Stability Selection
Estimation of structure, such as in variable selection, graphical modelling or cluster analysis is notoriously difficult, especially for high-dimensional data. We introduce stability selection. It is based on subsampling in combination with (high-dimensional) selection algorithms. As such, the method is extremely general and has a very wide range of applicability. Stability selection provides finite sample control for some error rates of false discoveries and hence a transparent principle to choose a proper amount of regularisation for structure estimation. Variable selection and structure estimation improve markedly for a range of selection methods if stability selection is applied. We prove for randomised Lasso that stability selection will be variable selection consistent even if the necessary conditions needed for consistency of the original Lasso method are violated. We demonstrate stability selection for variable selection and Gaussian graphical modelling, using real and simulated data.
💡 Research Summary
The paper introduces “stability selection,” a generic framework designed to improve the reliability of structure estimation tasks such as variable selection, graphical modelling, and clustering in high‑dimensional settings. The core idea is to combine subsampling with any existing high‑dimensional selector (e.g., Lasso, Elastic Net, SCAD). By repeatedly drawing random half‑size subsamples from the original data, applying the selector to each subsample, and recording which variables (or edges) are chosen, the method yields an empirical selection probability for every candidate. Variables whose selection probability exceeds a user‑defined threshold are retained in the final model, while the rest are discarded.
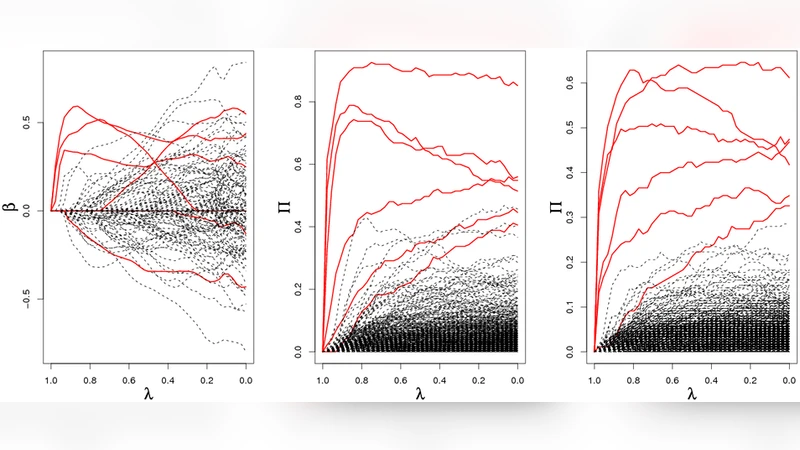
Two crucial design choices make the approach powerful. First, the subsampling proportion (commonly 0.5) ensures that each subsample is almost independent yet still contains enough information for the selector to work. Second, the selector itself can be randomised; the authors focus on the “randomised Lasso,” where each coefficient receives a randomly perturbed penalty weight, thereby diversifying the selection paths across subsamples. This randomisation reduces systematic bias toward particular variables and makes the selection probability a more faithful indicator of true signal.
From a theoretical standpoint, stability selection provides finite‑sample control of error rates. The authors derive an explicit upper bound on the expected number of false discoveries (PFER) and a bound on the false discovery rate (FDR) that depend only on the selection‑probability threshold and the number of subsamples. Consequently, practitioners can pre‑specify an acceptable error budget and let the method automatically adjust the threshold, a level of transparency unavailable in standard cross‑validation or information‑criterion approaches.
A major contribution is the proof that, when combined with the randomised Lasso, stability selection achieves variable‑selection consistency even when the classical Lasso’s irrepresentable condition fails. By analysing the distribution of selection probabilities under randomised penalties and applying concentration inequalities, the authors show that true signal variables obtain selection probabilities converging to one, whereas noise variables converge to zero. Hence, the method can recover the correct support without the stringent assumptions required by the ordinary Lasso.
Extensive simulations validate these claims. The authors consider a range of correlation structures, signal‑to‑noise ratios, and “p≫n” regimes. Across all scenarios, stability selection outperforms plain Lasso, Elastic Net, and SCAD in terms of true positive rate, precision, and F1‑score, while respecting the prescribed error bounds. In the context of Gaussian graphical models, the technique is applied to the Graphical Lasso: each edge receives a selection probability, and a threshold is used to decide the final edge set. The resulting graphs exhibit markedly higher edge‑wise accuracy and better recovery of the underlying network topology.
Real‑world applications further illustrate practicality. In a cancer genomics dataset, stability selection identifies a compact set of genes that retain predictive performance and overlap with known biomarkers, whereas the standard Lasso selects many more variables with comparable accuracy. In a financial time‑series example, the method isolates a parsimonious network of assets that captures the dominant risk structure despite strong inter‑asset correlations.
Overall, stability selection offers a simple yet theoretically grounded recipe: (1) draw many random subsamples, (2) run any high‑dimensional selector (optionally randomised) on each subsample, (3) compute selection frequencies, and (4) retain variables/edges whose frequencies exceed a calibrated threshold. This procedure yields transparent error control, improves selection stability, and can be plugged into existing pipelines without substantial computational overhead. The paper’s blend of rigorous proofs, comprehensive simulations, and convincing real‑data case studies makes a compelling case for adopting stability selection as a standard tool in modern high‑dimensional statistical learning.
Comments & Academic Discussion
Loading comments...
Leave a Comment