Optimized Implementation of Elliptic Curve Based Additive Homomorphic Encryption for Wireless Sensor Networks
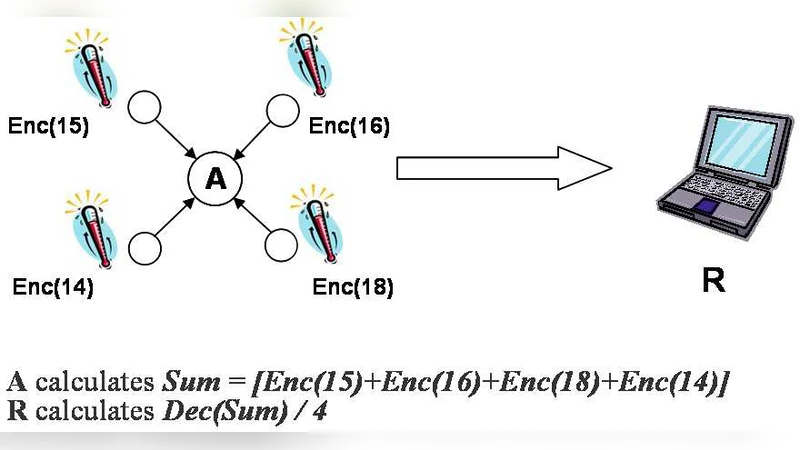
When deploying wireless sensor networks (WSNs) in public environments it may become necessary to secure their data storage and transmission against possible attacks such as node-compromise and eavesdropping. The nodes feature only small computational and energy resources, thus requiring efficient algorithms. As a solution for this problem the TinyPEDS approach was proposed in [7], which utilizes the Elliptic Curve ElGamal (EC-ElGamal) cryptosystem for additive homomorphic encryption allowing concealed data aggregation. This work presents an optimized implementation of EC-ElGamal on a MicaZ mote, which is a typical sensor node platform with 8-bit processor for WSNs. Compared to the best previous result, our implementation is at least 44% faster for fixed-point multiplication. Because most parts of the algorithm are similar to standard Elliptic Curve algorithms, the results may be reused in other realizations on constrained devices as well.
💡 Research Summary
The paper addresses the challenge of securing data storage and transmission in wireless sensor networks (WSNs) where nodes have extremely limited computational power, memory, and energy. In asynchronous WSNs, sensed data may reside in the network for extended periods before being collected, making confidentiality and integrity essential. The TinyPEDS framework previously proposed a hybrid approach that combines symmetric encryption for in‑network aggregation with public‑key encryption for long‑term storage. To enable additive homomorphic aggregation, the authors selected the Elliptic Curve ElGamal (EC‑ElGamal) scheme because it provides small ciphertexts and supports the required homomorphic property.
The contribution of this work is a highly optimized implementation of EC‑ElGamal on the MicaZ mote, an 8‑bit platform (ATmega128L, 8 MHz, 4 KB flash, 128 B SRAM). The authors prioritize three design goals in order: code size, memory consumption, and execution time. Their optimization proceeds through several abstraction layers:
-
Finite‑field layer – They choose a prime field GF(p) rather than a binary field, because binary arithmetic incurs higher memory traffic on small processors. The prime is selected to be a pseudo‑Mersenne prime of the form p = 2ⁿ − c, allowing very fast modular reduction. After each multi‑precision multiplication, reduction replaces the high‑order 2ⁿ term with the small constant c, dramatically cutting the number of word‑level operations. Modular addition is also performed using the same reduction technique, replacing a subtraction with an addition of c when overflow occurs, which halves the execution time compared with the classic subtract‑if‑greater‑or‑equal method.
-
Elliptic‑curve group layer – The authors evaluate several coordinate systems (affine, projective, Jacobian, Chudnovsky‑Jacobian, modified Jacobian) and mixed representations. For point addition they adopt an Affine‑Jacobian mixed format (AJJ), where the first operand is in affine coordinates and the second in Jacobian, producing a Jacobian result. For point doubling they use Jacobian‑Jacobian (JJ). This mixed approach eliminates the need for costly field inversions on the sensor node and reduces both storage and computational overhead.
-
Scalar multiplication layer – Scalar multiplication dominates the cost of EC‑ElGamal encryption and decryption. The authors compare classic Schoolbook, Karatsuba, Comba, and Hybrid multiplication methods for multi‑precision integer products. The Hybrid method, which combines the low‑register footprint of Schoolbook with the speed of Comba, is selected as the best compromise for the 8‑bit architecture. They also incorporate the Interleaved method for point multiplication and replace the traditional Non‑Adjacent Form (NAF) with the Mutual Opposite Form (MOF) to lower pre‑computation storage while still reducing the number of required point doublings.
The resulting implementation occupies roughly 2 KB of flash and less than 150 bytes of RAM, well within the constraints of the MicaZ mote. Benchmarks show that fixed‑point multiplication is at least 44 % faster than the previous best implementation for this platform (reference
Comments & Academic Discussion
Loading comments...
Leave a Comment