📝 Original Info
- Title: Compressive sensing: a paradigm shift in signal processing
- ArXiv ID: 0812.3137
- Date: 2009-03-13
- Authors: Researchers from original ArXiv paper
📝 Abstract
We survey a new paradigm in signal processing known as "compressive sensing". Contrary to old practices of data acquisition and reconstruction based on the Shannon-Nyquist sampling principle, the new theory shows that it is possible to reconstruct images or signals of scientific interest accurately and even exactly from a number of samples which is far smaller than the desired resolution of the image/signal, e.g., the number of pixels in the image. This new technique draws from results in several fields of mathematics, including algebra, optimization, probability theory, and harmonic analysis. We will discuss some of the key mathematical ideas behind compressive sensing, as well as its implications to other fields: numerical analysis, information theory, theoretical computer science, and engineering.
💡 Deep Analysis
Deep Dive into Compressive sensing: a paradigm shift in signal processing.
We survey a new paradigm in signal processing known as “compressive sensing”. Contrary to old practices of data acquisition and reconstruction based on the Shannon-Nyquist sampling principle, the new theory shows that it is possible to reconstruct images or signals of scientific interest accurately and even exactly from a number of samples which is far smaller than the desired resolution of the image/signal, e.g., the number of pixels in the image. This new technique draws from results in several fields of mathematics, including algebra, optimization, probability theory, and harmonic analysis. We will discuss some of the key mathematical ideas behind compressive sensing, as well as its implications to other fields: numerical analysis, information theory, theoretical computer science, and engineering.
📄 Full Content
Compressive sensing [45,119] is a new concept in signal processing where one seeks to minimize the number of measurements to be taken from signals while still retaining the information necessary to approximate them well. The ideas have their origins in certain abstract results from functional analysis and approximation theory [79,92] but were recently brought into the forefront by the work of Candés, Romberg and Tao [13,15,12] and Donoho [45] who constructed concrete algorithms and showed their promise in application.
Sparse approximation has been studied for nearly a century, and it has numerous applications. Temlyakov [111] locates the first example in a 1907 paper of Schmidt [104]. In the 1950s, statisticians launched an extensive investigation of another sparse approximation problem called subset selection in regression [87] and recently least angle regression [54,113]. Later, approximation theorists began a systematic study of m-term approximation with respect to orthonormal bases and redundant systems [38,111] and very recently in [25,26].
Over the last decade, the signal processing community spurred by the work of Coifman et al. [28,29] and Mallat et al. [84,37,36] has become interested in sparse representations for compression and analysis of audio [72], images [63] and video [90]. Sparsity criteria also arise in deconvolution [110], signal modeling [100], preconditioning [74], machine learning [70], de-noising [22], regularization [33,35] and error correction [16,19,60,58,59,61]. Most sparse approximation problems employ a linear model in which the collection of elementary signals is both linearly dependent and large. These models are often called redundant or overcomplete. Recent research suggests that overcomplete models offer a genuine increase in approximation power [95,62]. Unfortunately, they also raise a serious challenge. How do we find a good representation of the input signal among the plethora of possibilities? One method is to select a parsimonious or sparse representation. The exact rationale for invoking sparsity may range from engineering to economics to philosophy. At least three justifications are commonly given:
It is sometimes known a priori that the input signal can be expressed as a short linear combination of elementary signals also contaminated with noise.
The approximation may have an associated cost that must be controlled. For example, the computational cost of evaluating the approximation depends on the number of elementary signals that participate. In compression, the goal is to minimize the number of bits required to store the approximation.
Some researchers cite Occam’s Razor, “Pluralitas non est ponenda sine necessitate” (causes must not be multiplied beyond necessity).
Sparse approximation problems are computationally challenging because most reasonable sparsity measures are not convex. A formal hardness proof for one important class of problems independently appeared in [88] and [36]. A vast array of heuristic methods for producing sparse approximations have been proposed, but the literature contains few guarantees of their performance. The pertinent numerical techniques fall into at least three basic categories:
The convex relaxation approach replaces the nonconvex sparsity measure with a related convex function to obtain a convex programming problem. The convex program can be solved in polynomial time with standard software [8], and one expects that it will yield a good sparse approximation. More on that will be said in the sequel.
Greedy methods make a sequence of locally optimal choices in an effort to produce a good global solution to the approximation problem. This category includes forward selection procedures (such as matching pursuits), backward selection and others. Although these approaches sometimes succeed [31,67,69,68,115,117,118], they can also fail spectacularly [40,22]. The monographs of Miller [87] and Temlyakov [111] taste the many flavors of greedy heuristic.
Specialized nonlinear programming software has been developed that attempts to solve sparse approximation problems directly using, for example, interior point methods [96]. These techniques are only guaranteed to discover a locally optimal solution though.
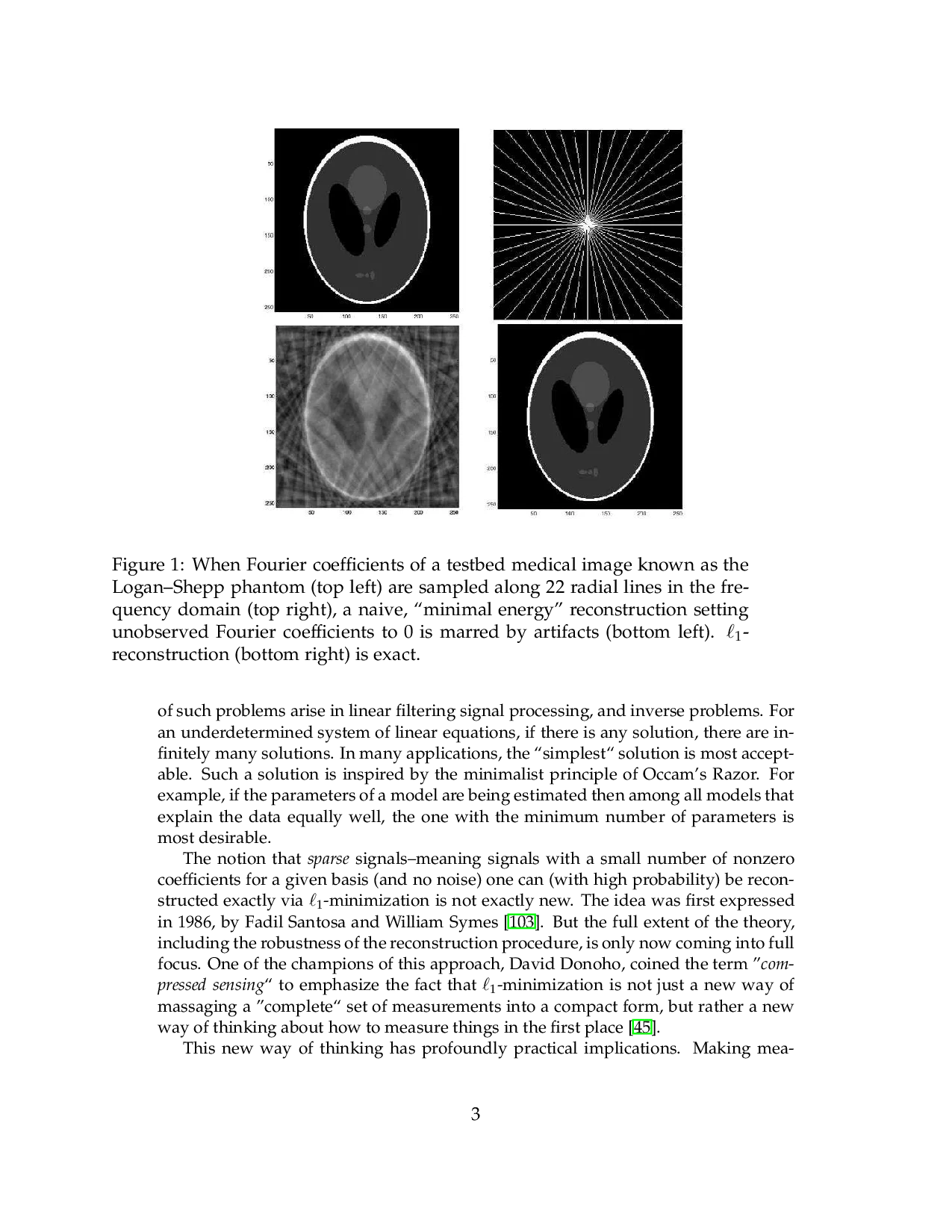
Several problems require solutions to be obtained from underdetermined systems of linear equations, i.e., systems with fewer equations than unknowns. Some example of such problems arise in linear filtering signal processing, and inverse problems. For an underdetermined system of linear equations, if there is any solution, there are infinitely many solutions. In many applications, the “simplest” solution is most acceptable. Such a solution is inspired by the minimalist principle of Occam’s Razor. For example, if the parameters of a model are being estimated then among all models that explain the data equally well, the one with the minimum number of parameters is most desirable. The notion that sparse signals-mean
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.