Counteracting Byzantine Adversaries with Network Coding: An Overhead Analysis
Network coding increases throughput and is robust against failures and erasures. However, since it allows mixing of information within the network, a single corrupted packet generated by a Byzantine attacker can easily contaminate the information to …
Authors: MinJi Kim, Muriel Medard, Joao Barros
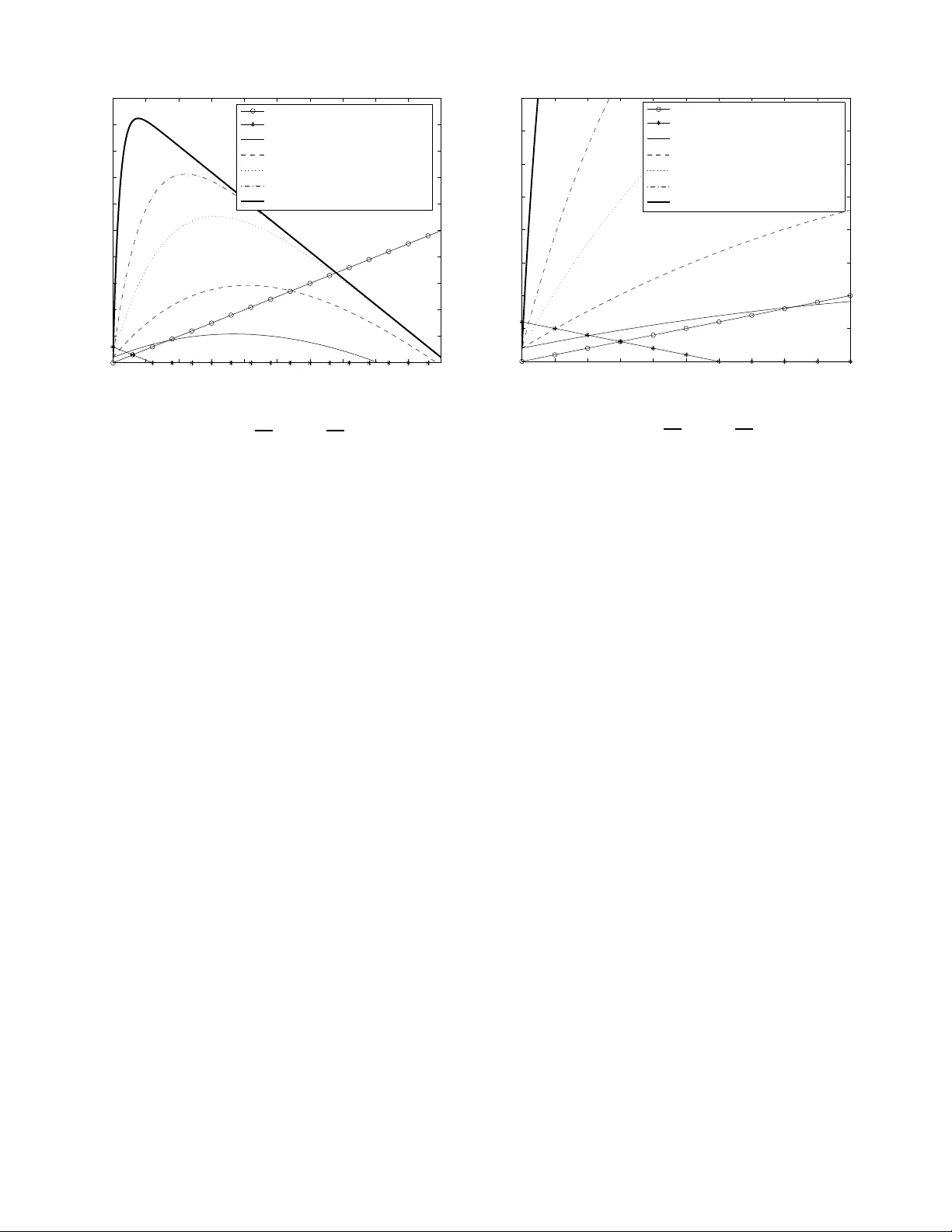
COUNTERA CTING BYZANTINE AD VERSARIES WITH NETW ORK CODING: AN O VERHEAD AN AL YSIS MinJi Kim Massachusetts Institute of T echnolo gy Cambridge, MA 02139 , USA Email: minjikim@mit.ed u Muriel M ´ edard Massachusetts I nstitute of T echn ology Cambridge, MA 02139 , USA Email: medard @mit.edu Jo ˜ ao Barros Instituto de T elecommu nicac ¸ ˜ oes Universidade do Por to, Porto, Portugal Email: barros@dcc. fc.up.p t Abstract — Network coding increases throughput and is robust against failures and era sures. H ow ever , since it allows mixing of information within the network, a single corrupted pack et generated by a Byzantine attacker can easily contam inate the information to multiple destinations. In thi s paper , we study the transmission overhead associ- ated with three different schemes for detecting Byzantine adversaries at a node using network coding: end-to-end error correction, pa ck e t-based Byzantine detection scheme, and generatio n-based Byzantine detection scheme. In end- to-end error correction, it is kno wn that w e can co rrect up to the min-cut between the source and destinations. How ever , if we use Byzantine detection schemes, we can detect polluted da ta, dro p them, and therefore, only transmit valid data. F o r the drop ped data, the destinations p erform erasure correction, which is computationa lly lig hter tha n error correction. W e show that, with enough attack ers present in the network, Byzantine d etection schemes may improve the throug hput of the network since we choose to forw a rd only reliable inf ormation. When the proba bility of atta ck is high, a packet-based detection scheme is the most bandwidth efficient; howev er , when the p robability of atta ck is low , the overhead in volved with sig ning ea ch packet becomes costly, and the g eneration-ba sed scheme may be preferred. F ina lly , we characterize the tradeo ff between generation size and overhead of detectio n in bits as the proba bility o f attack increases in the network. I . I N T RO D U C T I O N Network coding , which was first introduce d in [1], allows algebraic mixing of information in the inter - mediate nodes . Th is mixing has be en s hown to have numerous performance be nefits. It is known that network coding maximizes through put [1], a s well as robustness against failures [2] and erasures [3]. Howe ver , a major concern for ne twork coding sys tem is its vulnerab ility to By zantine adversa ries. A single c orrupted pa cket generated by a Byzantine adversary c an contaminate all the information to a des tination, and propa gate to other destinations quick ly . For example, in random linear network coding [3], o ne c orrupted p acket in a g eneration can p rev e nt a rec eiv e r from decoding any data from that generation even if all the other packets it has recei ved are v alid. There are se veral pape rs that attempt to address this problem. On e ap proach is to correct the errors injected by the Byzantine adversaries using network error cor- r e ction [4]. Reference [4] bounds the maximum achiev- able rate in an adversarial setting, a nd ge neralizes the Hamming, Gilbert-V arshamov , and Singleton bou nds. Furthermore, Ja ggi et al. [5] propose a distrib uted, rate- optimal, network coding scheme for multicast network that is resilient in the presence of Byz antine adversaries. Howe ver , this introduces anothe r question: if the exis- tence of Byzantine adversaries within the ne twork is s us- pected, can we do better than just using error correction codes? Rather than jus t naively using error correcting codes at the destinations, ca n we ac ti vely detec t a nd drop corrupted pa ckets? If so, what k ind o f detec tion scheme sh ould we use? In addition, with the overhead assoc iated with Byz antine de tection in code d sys tems, do we still outpe rform the non-co ded s olution? The goa l of this pa per is to answer some of these questions. W e compare the overhead asso ciated with By zantine detection sc hemes in terms of bits – polluted packets that are se nt or unp olluted pac kets that are droppe d, as well as bits used for h ashes to d etect attacks – and the amount of ba ndwidth saved from employing such detection sch emes. The compu tational overhead assoc iated with comp uting the ha shes, or checking for corrupted packets will be dealt with elsewhere. The paper is or ganize d a s follo ws . In Section II , we present the back ground and related material. In Section III, we introduce o ur network mo del. In Section IV, we analyze the overhead assoc iated with the three Byzantine detection sche mes. In Section V, we study the trade - off s of dif fe rent detection sche mes, as the prob ability of Byzan tine attack varies. Finally , we s ummarize our contributi ons of this pape r . I I . B A C K G RO U N D A. Ne twork Coding Reference [1 ] sh ows that ne twork coding a llo w s a source to multicast information at a rate approach ing the smallest cut between the s ource and any recei ver , as 978-1 -4244 -267 7-5/08/$25.00 c 2008 IEEE 1 of 7 the c oding s ymbol size approache s infinity . Li et al. [6] show that linear network coding is s ufficient for multicast networks to achieve the optimum. Subs equently , Koetter et al. [2] p resent an algebraic frame work for linear network co ding in arbitrary networks. As a result, there has been a great emphas is on linear network coding. For instance, Ho et a l. [7] propose a simple, practical capacity-achieving c ode, in which e very node cons truct its linear code rand omly a nd indep en- dently from all other no des. This s imple co nstruction has been shown to ac hieve c apacity with p robability approach ing 1 exponentially fast with the field size. This result indica tes that linear ne twork coding is a simple yet a very powerful tool. F urthermore, L un e t al. [3] show that random bloc k linear network c oding system achieves cap acity . In a random block linea r network coding system, a sou rce generates information in block s of G packets (called a gen eration ). Th e source the n multicasts to its destination nod es us ing ran dom linea r network coding , where only the pa ckets from the same generation are mixed. In this pa per , we shall conside r systems that us e random block linear network coding . It is important to note that rando m linear network coding is a distri buted protocol, which requires no state information. It us es the en coding vector – a vector of coefficients of the linea r transformation o f the original packets – to e ncode/de code the original data. Therefore, random block linea r network coding is resili ent in dy- namic/unstable ne tworks wh ere s tate information may change rapidly or may be hard to obtain. B. En d-to-end err or c orrection s cheme In [5], Jaggi et al. introdu ce the first dis trib uted polynomial-time rate-op timal n etwork cod es that work in the presen ce of Byza ntine node s and is information- theoretically secure. In the ir work, Jag gi et a l. present algorithms that are resilient ag ainst ad versaries o f dif fer - ent capa bilities. Given an ad versary wh o can eavesdrop on a ll links a nd jam z links, their algorithm achieves a rate of C − 2 z , where C is the network capac ity; given an a dversary who can observe only z e links and jam z links where z e < C − 2 z , the algorithm achieves a rate of C − z . These rates are the max imum ac hiev able rate giv e n the power of the a dversary . The idea behind this algorithm is tha t the c orrupted packets injected by the adversary can be cons idered a s packets from a secondary s ource; therefore, with enough information a t the destinations, the destination no des can decode both the legit imate sou rce’ s packets as well as the adversary’ s packets. T o allow the destination node s to distinguish the legitimate packets from the adversary’ s packets, the source judiciously ad ds re dundan cy such that the a dversary’ s packets can not satisfy the c onstraints imposed by the redundan cy . For instance, the source may add redundancy so that a certain functions ev alua te to zero on the source ’ s packets. C. P acket-based Byz antine dete ction s cheme There are several signature sche mes tha t have bee n presented in the lit erature. For instance , [8][9] use ho- momorphic hash functions to detec t polluted pac kets. In add ition, Charles et a l. [10] propose a sign ature scheme for network co ding bas ed on W eil pairing on elliptic curves. Although this sc heme doe s not require a sec ure channe l, it is c omputationally expens i ve. In [11], Fang et al. propose a signature s cheme for network coding, wh ich ma kes use of the linea rity prope rty of the packets in a co ded system. This sc heme d oes not require intermediate nodes to d ecode coded p ackets to check the v alidity of a packet; the refore, it is ef ficient in terms of computationa l cost as we ll as de lay . In this paper , we shall consider the signature s cheme from [11], which is designe d for trans mitting large files that a re broken into blocks viewed a s vectors. T a king advantage of the fact that in linea r network coding, any vali d packet transmitted should belong to the subspac e span ned by the original s et of vectors, Fang et al. d esign a signa ture that can be used to easily check the membership of a received vector in the g i ven s ubspac e, while making it hard to generate a fake signature that is not in the s ubspac e b ut passe s the check. The overhead a ssociate d with the signature sch eme is also analyzed in [11]. Given a file, we break it into m blocks/vectors, which are eleme nts in n -dimensional vector spa ce F n p . Then, the size of the file, a vector , and the coding vectors are mn log p , n log p , an d ( m + n ) log p , respectively . This scheme requires a public key K of size a t least ( m + n ) log q , whe re q is a large prime number suc h that p is a di visor of ( q − 1) . In a typica l cryptographic app lications, p is 1 60 bits, q 1 024 bits, and K approximately 6( m + n ) /mn times the file size . It is important to note that a lthough the overhead of the signature is qu ite small (less than 0.1% of the file s ize), the overhead of the key distributi on can be qu ite large. The cost of key distrib ution is not con sidered in [11]. This detection scheme a ssumes no knowledge of the bandwidth av ailable be tween the source and the desti- nations – therefore, can validate packets unde r varying degree o f attack. Thus , this algorithm achiev es rate o f C − z minus the overhead of t he signature sc heme, where 978-1 -4244 -267 7-5/08/$25.00 c 2008 IEEE 2 of 7 Fig. 1. Diagram of the network and a non-ma licious node v C is the network c apacity , a nd z is the rate at which the adversary c an inject packets into the network. D. Gen eration-based Byzan tine d etection sche me In [12], Ho et al. introduce an information-theore tic approach for detecting By zantine adversaries, which only assume s that the adversary did not see all linear combinations of the source packets rec eiv e d by the destinations. They propose a sc heme who se dete ction probability varies with the length of the has h k , coding field size q , a nd the amount of information a bout the random code u nknown to the a dversary s . A polyn omial hash of a flexible length is a ugmented to eac h pac ket in the generation. Onc e the d estination node receiv e s enough pa ckets to dec ode a ge neration, the destination node can deco de the set a nd d etect e rror with probability at mos t k +1 q s . Th e intuition b ehind this sch eme is that if a p acket is reliable, then its data and ha sh symbols are c onsistent with its coefficient vector; and a linear combination of reliable pac kets is also reliable. In [12], Ho et al. design a has h function, which is both efficient to compute and difficult to forge without seeing all valid packets a nd their cod ing c oefficients. This g eneration based sc heme is very chea p and se nsi- ti ve. For example, with 2% overhead ( k = 50 ), lo g q = 7 , s = 5 , the detection probability is at least 98.9 %; with 1% overhead ( k = 100 ), log q = 8 , s = 5 , the detection probability is at leas t 99.0%. Furthermore, this sc heme does n ot require any key a greement/distribution; thus, making it much chea per than the p acket-based scheme . Howe ver , this is a bloc k code , u nlike the signature scheme from Section II-C; therefore, will require a p riori decision on the rate. In addition, the detection can only occur at a node with eno ugh pa ckets fr om a g eneration – thus, c an incu r lar ge delays . I I I . N E T W O R K M O D E L W e model the network b y a d irected graph G = ( V , E ) , where V is the set of n odes in the network, a nd E is the se t of communication links . The re are subse ts of no des, S and T ⊆ V , wh ich wish to send and receive data respecti vely . In this paper , we c onsider a non-malicious no de v ∈ R . Node v wishes to chec k the validity of the packet/generation that it forwards. For the packet-based Byzantine detection scheme fr o m Section II-C, v is given the p ublic key K ; for the gene ration-based Byza ntine detection s cheme from Sec tion II-D, v is allowed to decode a gen eration, if a ll the pac kets of the g i ven generation goes throug h it . Assume that node v receiv es m packets ( n bits each) per time unit. If it detects an error/attack, the n v disc ards that data; o therwise, the v a cts lik e any o ther no de in the network an d forwards the data. A key parameter to c onsider in this work is the probability p v of an a ttack to the node v . At any given time, the probability tha t v receives a packet modified by the Byzantine attacker is p v as shown in F igure 1. Therefore, the expe cted numb er o f corrupted pa ckets that v receives is mp v . It is important to note that the probability p v of an attack is topology d epende nt (in terms of the loc ation of v , Byzantine a ttackers, as well as the source nodes ); thu s, p v may be dif ferent for each node v . W e sh all assume that there is an external model of vulnerability wh ich wil l gi ve an es timate of p v . In the remaining of the paper , we s hall focus on a single non-malicious node v , and the overhead ass ociated with the detection schemes through this one node. This is a reasona ble approach , s ince we are n ot co ncerned with how a malicious n ode u ses its band width. Since we are co nsidering a spe cific node v from now on, we will denote p v as p , unless spe cified otherwise. In the next sections , we c ompare the c ost and the benefi t of employing Byzantine detection sch emes with varying p . I V . O V E R H E A D A N A L Y S I S A. Ov erhead o f end-to-end e rr or c orrection In an end -to-end error correction sche me, the network can achie ve r a te of C − z where C is the network c apacity and the adversa ry can jam z links . Therefore, en d-to- end error c orrection can c orrect up to the reli able min- cut of the sourc e-destinations. Thus, using this scheme, as long as the attack is within the ne twork capacity , the intermed iate node s can trans mit at the remaining network capac ity; and the destination nodes employ err o r correction to retriev e reliable pa ckets. It is important to no te that error correction is computationally more expensive than erasure c orrection, w hich shall be us ed when Byzantine de tection schemes are used. 978-1 -4244 -267 7-5/08/$25.00 c 2008 IEEE 3 of 7 In this scheme , n ode v acts as a normal intermediate node – it d oes not check the vali dity of the pac ket it has receiv ed. It just naiv ely performs random linear network coding and forwards the information it has received. Therefore, in terms of bits transmitted at v , we lose o n av erage mnp -bits, where n is the length of a packet, m is numb er of p ackets v recei ves per time unit, and p is the p robability that any p acket v rece i ves is corrupted. Therefore, the rati o be tween the overhead or corrupted bits transmitted a nd total bits received is: mnp mn = p . (1) B. Ov erhead o f Byzantine de tection for pa ck ets In this section, we ana lyze the overhead ass ociated with the packet-bas ed Byzantine detection algorithm (Section II-C). W e cons ider the s cenario where nod e v check s the validity of every pa cket it recei ves u sing the p ublic key K av ailable to it. Then, v u ses ran dom linear ne twork c oding to forward only the packets that passe d the che ck. If v d etects an error in a packet, then it d iscards it – by d oing so, v doe s not waste its bandwidth in trans mitting corrupted da ta with high probability , and des tination node s perform erasure cor- rection on the packets that hav e been dropped, which is computationally c heape r than error correction required for the error correction sch eme in Se ction IV -A. Ho w- ev er , each p acket need s to c ontain eno ugh information (a polynomial hash) that c an be used to verify its integrity . This overhead associated with the Byzan tine detection scheme reduces the rate at which data is transmitted. Assume that this p olynomial hash is o f size h p bits per packet. Before an alyzing the cost/bene fit of the pac ket- based detection scheme, we first study the rate of actual data transmission. Since p -fraction of pac kets rece iv e d by v is erroneous, v only forwards in total mn − m np bits per un it time, of which on ly (1 − h p n ) fraction of the b its are actual da ta bits. Thus, the ratio betwee n the actual data bits transmitted and total bits transmitted is: ( mn − mnp )(1 − h p n ) mn − mn p = 1 − h p n . This res ult is not a s urprising one – as it s hows that when we employ a By zantine d etection sc heme, v ca n filter out a ll the corrupted packets. As a result, ev ery b it v transmits is a v a lid data bit. This analys is also extends to that o f g eneration-bas ed Byzantine detection sche me in Section IV -C. The overhead associated with the pac ket-based Byzan- tine de tection scheme c an be a nalyzed as follows. By discarding the corrupted p ackets, node v can o n average save its bandwidth b y mn p bits per unit time at a cost of h p bits per packet. Therefore, the expected c ost of the this sch eme at v is: max { 0 , m ( h p − np ) } bits pe r time unit. The refore, the ratio between the overhead a nd the total bits rece i ved is: max { 0 , m ( h p − np ) } mn = max { 0 , h p − np } n . (2) When the probability of error p is high enough, then checking eac h packet for error sav e s on bits trans mitted – i.e. m ( h p − np ) < 0 , wh ich shows that the c ost of the signature scheme is cance led by the bandwidth gained from dropping the corrupted packets, and thus, reduces the overall cost to z ero. Therefore, this approac h is the most s ensible when the network is expected to be unreliable or und er h eavy attack. It is important to note that the p acket-based By zantine detection sc heme assume s the presenc e of a public key distrib u tion infrastructure, the details of which we a re not concerne d with here. Ho wever , there are transmission as well as c omputational overhead a ssociated with such an assumption, wh ich ha s b een s tudied in [13][14]. F urther - more, this packet-base d detection sch eme is d esigned for a lar ge file which is broken into sma ll blocks. T herefore, ev ery n ew file req uires a new p ublic key; the c ost of key distrib u tion bec omes a s ignificant part o f the overhead of this signature scheme. Thus, depending on the public ke y distrib u tion infrastructure us ed an d the frequen cy of ke y renew al, the p acket-based detection scheme will incur a much high er overhead. T his would result in shifting the transmission overhead in Figure 4 outwards. C. Ove rhead o f Byzantine detec tion for generations In this section, we sha ll ass ume ou r sys tem u ses random block linear network coding with generation size G . In this generation-base d By zantine detec tion scheme, a node ch ecks for po ssible error/attack on a generation after c ollecting e nough packets from the generation. If the n ode detects an error , then it disc ards the entire generation of G pa ckets; otherwise , it forwards the data. The destination n odes perform erasure correction on the gen erations that have been dropp ed, which is computationally che aper than error c orrection required in Section IV -A. Thus, this sch eme requires only one hash for the entire generation — saving bits on the hashes c ompared to the packet-based detec tion scheme. Howev er , one c orrupted packet in a generation can make a nod e drop the entire generation and make the ne twork ine f fi cient. For a more detailed analysis on the overhead associ- ated wit h this scheme, assume that the hash is of size 978-1 -4244 -267 7-5/08/$25.00 c 2008 IEEE 4 of 7 h g bits per gen eration. The proba bility of dropping a generation of G packets is given by: p g = P r( generation dropped ) = 1 − Pr( All G packets are valid ) = 1 − (1 − p ) G . Therefore, the probability that a generation is for- warded by v is 1 − p g = (1 − p ) G ; no de v is expe cted to transmit (1 − p ) G nG bits per unit time. By similar analysis as in Sec tion IV -B, the fraction of actual data bits of the (1 − p ) G nG transmitted bits is 1 − h g nG . The overhead assoc iated with this sche me inc ludes the hash of h g bits per ge neration. Ho wever , unlike the packet-based d etection scheme , this sche me may drop uncorrupted pac kets along with the c orrupted packets, if a gen eration is deemed corrupted. The refore, the overhead of the g eneration-bas ed detection scheme also needs to include the uncorrupted packets that were dropped. The expe cted number of unco rrupted b its in a gen eration is giv e n by: (1 − p ) nG b its. Therefore, the exp ected uncorrupted bits dropped per gene ration is: p g (1 − p ) nG b its. Howe ver , this scheme sa ves on bandwidth by d ropping generations with corrupted pa ckets. On average, there are pnG corrupted bits in a e ach generation. Th erefore, the expected overall overhead (in b its) of Byz antine detection per gen eration is: max { 0 , h g + p g (1 − p ) nG − pnG } bits. Thus, the ratio between the overhead and the total bits receiv ed is: max { 0 , h g + p g (1 − p ) nG − pnG } nG . (3) It is important to n ote that, for this s cheme to work, v needs to receive at leas t G pac kets from each gener- ation so that it can decode the generation and use the generation-bas ed Byzantine detection scheme to detec t attackers. This may seem to indicate that this sc heme is only applicable as an end-to-end Byzantine detection scheme or requires tha t v rec eiv e s all packets, but it ca n be used a s a local Byzantine detection s cheme. Consider a n etwork with non-malicious nodes A , B , C , D , E , and F , as s hown in F igure 2, an d a ssume that this ne twork uses the generation-ba sed Byza ntine detection scheme with gene ration size G . In this n etwork, node A is transmitting d ata a t rate r to n ode F ; h owe ver , A sends h alf of its data through B and the other ha lf through C . It may see m that no des B and C cannot check the validity o f any generation transmitted by A Fig. 2. Network with non-ma licious nodes A , B , C , D , E , and F where node A is transmitting at a total rat e of r to node F since it is unlikely tha t they will recei ve enough packets from any ge neration; however , B a nd C can chec k the validit y o f the s ub-generation they receive, wh ere by sub-gene ration, we me an a co llection of G/ 2 enco ded packets from A . By a similar a r gument, D , E , and F can c heck the validity of a sub-ge neration of G/ 4 , G/ 4 , and G pac kets from A , respectiv ely . The refore, a node can c heck e very sub-generation it forwards. V . T R A D E - O F F S In this sec tion, we c hoose h p = 6 100 n a nd h g = 2 100 nG . As noted in Sec tion II-C, the signature and the public key use d in the pa cket-based sch eme are approximately 0. 1% and 6( m + n ) /mn ≈ 6% of the data file size. In any public key infrastructure, the public key has to be transmitted at least on ce, therefore, we make an underestimate of the cost an d choos e h p = 6 100 n . From Section II-D, the hash for the generation-base d scheme is approximately 2% of the transmitted bits. A. A comp arison of coded and n on-coded s ystems A no n-coded sy stem, unlike its c oded coun terpart, requires state infor mation s uch as network topology or buf fer information. As a result, the most ef fec ti ve attack on a routing network is an attack on the co ntrol traf fic. Howe ver , as we noted in Sec tion II-A, network coding systems are robust agains t such an a ttack; making it espec ially more rob ust in dyna mic/unstable networks. In a ddition, for an effecti ve Byzan tine dete ction in a routing n etwork, we need all nodes in the network to be authenticated ; therefore, each packet would need a signature as well as a h ash to verify the identity of the sender and the content of the pac ket. Therefore, a non- coded system would incur overhead s imilar to that of packet-based sche me without the ben efit of throughput gain due to ne twork coding. There a re vari o us literature on the overhead analys is of secure routing protocols, espec ially for wireless ad hoc networks [15][16]. In [16], 978-1 -4244 -267 7-5/08/$25.00 c 2008 IEEE 5 of 7 it has been shown that these routing protocols can incur up to 24% overhead; making the cost of d etection non- negligible without the performance b enefits of cod ing. B. Ge neration size G in the generation-base d scheme In Figure 3, we see tha t gi ven an error probability p , as gen eration size increases, the co st of the gene ration- based s cheme increase s dramatically . If the generation size G is la r g e en ough, there will be a t least one corrupted packet in a generation with high probab ility ev en for s mall p . T his c an be ea sily verified with a n asymptotic analysis of Equation 3 a s G → ∞ : lim G →∞ max { 0 , h g + p g (1 − p ) nG − p nG } nG → max { 0 , 1 − 2 p } . This ind icates that a lar ge gen eration size is unde- sirable – as almost every generation is found faulty and drop ped; making the network through put to zero. Howe ver , this constraint should not bec ome a relev a nt limiting factor in many MANET systems , since the g en- eration sizes are kept small to keep the cod ing/decoding cost lo w . Another interesting thing to note in Figure 3 is that the cost pea ks at a prob ability p ≈ 0 . 2 . At p ≈ 0 . 2 , the generation-based sc heme drop s many generations for a few co rrupted pa ckets e ach generation; as a result, it drop s many valid pa ckets to filter out a few cor- rupted packets. Thus , a t a mode rate rate of attack, the generation-bas ed sc heme s uff e rs. When p << 0 . 2 , the generation-bas ed s cheme does we ll – since the p robabil- ity of error is low and we distribute the cost of has hing across an e ntire generation, we d o not waste band width. When 0 . 2 << p < 0 . 5 , this sche me blocks all generation that is c orrupted – and a s a res ult, the s cheme does not waste ba ndwidth o n corrupted pa ckets. Node s trans mit only v a lid information; howe ver , this happ ens rarely . This also mea ns that we d o n ot us e the ban dwidth to tr ansmit “good” packets sinc e we throw them away along with the corrupted packets in the generation. When p > 0 . 5 , the expe cted throughput is ne ar zero; therefore, the expected cost is zero since we do n ot transmit any corrupted (as well as good) bits. C. A compa rison of the thr ee schemes In Figures 4 and 5, w e compare the three sc hemes. As mentione d in Section IV -A, the expected c ost of error correction sch eme is linearly propo rtional to the error prob ability . Therefore, wh en p is lar ge , this sche me performs b adly . Howev e r , this simple s cheme where 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Probability of error/attack: p Ratio between the overhead and the total bits received G = 2 G = 4 G = 10 G = 20 G = 100 Fig. 3. Ratio between the e xpected o verhead and the total bits recei ved by a node for generation-b ased detection with generation size G , pack et size n = 1000 , and hash size h g = 2 100 nG a node igno res any e rror/attacks and just forwards all the information it receives outperforms the detection scheme s when p is lo w ( p < 0 . 03 ). When the probab ility of error is small, the c ost of detection is an overhead that exceeds the cost introduced b y the attackers. It is interes ting to compare the packet-based an d the generation-bas ed scheme. Whe n the probability of error is lo w , the overhead of hash is costly for the packet-based scheme , since it is devoting h p bits per pac ket to d etect an unlikely attack . In su ch a se tting, the ge neration- based sc heme performs well — it d istrib u tes the cost of the hash ( h g bits) over G packets and s till d etects the few attacks tha t it may encoun ter . Howev e r , as the probability of attack increases, the cost of hashes become “chea per” since the bandwidth wasted by tr ansmitting a corrupted pa ckets increases. This is w here the packet- based scheme outperforms the generation-bas ed sch eme. Howe ver , it is important to note that we underestimate the overhead a ssociate d with the p acket-based sche me in this paper as we do not take into acc ount the public key distri bution c ost, which the gen eration-based scheme does not requ ire. V I . C O N C L U S I O N S When there are eno ugh attackers present in the network, Byzantine detection (either packet-based or generation-bas ed) improv e s the through put since we ca n choose to only forward information that is clean – rather than send the corrupted information and have the destination correct it. 978-1 -4244 -267 7-5/08/$25.00 c 2008 IEEE 6 of 7 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Probability of error/attack: p Ratio between the overhead and the total bit received End−to−end error correction Packet−based (h p = 6/100 n) Generation−based (G = 2, h g = 2/100 nG) Generation−based (G = 4, h g = 2/100 nG) Generation−based (G = 10, h g = 2/100 nG) Generation−based (G = 20, h g = 2/100 nG) Generation−based (G = 100, h g = 2/100 nG) Fig. 4. Ratio between the e xpected o verhead and the total bits recei ved by a node wit h h p = 6 100 n , h g = 2 100 nG As mentioned in Section V, if the probab ility of receiving a bad packet is high e nough (i.e. the n umber of co rrupted bits is higher tha n the cos t of checking e ach packet), then the packet-based B yzantine detection is the most b andwidth efficient. Howe ver , if the probability of an attack is lo w , then the overhead of attaching a hash for ev e ry packet becomes costly . Therefore, the gene ra- tion a pproach in Se ction IV -C is appropriate. However , although the generations allow us to reduce the cos t of the hash , the p robability that a corrupted packet is in a generation increa ses with the size of the generation. Therefore, a right balance between the generation s ize and the error prob ability is n eeded if we choos e to use generation-bas ed Byzan tine detection. A C K N O W L E D G E M E N T This material is based u pon work unde r a subc ontract #069145 issued by B AE Systems Nationa l Se curity Solutions, Inc. and s upported by the D ARP A and the Space an d Naval W arfare System Center , San Diego under Contract No. N6600 1-08-C-2013. R E F E R E N C E S [1] R. Ahlswede, N. Cai , S .-Y . R. Li, and R. W . Y eung, “Netwo rk information fl o w , ” IEEE T ransactions on Information Theory , vol. 46, pp. 1204–1216 , 2000. [2] R. K oetter and M. M ´ edard, “ An algebraic approach to network coding, ” IEEE/ACM T ransaction on Networking , vo l. 11, pp. 782–79 5, 2003. [3] D. Lun, M. M ´ edard, D. Karger , and M. Ef f ros, “On coding for reliable communication over pack et networks, ” in Procee dings of 42nd A nnual All erton Confer ence on Communication, Con- tr ol, and Computing, In vited paper , September–October 2004 . [4] R. W . Y eung and N. Cai, “Network error correction, ” Commu- nications in Information and Systems , no. 1, pp. 19–5 4, 2006. 0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.1 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 Probability of error/attack: p Ratio between the overhead and the total bits received End−to−end error correction Packted−based (h p = 6/100 n) Generation−based (G = 2, h b = 2/100 nG) Generation−based (G = 4, h b = 2/100 nG) Generation−based (G = 10, h b = 2/100 nG) Generation−based (G = 20, h b = 2/100 nG) Gereration−based (G = 100, h b = 2/100 nG) Fig. 5. Ratio between the e xpected o verhead and the total bits recei ved by a node wit h h p = 6 100 n , h g = 2 100 nG for p ∈ [0 , 0 . 1] [5] S. Jaggi, M. Langberg, S . Katti, T . Ho, D. Katabi, and M. M ´ edard, “Resilient network coding in the presence of byzantine adversaries, ” in Pro ceedings of IEEE INFOCOM , March 2007, pp. 616 – 624. [6] S.-Y . R . Li, R. W . Y eung, and N. Cai, “Linear network coding, ” IEEE Tr ansaction on Information T heory , vol. 49, pp. 371–381 , 2003. [7] T . Ho, M. M ´ edard, R. K oetter , M. Effros, J. S hi, and D. R. Karger , “ A random linear coding approa ch to mutlicast, ” IEEE T ransaction on Information Theory , vol. 52, pp. 4413–4430, 2006. [8] C. Gkantsidis and P . Rodriguez, “Cooperati ve security for network coding file distribution, ” i n Procee dings of IEEE IN - FOCOM , April 2006 . [9] M. Krohn, M. F reedman, and D. Mazi ` eres, “On-the-fly verfica- tion of ratel ess erasure codes for efficient content distribution, ” in Procee dings of IEEE Symposium on Security and Privacy , May 2004. [10] D. Charles, K. Jain, and K. Lauter, “Signatures for network coding, ” in Procee dings of Confer ence on Information Sciences and Systems , March 2006. [11] F . Zhao, T . Kalker , M. M ´ edard, and K. J. Han, “Signatures for content dist ribution with network coding, ” i n Pr oceedings of IEEE ISIT , June 2007. [12] T . Ho, B. Leong, R. K oetter, M. M ´ edard, and M. Effros, “Byzantine modification detection in multicast networks using randomized netw ork coding, ” in Pr oceedings of IEEE ISIT , June 2004. [13] P . F . Oliv eira and J. Barros, “ A network coding approach to secret key distribution, ” Accepted for the IEEE T ransactions on Information F orensics and Security , May 2008. [14] D. Malan, M. W elsh, and M. Smith, “ A pub l ic-ke y infrastructure for key distribution in ti nyos based on ell iptic curve cryptog- raphy , ” in Pr oceedings of IEEE Confer ence on Sensor and Ad Hoc Communications and N etworks , Oct. 2004, pp. 71–80 . [15] J.- P . Hubaux, L. Butty ´ an, and S. Capkun , “The qu est for security in mobile ad hoc networks, ” in P r oceedings of the 2nd ACM MobiHoc . A CM, 2001, pp. 146–15 5. [16] S . Marti, T . J. Giuli, K. Lai, and M. Baker , “Mitigating routing misbehav i or in mobile ad hoc netw orks, ” i n Pr oceedings of the 6th annual international confer ence on Mobile computing and networking . A CM, 2000, pp. 255–26 5. 978-1 -4244 -267 7-5/08/$25.00 c 2008 IEEE 7 of 7
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment