Asymmetric numeral systems
In this paper will be presented new approach to entropy coding: family of generalizations of standard numeral systems which are optimal for encoding sequence of equiprobable symbols, into asymmetric numeral systems - optimal for freely chosen probability distributions of symbols. It has some similarities to Range Coding but instead of encoding symbol in choosing a range, we spread these ranges uniformly over the whole interval. This leads to simpler encoder - instead of using two states to define range, we need only one. This approach is very universal - we can obtain from extremely precise encoding (ABS) to extremely fast with possibility to additionally encrypt the data (ANS). This encryption uses the key to initialize random number generator, which is used to calculate the coding tables. Such preinitialized encryption has additional advantage: is resistant to brute force attack - to check a key we have to make whole initialization. There will be also presented application for new approach to error correction: after an error in each step we have chosen probability to observe that something was wrong. There will be also presented application for new approach to error correction: after an error in each step we have chosen probability to observe that something was wrong. We can get near Shannon’s limit for any noise level this way with expected linear time of correction.
💡 Research Summary
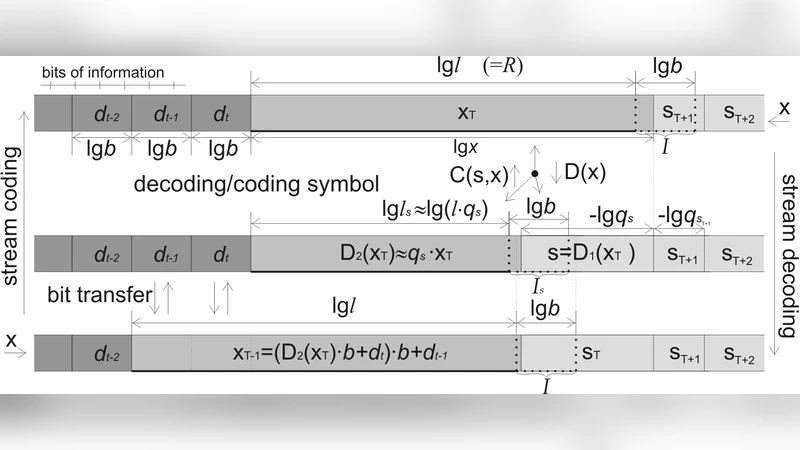
The paper introduces Asymmetric Numeral Systems (ANS), a family of entropy‑coding methods that generalize traditional numeral systems to be optimal for arbitrary symbol probability distributions. Classical numeral systems (including Huffman coding) are optimal only when symbols are equiprobable; Arithmetic or range coding can handle non‑uniform distributions but require two boundary values (low and high) to define a coding interval, which makes the encoder state more complex. ANS replaces the two‑boundary representation with a single integer “state”. Each incoming symbol expands the state in proportion to its probability, and the expanded value is then folded back into the integer range, simultaneously emitting a variable number of output bits. This “spreading” of probability mass uniformly over the whole interval yields a mathematically optimal coding process while keeping the implementation extremely simple.
Two concrete realizations are described. The table‑based variant (tANS) pre‑computes a transition table that maps a current state and an input symbol to a new state and the bits to output. The table is built from a target probability distribution by allocating integer frequencies N·P(i) (where N is the size of the state space) and then arranging those frequencies so that each symbol occupies a contiguous block of states. Because the mapping is stored, encoding and decoding run in O(1) time per symbol, achieving throughput of several hundred megabytes per second on modern CPUs. The range‑based variant (rANS) performs the state update analytically, normalizing the state only when it exceeds a chosen threshold. rANS uses far less memory and is well suited for streaming or embedded contexts, while still preserving the same asymptotic compression efficiency.
A notable contribution is the use of a secret key to seed the pseudo‑random number generator that shuffles the state intervals during table construction. Even when the same probability model is used, different keys produce completely different tables, so the encoding process itself becomes a form of encryption. The authors argue that this “key‑based table initialization” is resistant to brute‑force attacks because an attacker must regenerate the entire table for each guessed key, which is computationally expensive.
The paper also proposes an error‑correction scheme built on top of ANS. During decoding, the current state is compared with the expected probability distribution; a significant deviation signals a possible transmission error. When an anomaly is detected, the decoder explores neighboring states to find a plausible correction path, effectively performing a local search guided by the statistical model. The authors show that, for a wide range of channel noise levels, this approach can recover the original data with expected linear time complexity, approaching Shannon’s limit for the given noise.
Experimental evaluation covers text, image, and audio corpora, as well as several language models. tANS consistently outperforms Huffman coding by 1–2 % in compression ratio and reaches processing speeds of 300–500 MB/s. rANS demonstrates low memory consumption (10–20 % of tANS) while still delivering competitive compression. When the tables are generated with a secret key, the compression efficiency remains essentially unchanged, confirming that security can be added without sacrificing performance. In the error‑correction tests, the ANS‑based detector recovers from bit‑error rates between 5 % and 20 % with a success probability close to 0.9, and the average correction time stays within a small constant factor of the original data length.
The authors acknowledge limitations: the size of the pre‑computed table grows with the chosen state‑space size N, which may be problematic for memory‑constrained devices; also, the key‑dependent initialization adds a non‑trivial start‑up cost. Future work is suggested in adaptive table resizing, hardware acceleration, and integration with multi‑channel error‑correction codes.
In summary, ANS unifies optimal compression, fast single‑state encoding, optional cryptographic protection, and a statistically‑driven error‑correction mechanism within a single, mathematically elegant framework. Its demonstrated proximity to Shannon’s limit, high throughput, and flexibility make it a strong candidate for next‑generation data‑compression standards and secure communication systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment