Finding Community Structure Based on Subgraph Similarity
Community identification is a long-standing challenge in the modern network science, especially for very large scale networks containing millions of nodes. In this paper, we propose a new metric to quantify the structural similarity between subgraphs, based on which an algorithm for community identification is designed. Extensive empirical results on several real networks from disparate fields has demonstrated that the present algorithm can provide the same level of reliability, measure by modularity, while takes much shorter time than the well-known fast algorithm proposed by Clauset, Newman and Moore (CNM). We further propose a hybrid algorithm that can simultaneously enhance modularity and save computational time compared with the CNM algorithm.
💡 Research Summary
The paper addresses the long‑standing challenge of community detection in very large networks, proposing a novel similarity metric between subgraphs and two algorithms that exploit this metric. The similarity s₍ᵢⱼ₎ between subgraphs Vᵢ and Vⱼ is defined as
s₍ᵢⱼ₎ = eᵢⱼ + Σₖ √(eᵢₖ eₖⱼ) / (|Vₖ|ᵖ dᵢ dⱼ),
where eᵢⱼ is the number of edges directly connecting the two subgraphs, eᵢₖ and eₖⱼ count edges from Vᵢ and Vⱼ to a third subgraph Vₖ, |Vₖ| is the size of Vₖ, dᵢ (dⱼ) is the sum of degrees of nodes in Vᵢ (Vⱼ), and p is a parameter that reduces bias caused by size differences. This formulation captures both direct connections and shared connectivity to other subgraphs, treating the degree sums as a “mass” and the denominator as a normalizing factor.
The first algorithm (referred to as XCZ) starts from an initial partition where each node forms its own subgraph. For each subgraph, it identifies the most similar partner(s) according to s₍ᵢⱼ₎, builds a graph of these “most‑similar” links, and merges each connected component into a new subgraph. This process repeats until a single subgraph remains, while tracking modularity Q at every step and retaining the partition with maximal Q. The procedure is deterministic and does not depend on the order of processing.
Recognizing that the well‑known Clauset‑Newman‑Moore (CNM) greedy modularity maximization algorithm tends to merge low‑degree nodes early, which can cause irreversible errors, the authors introduce a hybrid approach (XCZ+CNM). They first perform a single XCZ iteration, guaranteeing that every subgraph contains at least two nodes, then continue with the standard CNM greedy merging. This combination leverages the fast, structure‑aware initial merging of XCZ while preserving CNM’s fine‑grained modularity optimization.
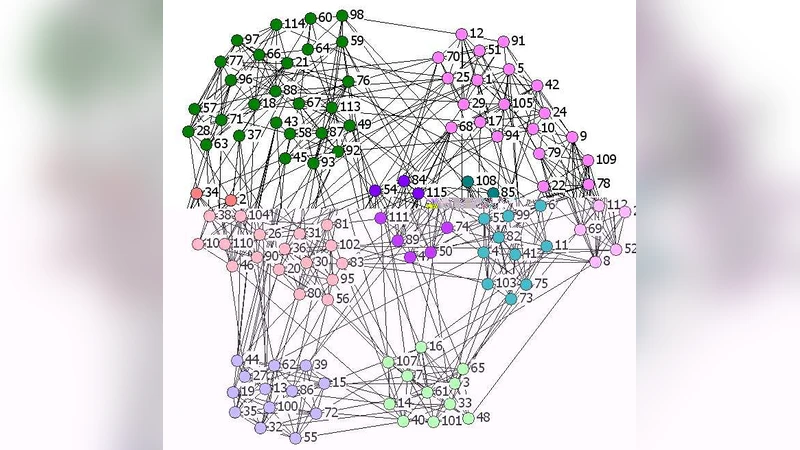
Empirical evaluation uses five real‑world networks of varying size and domain: the American college football network (115 nodes), a yeast protein‑protein interaction network (2,631 nodes), a condensed‑matter collaboration network (40,421 nodes), a sampled World‑Wide‑Web graph (325,729 nodes), and an IMDb actor network (1,324,748 nodes). Results (Tables 2 and 3) show that XCZ achieves modularity values comparable to CNM but runs 100–10,000 times faster, depending on the dataset. The hybrid XCZ+CNM consistently yields the highest modularity among the three methods, while still completing in practical time even for the million‑node IMDb network (less than a day). Visual comparison on the football network demonstrates that XCZ+CNM recovers community assignments much closer to the known conference structure than CNM alone.
The authors conclude that subgraph similarity provides a richer, more global notion of proximity than simple node similarity, enabling ultra‑fast community detection without sacrificing quality. They acknowledge the intrinsic resolution limit of modularity, suggesting normalized mutual information as a complementary evaluation metric, and propose extending the similarity measure to weighted graphs as future work.
Overall, the paper contributes a theoretically motivated similarity metric, a deterministic fast agglomerative algorithm, and a practical hybrid scheme that together advance the state of the art in scalable community detection.
Comments & Academic Discussion
Loading comments...
Leave a Comment