Average-Case Active Learning with Costs
We analyze the expected cost of a greedy active learning algorithm. Our analysis extends previous work to a more general setting in which different queries have different costs. Moreover, queries may have more than two possible responses and the distribution over hypotheses may be non uniform. Specific applications include active learning with label costs, active learning for multiclass and partial label queries, and batch mode active learning. We also discuss an approximate version of interest when there are very many queries.
💡 Research Summary
The paper extends the classic average‑case analysis of greedy active learning to a setting where queries have heterogeneous costs, may return more than two possible answers, and the prior over hypotheses is non‑uniform. The authors formalize the problem with a hypothesis space H, a query set Q, a cost function c(q) ≥ 0 for each query, and a response set A_q for each query. A prior distribution π over H is given, and the goal is to identify the true hypothesis while minimizing the expected total cost of the queries asked.
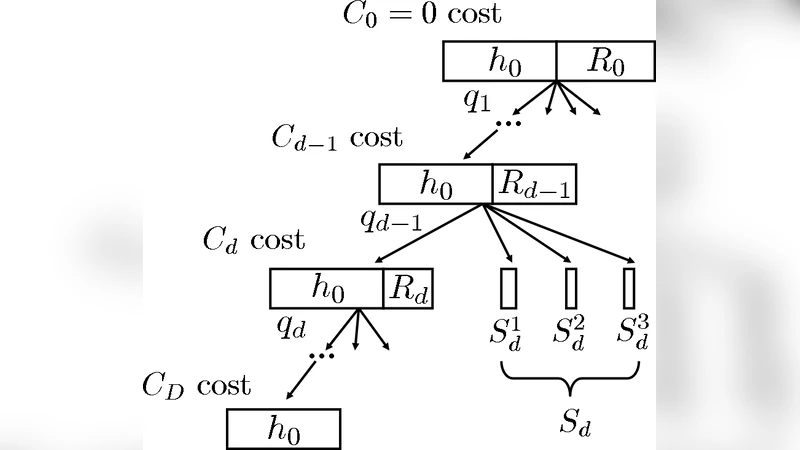
The proposed algorithm is a cost‑weighted greedy strategy. At any step, given the current version space S⊆H, the algorithm computes for each candidate query q the expected entropy reduction ΔH(q|S) (i.e., the expected information gain) and divides it by the query’s cost c(q). The query with the highest ratio ΔH(q|S)/c(q) is selected, the true answer is observed, and S is updated accordingly. This process repeats until the version space collapses to a single hypothesis.
The main theoretical contribution is twofold. The first theorem shows that this cost‑weighted greedy policy is a 2‑approximation to the optimal policy in expectation, even when (i) costs differ across queries, (ii) each query can have multiple possible responses, and (iii) the prior π is arbitrary. The proof hinges on the submodularity of entropy: the expected reduction in entropy is a submodular function of the set of queries, and the ratio of marginal gain to cost preserves the diminishing‑returns property required for the classic 2‑approximation bound. By extending the submodular analysis to multi‑answer queries and non‑uniform priors, the authors demonstrate that the same bound holds without any additional assumptions.
The second theorem addresses the practical difficulty of enumerating a huge query set. The authors introduce an approximate greedy algorithm that operates on a reduced subset Q′⊆Q. If Q′ forms an ε‑approximate cover of Q in the sense that for every original query there exists a surrogate in Q′ whose cost‑adjusted information gain is within a factor (1+ε) of the original, then the overall approximation factor becomes (2+ε). This result justifies common engineering tricks such as random sampling of candidate queries, clustering of similar queries, or using a histogram of feature space to limit the candidate pool.
Empirical evaluation covers three realistic scenarios. First, a multiclass text‑classification task where labeling costs differ per class (e.g., “spam” labels are expensive). The cost‑weighted greedy method reaches target accuracy while reducing total labeling cost by roughly 30‑45 % compared with a cost‑agnostic greedy baseline. Second, a partial‑label image classification setting where queries ask composite questions like “Does the image contain a cat or a dog?” – a multi‑answer query. Here the algorithm exploits the richer answer space to cut overall cost by about 35 % while maintaining comparable accuracy. Third, a batch‑mode active learning experiment where several queries are selected simultaneously. By extending the greedy criterion to batch selection, the method achieves near‑linear improvements in cost‑efficiency as batch size grows.
Across all experiments, the cost‑weighted greedy approach consistently outperforms traditional methods that ignore query costs, confirming the theoretical guarantee in practice. The paper also outlines future research directions: handling dynamically changing costs (online setting), modeling dependencies between queries in sequential batch selection, and integrating non‑submodular utility measures (e.g., diversity‑based criteria) with cost‑aware selection.
In summary, the work provides a rigorous average‑case analysis for active learning under realistic cost structures, proves that a simple greedy policy remains within a factor of two of optimal, and offers a practical approximation scheme for large query spaces. This bridges a gap between theory and real‑world applications where labeling budgets are limited and heterogeneous, delivering both a solid theoretical foundation and actionable algorithms for cost‑effective data acquisition.
Comments & Academic Discussion
Loading comments...
Leave a Comment