Efficient Human Computation
Collecting large labeled data sets is a laborious and expensive task, whose scaling up requires division of the labeling workload between many teachers. When the number of classes is large, miscorrespondences between the labels given by the different teachers are likely to occur, which, in the extreme case, may reach total inconsistency. In this paper we describe how globally consistent labels can be obtained, despite the absence of teacher coordination, and discuss the possible efficiency of this process in terms of human labor. We define a notion of label efficiency, measuring the ratio between the number of globally consistent labels obtained and the number of labels provided by distributed teachers. We show that the efficiency depends critically on the ratio alpha between the number of data instances seen by a single teacher, and the number of classes. We suggest several algorithms for the distributed labeling problem, and analyze their efficiency as a function of alpha. In addition, we provide an upper bound on label efficiency for the case of completely uncoordinated teachers, and show that efficiency approaches 0 as the ratio between the number of labels each teacher provides and the number of classes drops (i.e. alpha goes to 0).
💡 Research Summary
The paper addresses the problem of obtaining globally consistent labels for a large data set when the labeling workload is distributed among many teachers who do not coordinate with each other. When the number of classes is large, different teachers are likely to use different vocabularies, synonyms, or even different granularities for the same concept, leading to potential total inconsistency. The authors formalize this “distributed labeling” scenario and introduce a quantitative measure called label efficiency. Label efficiency f(α, alg) is defined as the ratio between the number of globally consistent labels that an algorithm alg can recover and the total number of labels supplied by the teachers. The key parameter α is the ratio l⁄c, where l is the number of instances each teacher labels and c is the total number of classes.
The paper first assumes that each teacher is internally self‑consistent (i.e., for any two instances the teacher labels the same, they truly belong to the same class) but that the naming of classes across teachers is completely uncoordinated. Under this assumption the authors propose two algorithms.
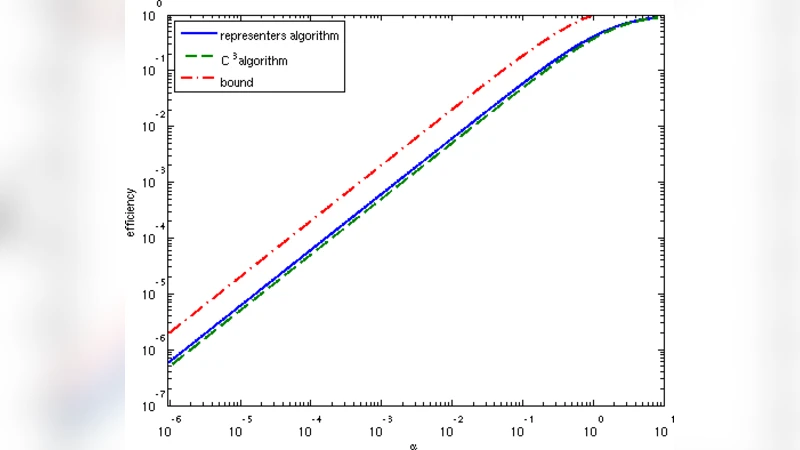
- C³ (Contradict the Connected Components) algorithm – The algorithm builds an initially empty graph whose vertices are the data instances. In each round a teacher is given a random set U of l vertices that do not yet form a clique. For every pair (i, j) in U the teacher’s response is examined: if the teacher assigns the same label to i and j, the two vertices are merged (contracted); otherwise an edge is added between them. The process repeats until the remaining graph becomes a clique. At that point each vertex receives a unique label, and the label is propagated back to all original instances that were merged into that vertex. The analysis shows that the expected number of distinct labels a teacher will produce on l random instances is at most l·Q(α) where Q(α) = (1 − e^{‑α})⁄α. Consequently the expected total number of teacher‑provided labels needed to finish is n·
Comments & Academic Discussion
Loading comments...
Leave a Comment