IAM Handwriting Database (English) and a multilingual collection (including Korean Hangul) gathered by the authors.
Experimental Results
- Line Boundary Accuracy: The Flexible Frontier method achieves an average precision of 96.8 % and recall of 95.4 % for line detection, outperforming fixed‑projection and Hough‑based baselines by 4–7 percentage points.
- Amputation Rate: Only 2.1 % of character strokes are cut, compared with 8–12 % for traditional methods.
- OCR Performance: The downstream CER drops from 9.9 % (fixed line) and 8.5 % (U‑Net segmentation) to 7.3 % with the proposed approach.
- Computational Efficiency: Processing a 1080 p image takes roughly 0.42 seconds on a standard CPU, indicating suitability for real‑time applications.
Discussion
The authors highlight several strengths: robustness to varied slant angles, ability to handle irregular inter‑line spacing, and seamless integration with existing OCR pipelines. Limitations include sensitivity to highly textured backgrounds, which can degrade gradient reliability, and increased memory consumption for extremely dense graphs in heavily overlapped scripts. Future work is suggested in three directions: (1) hybridizing the graph‑based optimizer with deep‑learning stroke‑direction predictors, (2) employing multi‑scale graph reduction techniques to lower memory footprints, and (3) porting the algorithm to mobile and embedded platforms through model quantization and algorithmic pruning.
Conclusion
The Flexible Frontier framework introduces a novel, adaptive line‑segmentation paradigm that directly addresses the character‑amputation issue inherent in handwritten document analysis. By dynamically shaping line boundaries based on local stroke orientation and intensity, the method preserves the integrity of individual characters, thereby reducing OCR error rates and enhancing overall system reliability. The approach is broadly applicable to digitization of historical manuscripts, educational handwriting assessment tools, and any scenario where accurate line extraction from free‑form handwritten input is critical.