Accelerator-Oriented Algorithm Transformation for Temporal Data Mining
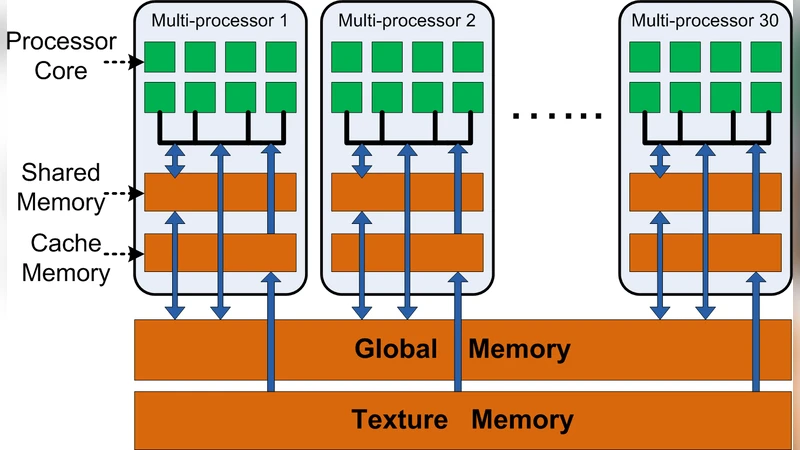
Temporal data mining algorithms are becoming increasingly important in many application domains including computational neuroscience, especially the analysis of spike train data. While application scientists have been able to readily gather multi-neuronal datasets, analysis capabilities have lagged behind, due to both lack of powerful algorithms and inaccessibility to powerful hardware platforms. The advent of GPU architectures such as Nvidia’s GTX 280 offers a cost-effective option to bring these capabilities to the neuroscientist’s desktop. Rather than port existing algorithms onto this architecture, we advocate the need for algorithm transformation, i.e., rethinking the design of the algorithm in a way that need not necessarily mirror its serial implementation strictly. We present a novel implementation of a frequent episode discovery algorithm by revisiting “in-the-large” issues such as problem decomposition as well as “in-the-small” issues such as data layouts and memory access patterns. This is non-trivial because frequent episode discovery does not lend itself to GPU-friendly data-parallel mapping strategies. Applications to many datasets and comparisons to CPU as well as prior GPU implementations showcase the advantages of our approach.
💡 Research Summary
The paper addresses the growing need for efficient analysis of large‑scale temporal datasets, particularly multi‑neuron spike‑train recordings in computational neuroscience. While data acquisition technologies have advanced, analytical tools have lagged because traditional frequent‑episode discovery algorithms are inherently sequential and exhibit irregular memory access patterns that map poorly onto modern many‑core accelerators such as GPUs. Rather than simply porting the serial code, the authors advocate an “algorithm transformation” approach: redesign the algorithm from the ground up to exploit the architectural strengths of GPUs.
The authors first decompose the problem into two logically independent phases: candidate generation and candidate verification. In the candidate‑generation phase, the input spike stream is partitioned into fixed‑size sliding windows. Each window becomes an independent work‑item that can be processed by a separate GPU thread or thread block. To make memory accesses coalesced, the events inside each window are reordered into a contiguous array layout, converting the original event list into a structure‑of‑arrays (SoA) representation. This eliminates the scattered reads that would otherwise cause severe bandwidth penalties.
The verification phase counts how often each candidate episode actually occurs across the entire dataset. Simple atomic increments on global memory would serialize the operation and destroy scalability, so the authors introduce a hybrid bitmap‑based counter. Within each thread block, a shared‑memory bitmap accumulates local counts using lock‑free bitwise operations. Periodically, these local aggregates are flushed to global memory using a small number of atomic updates. This design dramatically reduces contention on the global memory bus while preserving exact counting semantics.
Memory layout optimizations are a recurring theme. By replacing the naïve array‑of‑structures (AoS) with a pure SoA, the kernel achieves high memory throughput on the Nvidia GTX 280. The authors also prune unnecessary intermediate buffers and reuse allocated memory across kernel launches, keeping the total GPU memory footprint well below the 2 GB limit of the test hardware even for datasets containing hundreds of thousands of spikes.
Experimental evaluation uses several real‑world neuroscience datasets ranging from a few hundred to tens of thousands of neurons and spike sequences lasting up to several minutes. The transformed GPU implementation is benchmarked against a single‑core CPU baseline and against a previously published GPU port that performed a straightforward translation of the serial algorithm. Results show an average speed‑up of more than 30× over the CPU and roughly 5× over the prior GPU version. The advantage grows with episode length, confirming that the transformation scales favorably as the combinatorial search space expands. Memory usage remains modest, and the implementation can process the largest test case without running out of GPU memory.
Beyond the specific algorithm, the paper makes two broader contributions. First, it demonstrates that rethinking algorithmic structure—not just low‑level code tuning—can unlock the performance potential of commodity accelerators for complex data‑mining tasks. Second, the presented transformation framework (problem decomposition, data‑layout redesign, hierarchical counting) is generic enough to be applied to other temporal‑pattern mining problems, such as motif discovery or sequential pattern mining, that suffer from similar data dependencies. In sum, the work provides a practical, high‑performance solution for frequent‑episode discovery on GPUs and establishes a methodological blueprint for future accelerator‑oriented algorithm redesigns in the temporal data‑mining domain.
Comments & Academic Discussion
Loading comments...
Leave a Comment