Estimating Signals with Finite Rate of Innovation from Noisy Samples: A Stochastic Algorithm
As an example of the recently-introduced concept of rate of innovation, signals that are linear combinations of a finite number of Diracs per unit time can be acquired by linear filtering followed by uniform sampling. However, in reality, samples are…
Authors: Vincent Y. F. Tan, Vivek K. Goyal
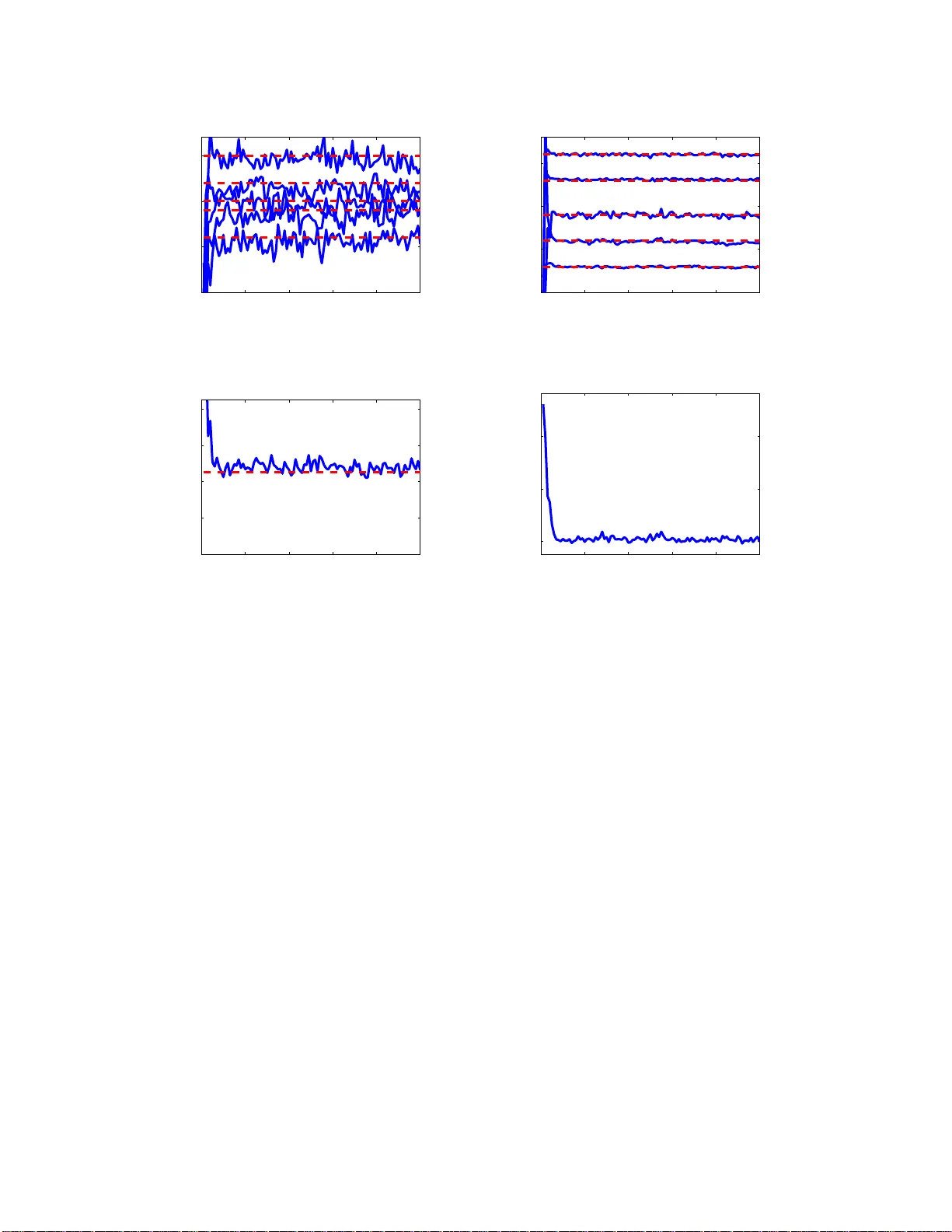
1 Estimating Signals with Fi nite Rate of Inno v ation f rom Noisy Samples: A Stochastic Al gorithm V incent Y . F . T an, Graduat e Student Member , IEEE, V iv ek K Goyal, S enior Member , IEEE Abstract As an example of the recently-intr oduced concept of rate of innovation, signals that are linear combinatio ns of a finite number o f Dir acs per unit time can be acquired by line ar filtering followed by unifor m sampling. Ho we ver , in reality , samples are r arely noiseless. In this paper, we introd uce a novel stochastic algorithm to reconstru ct a sign al with finite rate of innov ation from its noisy sam ples. Even though v ariants of t his problem has been approached previously , satisfactory so lutions are o nly available for certain classes of samp ling kernels, for example kernels which satisfy the Strang– Fix condition. In this paper, we consider the infinite-supp ort Gaussian kernel, which doe s not satisfy the Strang–Fix con dition. Other classes of kernels can be em ployed. Our algorithm is based o n Gibbs sampling , a Markov ch ain Monte Carlo (MCMC) method . Extensive numerical simulatio ns demon strate the accuracy and ro bustness of our alg orithm. Index T erms Analog-to -digital conv ersion, Gibbs sampling, Mar kov chain Monte Carlo, Samplin g. EDICS Categor ies: DSP-SAMP , SSP-P ARE V incent Y . F . T an (vtan@mit. edu) is wi th the Massachusetts Institute of T echnology , 77 Massachusetts A venu e, Rm. 32-D570, Cambridge, MA 02139, T el: 617-253-3816, Fax: 617-258-836 4. V incent T an is supported by the Agency for Science, T echnology and Research (A*ST AR), Singapore. V iv ek K Goyal (vgoyal@mit.edu) is with the Massach usetts Institute of T echnology , 77 Massachusetts A v enue, Rm. 36-690, Cambridge, MA 02139, T el: 617-324-0367, Fax: 617-32 4-4290. May 22, 2018 DRAFT 2 I . I N T RO D U C T I O N The celebrated Nyqu ist-Shannon sa mpling the orem [1], [2] 1 states that a signa l x ( t ) kn own to be bandlimited to Ω max is uniquely determined by samples o f x ( t ) spaced 1 / (2Ω max ) apart. The textbook reconstruction proce dure is to feed the samples as impu lses to a n idea l lowpass (s inc) filter . Furthermore, if x ( t ) is not b andlimited or the samp les are no isy , introducing pre-filtering by the app ropriate sinc sampling kernel gi ves a proce dure that finds the orthogonal projection to the spa ce of Ω max -bandlimited signals. Th us the noisy case is hand led by simple, linear , time-in variant p rocessing . Sampling has co me a long way since the sampling theo rem, b ut until recently the results h av e mo stly applied only to signals c ontained in shift-in vari ant sub space s [4]. Moving out of this restricti ve setting, V ett erli et al. [5] s howed that it is possible to develop sampling schemes for c ertain class es of non - bandlimited signals that are not subs paces . As described in [5], for reconstruction from samples it is neces sary for the class of signals to have finite rate of innovation (FRI). The paradigmatic example is the class of signals expres sed as x ( t ) = X k c k φ ( t − t k ) where φ ( t ) is s ome known function. For each term in the sum, the signal has two real pa rameters c k and t k . If the dens ity of t k s (the number that appear per unit of time) is fin ite, the signal has FRI. It is sh own constructively in [5] that the signa l can be recovered fr om (noise -less) u niform samples o f x ( t ) ∗ h ( t ) (at a sufficient rate) when φ ( t ) ∗ h ( t ) is a sinc or Gaussian function. Results in [6] are base d on s imilar reconstruction a lgorithms a nd greatly reduce the restrictions on the samp ling kernel h ( t ) . In prac tice, though, acq uisition of samp les is no t a nois eless process . For instance, an ana log-to-digital con verter (ADC) has sev e ral sources of noise, includ ing the rmal n oise, aperture unce rtainty , c omparator ambiguity , a nd quantization [7]. Henc e, s amples are inh erently n oisy . Th is motiv ates o ur central qu estion: Given the signal mod el (i.e . a signal with FRI) and the noise model, h ow well can we app r ox imate the parameters that de scribe the signal? In this work, we address this question an d d ev elop a novel algorithm to reconstruct the signal from the n oisy s amples, wh ich we will denote y [ n ] (see Fig. 1). A. Related W ork and Motivation Signals with FRI we re initially introdu ced b y V etterli et a l. [5]. The recons truction sche mes hinged on identifying algebraically-indep enden t parameters of the signa ls, e.g. the w eights { c k } and time locations 1 A more exp ansi ve term cou ld be the Whittaker -Nyquist-K otelnikov-Shan non sampling theorem; see, e.g., [3], [4]. May 22, 2018 DRAFT 3 h(t) + T y[n] z[n] z(t) x(t) e[n] C/D Fig. 1. Block diagram showin g our problem setup. x ( t ) is a signal wit h FRI gi ven by (1) and h ( t ) is the Gaussian fi lter with width σ h gi ven by (2). e [ n ] is i. i.d. Gaussian noise with standard de viation σ e and y [ n ] are the noisy samples. From y [ n ] we will estimate the parameters that describe x ( t ) , namely { c k , t k } K k =1 , and σ e , the standard deviation of the noise. { t k } . In the seminal pap er on FRI, the sampling kernel for finite signals was c hosen to be either the sinc or the Gaussian. An ann ihilating filter ap proach led to an elegant algebraic solution v ia polyn omial root finding a nd least squares. The au thors alluded to the noisy case and su ggested the use of the Singular V alue Deco mposition (SVD) for dealing w ith noisy samples. W e will show that, in fact, this method is ill-conditioned beca use root-finding is itself not at a ll robust to noise. Thus it is n ot amenable to prac tical implementations, for instance on a n ADC. Subseq uently , Dragotti et al. [6] examined acquisition of the same signals with an eye to ward im- plementability of the s ampling kernel. Instead of u sing the sinc a nd Gau ssian kernels (which do not have c ompact supp ort), the authors limit ed the choice of kernels to func tions satisfying the Strang–Fix conditions [8] ( e.g. s plines and scaling functions ), exponential splines [9] and functions with rational Fourier transforms. T hey combined the moment-sampling and annihilating filter app roaches to solve for the parame ters. In our work, howev er , we will con tinue to use the Gaussian as our sampling kernel. W e believe that, even though the Gauss ian has infinite support, it can be we ll approximated by its truncated version. Henc e, we c an still draw ins ights from the a nalysis of u sing Gaus sian filters a nd the subsequ ent reconstruction of the sign al from its noisy s amples y [ n ] . More importantly , unlike with previous a pproach es, the sampling kernel plays no fundamental role in the rec onstruction algorithm. W e use the Ga ussian kernel because of its prominence in earlier work and the intuiti veness of its information spreading properties. Maravic a nd V etterli [10] an d Ridolfi et al. [11] proposed and s olved a related p roblem. Instead of modeling the noise at the outpu t , they considered the scena rio where x ( t ) , the s ignal in ques tion, is corrupted by a dditi ve wh ite noise e ( t ) . Clearly , x e ( t ) = x ( t ) + e ( t ) does not belong to the c lass of signa ls with FRI. Howev er , in [10], novel algebraic/sub space -based approa ches s olve the sampling prob lem in May 22, 2018 DRAFT 4 the L aplace doma in and thes e method s ac hiev e some form o f optimality . In [11], various algorithms including su bspac e-based app roaches [12] ( ESPRIT and MUSIC ) as well as mu ltidimensional sea rch methods were us ed and comparisons w ere made. Th e autho rs conc luded that, in the noisy sign al cas e, the parameters can be recovered a t a rate below that prescribed by the Sha nnon-Nyqu ist Theorem but at a f actor above the critical rate . B. Our Contributions In our pape r , we solve a dif ferent problem. W e mode l the noise as additi ve noise to the acquired samples y [ n ] , not the signal x ( t ) . Bes ides, we use the Gauss ian s ampling ker nel a nd s how that the ill-conditioning of the problem can be effecti vely circumvente d. W e demons trate that und er these conditions, we are able to estimate the parameters via a fully Baye sian approach ba sed on Gibbs sampling (GS) [13 ], [14]. The prior methods are essentially algebraic while our algorithm is stochastic. As such, the maximization o f the log-lik elihood fun ction, whic h we will deri ve in Se ction III, is robust to initialization. More importantly , our algorithm is not constrained to work on the Gaussian kernel. Any kernel can be employed beca use the formulation of the Gibbs samp ler does not dep end on the specific form of the kernel h ( t ) . Finally , a ll the papers me ntioned failed to estimate the stand ard deviation of the noise process σ e . W e ad dress this issue in this paper . C. P aper Organization The rest of this paper is organized as follows: In Section II, we will formally state the p roblem and de fine the n otation to b e u sed in the rest of the paper . W e procee d to delinea te our algorithm: a stochastic optimization procedure based on Gibbs sampling, in Section III. W e report the res ults o f extensiv e numerical experiments in Sec tion IV. In Se ction IV, w e will also highlight some of the main deficienc ies in [5], which moti vate the need for new a lgorithms for recovering the parameters of a s ignal with FRI g i ven noisy samples y [ n ] . W e conclude ou r discuss ion in Section V and provide directions for further res earch. I I . P R O B L E M D E FI N I T I O N A N D N OTA T I O N The basic setup is sh own in Fig. 1. As mentione d in the introduction, we consider a class of signals characterized by a finite number of p arameters. In this pa per , similar to [5], [10], [6], the class is the May 22, 2018 DRAFT 5 weighted sum of K Diracs 2 x ( t ) = K X k =1 c k δ ( t − t k ) . (1) The signal to be es timated x ( t ) is filtered using a Gaussian low- pass filter h ( t ) = exp − t 2 2 σ 2 h (2) with width σ h to gi ve the signal z ( t ) . Even though h ( t ) doe s not hav e comp act support, it can be we ll approximated by a truncated Ga ussian, which d oes h ave co mpact suppo rt. The filtered signal z ( t ) is sampled at rate of 1 /T sec onds to obtain z [ n ] = z ( nT ) for n = 0 , 1 , . . . , N − 1 . Finally , additive white Gaussian noise (A WGN) e [ n ] is added to z [ n ] to gi ve y [ n ] . Therefore, the whole acq uisition p rocess from x ( t ) to { y [ n ] } N − 1 n =0 can be represe nted by the model M M : y [ n ] = K X k =1 c k exp − ( nT − t k ) 2 2 σ 2 h + e [ n ] (3) for n = 0 , 1 , . . . , N − 1 . The amount of noise added is a function of σ e . W e define the signa l-to-noise ratio (SNR) in dB as SNR △ = 10 log 10 P N − 1 n =0 | z [ n ] | 2 P N − 1 n =0 | z [ n ] − y [ n ] | 2 ! dB . In the se quel, we will us e bo ldface to denote vectors. In particular , y = [ y [0] , y [1] , . . . , y [ N − 1]] T , (4) c = [ c 1 , c 2 , . . . , c K ] T , (5) t = [ t 1 , t 2 , . . . , t K ] T . (6) W e will sometimes use θ = { c , t , σ e } to denote the complete set of decis ion variables. W e will be measuring the performance of our rec onstruction algorithms by u sing the normalized recon struction error E △ = R ∞ −∞ | z est ( t ) − z ( t ) | 2 dt R ∞ −∞ | z ( t ) | 2 dt , (7) where z est ( t ) is the reconstructed version of z ( t ) . By con struction E ≥ 0 and the closer E is to 0, the better the recons truction algorithm. In sum, the p roblem can be su mmarized as: Given y = { y [ n ] | n = 0 , . . . , N − 1 } and the model M , estimate the parameters { c k , t k } K k =1 to minimize E . Also estimate the noise variance σ 2 e . 2 The use of a Dirac delta simplifies the discussion. It can be replaced by a kno wn pulse g ( t ) and then absorbed into the sampling kern el h ( t ) , yielding an effec tiv e sampling kernel g ( t ) ∗ h ( t ) . May 22, 2018 DRAFT 6 I I I . P R E S E N T A T I O N O F T H E G I B B S S A M P L E R In this section, we will des cribe the stocha stic optimization proce dure b ased on G ibbs sampling to estimate θ = { c , t , σ e } . A. Gibbs Sampling (GS) Markov c hain Monte Carlo (MCMC) in the form of the Gibbs sa mpler , and the Metropolis-Hastings algorithm a llo ws any distrib ution to be simulated on a finite-dimensiona l state space spe cified by any conditional de nsity . The G ibbs sa mpler was first studied by the statistical p hysics c ommunity [15] and then later in the statistics community [13], [16], [17]. The basis for Gibb s samp ling is the Hammersley- Clif ford theorem [18] which states tha t given the d ata y , the conditional d ensities p i ( θ i | θ { j 6 = i } , y , M ) contain sufficient information to p roduce samples from the joint den sity p ( θ | y , M ) . Furthermore, the joint de nsity c an be directly deri ved from the conditional densities. Gibbs sampling has be en used extensi vely a nd succes sfully in image [13] an d audio restoration [14]. The Gibbs sampler is presented here to e stimate θ = { c , t , σ e } . T o simulate our Gibbs sa mpler , we us e the i.i.d. Gaussian noise a ssumption and the mode l in (3) to express the log-lik e lihood of the parameters giv e n the observations as: log p ( c , t , σ e | y , M ) ∝ − ( N + 1) log( σ e ) − 1 2 σ 2 e N − 1 X n =0 " y [ n ] − K X k =1 c k exp − ( nT − t k ) 2 2 σ 2 h # 2 . (8) A Jeff rey’ s (improper) non-informati ve prior h as been assigned to the standard de viation of the noise such tha t p ( σ e ) ∝ 1 σ e . (9) In the Gibbs s ampling algorithm, as s oon as a variate is drawn, it is inserted immediately into the conditional p.d.f. and it remains there un til being substituted in the next iteration. This is shown in the follo wing algorithm. 3 Require: y , I , I b , θ (0) = { c (0) , t (0) , σ (0) e } f or i ← 1 : I + I b do 3 For brevity , the dependence on the model M is omitted from the conditional density expressions. May 22, 2018 DRAFT 7 c ( i ) 1 ∼ p ( c 1 | c ( i − 1) 2 , c ( i − 1) 3 , . . . , c ( i − 1) K , t ( i − 1) σ ( i − 1) e , y ) c ( i ) 2 ∼ p ( c 2 | c ( i ) 1 , c ( i − 1) 3 , . . . , c ( i − 1) K , t ( i − 1) σ ( i − 1) e , y ) . . . ∼ . . . c ( i ) K ∼ p ( c K | c ( i ) 1 , c ( i ) 2 , . . . , c ( i ) K − 1 , t ( i − 1) , σ ( i − 1) e , y ) t ( i ) 1 ∼ p ( t 1 | c ( i ) , t ( i − 1) 2 , t ( i − 1) 3 , . . . , t ( i − 1) K , σ ( i − 1) e , y ) t ( i ) 2 ∼ p ( t 2 | c ( i ) , t ( i ) 1 , t ( i − 1) 3 , . . . , t ( i − 1) K , σ ( i − 1) e , y ) . . . ∼ . . . t ( i ) K ∼ p ( t K | c ( i ) , t ( i ) 1 , t ( i ) 2 , . . . , t ( i ) K − 1 , σ ( i − 1) e , y ) σ ( i ) e ∼ p ( σ e | c ( i ) , t ( i ) , y ) end for Compute ˆ θ MMSE using (10) return ˆ θ MMSE In the algorithm, ϑ ∼ ¯ p ( · ) mea ns that ϑ is a random draw from ¯ p ( · ) . The superscript numbe r ( i ) denotes the current iteration. After I b iterations 4 the Markov chain a pproximately reach es its stationary distrib ution p ( θ | y , M ) . Minimum mean squared error (MMSE) estimates can then b e approximated by taking averages of the s amples from the next I iterations { θ ( I b +1) , θ ( I b +2) , . . . , θ ( I b + I ) } , i.e. , ˆ θ MMSE = Z θ p ( θ | y , M ) d θ ≈ 1 I I b + I X i = I b +1 θ ( i ) . (10) B. Presentation of the P o sterior De nsities in the GS W e will n ow d eriv e the co nditional d ensities. In the s equel, we will use the notation θ − ℓ to de note the set of parameters excluding the ℓ th parameter . It follows from Bayes’ theorem that p ( θ ℓ | θ − ℓ , y , M ) ∝ p ( y | θ , M ) p ( θ ) . (11) Thus, the required conditional d istrib utions a re prop ortional to the likeli hood of the data times the priors on the parameters. The likelihood function of y given the model is gi ven in (8) from the Gaussian noise assumption. Thus, we can c alculate the posterior distrib utions of the parameters gi ven the rest of the parameters. T he parameters c onditioned on are taken as constan t and c an be left out of the posterior . W e will s ample from these posterior den sities in the GS iterations as sh own in the above algorithm. W e will now proc eed to present the posterior densities. The deri vations are provided in the Append ix. 4 I b is also commonly known as the bu rn-in period in t he Gibbs sampling and MCMC literature [14]. May 22, 2018 DRAFT 8 1) S ampling c k : c k is sa mpled from a Gaussian distribution given by p ( c k | θ − c k , y , M ) = N c k ; − β k 2 α k , 1 2 α k , (12) where α k △ = 1 2 σ 2 e N − 1 X n =0 exp − ( nT − t k ) 2 σ 2 h , (13) β k △ = 1 σ 2 e N − 1 X n =0 exp − ( nT − t k ) 2 2 σ 2 h · K X k ′ =1 k ′ 6 = k c k ′ exp − ( nT − t k ′ ) 2 2 σ 2 h − y [ n ] . (14) It is eas y to sample from Gaussian densities when the p arameters ( α k , β k ) h av e be en dete rmined. 2) S ampling t k : t k is sa mpled from a distrib ution of the form p ( t k | θ − t k , y , M ) ∝ exp " − 1 2 σ 2 e N − 1 X n =0 γ k exp − ( nT − t k ) 2 σ 2 h + ν k exp − ( nT − t k ) 2 2 σ 2 h # (15) where γ k △ = c 2 k , (16) ν k △ = 2 c k K X k ′ =1 k ′ 6 = k c k ′ exp − ( nT − t k ′ ) 2 2 σ 2 h − y [ n ] . (17) It is no t straightforward to sample from this d istrib ution. W e ca n samp le t k from a uniform grid of discrete values with prob ability mas ses propo rtional to (15). B ut in prac tice, an d for greater accuracy , we us ed rejection samp ling [19], [20] to g enerate sa mples t ( i ) k from p ( t k | θ − t k , y , M ) . The proposal d istrib ution ˜ q ( t k ) was c hosen to b e an appropriately s caled Gaus sian, since it is easy to sample from Gaussian s. This is shown in the follo wing algorithm. Require: ˜ p ( t k ) △ = p ( t k | θ − t k , y , M ) Select ˜ q ( t k ) ∼ N and c s.t. ˜ p ( t k ) < c ˜ q ( t k ) u ∼ U (0 , 1) May 22, 2018 DRAFT 9 6 8 10 12 0 50 100 150 Hist of c 1 (i) after convergence True value of c 1 = 10 (a) Histogram of the samples of c ( i ) 1 8 8.5 9 9.5 10 0 50 100 150 200 Hist of t 1 (i) after convergence True value of t 1 = 9 (b) Histogram of the samples of t ( i ) 1 Fig. 2. Note that the v ariance of the st ationary distribution of the t k s is smaller than that of the c k s after con vergen ce of the Marko v chain. repeat t k ∼ ˜ q ( t k ) until u < ˜ p ( t k ) / ( c ˜ q ( t k )) 3) S ampling σ e : σ e is sampled from the ‘ Square-root In verted-Gamma’ [ 21] distr ib ution I G − 1 / 2 ( σ e ; ϕ, λ ) 5 , p ( σ e | θ − σ e , y , M ) = 2 λ ϕ σ − (2 ϕ +1) e Γ( ϕ ) exp − λ σ 2 e I [0 , + ∞ ) ( σ e ) , (18) where ϕ △ = N 2 , (19) λ △ = 1 2 " y [ n ] − K X k =1 c k exp − ( nT − t k ) 2 2 σ 2 h # 2 . (20) Thus the distribution of the vari ance o f the noise σ 2 e is In verted Ga mma, which correspon ds to the conjugate prior of σ 2 e in the expression of N ( e ; 0 , σ 2 e ) [21] and thus it is easy to sa mple from. In our simulations, we s ampled from this de nsity using the Matlab function gamrnd and a pplied the ‘In verted Square-root’ transformation C. Fur ther Impr ovements via Linear Le ast S quares E stimation W e can perform an additional post-proce ssing step to improve on the es timates of c k . W e noted from our preliminary experiments ( see Fig. 2) that the variance of the stationary distri buti on of the t k s is smaller 5 X follows a ‘Square-root In verted-Gamma’ distribution if X − 2 follo ws a Gamma distribution. May 22, 2018 DRAFT 10 Param. K σ e N SNR V alue 5 0 and 10 − 6 30 ∞ and 137 dB T ABLE I P A R A M E T E R V A L U E S F O R D E M O N S T R AT I O N O F T H E A N N I H I L A T I N G FI LT E R A N D R O OT - FI N D I N G A L G O R I T H M . than that o f the c k s. Th is results in better estimates for the locations t k s as compared to the magnitudes c k s. Now , we ob serve that y [ n ] , the observations, are linear in the c k s once the t k s are known. A n atural extension to our GS a lgorithm is to a ugment o ur c k estimates with a linear leas t sq uares estimation (LLSE) procedure using y and the MMSE estimates of t k . Eqn. (3) can be written as y [ n ] = K X k =1 c k h ( nT − t k ) + e [ n ] , 0 ≤ n ≤ N − 1 (21) with h ( t ) , the Gaus sian samp ling kernel, given in (2). Given the set of e stimates of the time locations { ˆ t k } K k =1 , we can re write (21 ) as a matrix equation, giving y = Hc + e , where [ H ] nk = h ( nT − ˆ t k ) and 1 ≤ n ≤ N , 1 ≤ k ≤ K . W e now minimize the squa re of the residual k e k 2 = k Hc − y k 2 , gi ving the normal equations H T Hc = H T y and the least squares so lution [22] ˆ c LS = ( H T H ) − 1 H T y . (22) From our experiments, we found tha t, in gen eral, using ˆ c LS as estimates for the ma gnitudes of the impulses provided a lower reco nstruction e rror E . I V . N U M E R I C A L R E S U L T S A N D E X P E R I M E N T S In this section, w e will first review the annihilating filter and root-finding me thod algorithm for s olving for the parame ters o f a signa l with FRI. This algorithm provides a base line for c omparison. Then we will provide extensive simulation results to v alidate the a ccuracy of the algorithm w e p roposed in Section III. A. Pr oblems with Annihilating F ilter an d Ro ot-F inding In [5], V etterli et a l. introduced the concept o f a class of s ignals with a fin ite rate of innov a tion. For signals o f the form (1) and certain s ampling kernels, the ann ihilating filter was used as a means to locate the t k values. Sub seque ntly a leas t squa res approach yielded the weights c k . It was sh own that in the May 22, 2018 DRAFT 11 −20 −10 0 10 20 −5 0 5 10 15 20 σ e = 0, E = 4.49e−10 z(t) z est (t) (a) The annihilating filter approach reconstructs the signal e xactly in the noiseless scenario. −20 −10 0 10 20 −5 0 5 10 15 20 σ e = 1e−6, E = 0.2721 z(t) z est (t) (b) The reconstruction completely breaks do wn when noise of a small standard deviation σ e = 10 − 6 (SNR=137 dB) is added . Fig. 3. Demonstration of the annihilating filter/root-finding approach. noiseless sce nario, this method recovers the parame ters exa ctly (se e Fig. 3(a)). For completenes s, we will briefly ou tline the ir me thod h ere. De noting the noise less samples by z [ n ] , (3) ca n be writt en as p [ n ] = K X k =1 a k u n k , n = 0 , 1 , . . . , N − 1 , (23) with the identifications p [ n ] = exp( n 2 T 2 / (2 σ 2 h )) z [ n ] , (24) a k = c k exp( − t 2 k / (2 σ 2 h )) , (25) u k = exp( t k T /σ 2 h ) . (26) Now , s ince p [ n ] is a linear combination o f expo nentials, we find the annihilating filter a [ n ] such that a [ n ] ∗ p [ n ] = K X ℓ =0 a [ ℓ ] p [ n − ℓ ] = 0 , ∀ n ∈ Z . This can b e written in matrix/vector form a s P a = 0 . This sy stem will admit a s olution when rank ( P ) = K . In p ractice this is solved using an SVD where P = UΣV T and a = V e K +1 and e K +1 is a length- ( K + 1 ) vector with 1 in position ( K + 1) and 0 elsewhere. Now , once the coef ficients a [ n ] a re found, the v alues u k are simply the roots of the filter A ( z ) = K X n =0 a [ n ] z − n . The t k s can then be determined from (25) and the solution for the c k s esse ntially parallels the development in Section III-C. May 22, 2018 DRAFT 12 In the same p aper , it was sugges ted that to deal with the noisy samples, we can minimize k P a k , in which ca se, a is the eige n vector that corresp onds to the smallest eige n value of P T P . Here, we argue that this method is inherently ill-conditioned and thus not rob ust to noise. 1) Firstly , minimizing k P a k in volv es find ing the eigen vector v 1 that corresponds to the largest eigen- value λ 1 . Because c omputing eigen values and e igen vectors a re es sentially roo t-finding operations, this is ill-conditioned. 2) Secondly , ev en if the vector a = v 1 can be found, the zeros of the filter A ( z ) have to be found . This again in volves root finding, which is ill-conditioned. 3) Finally , from (24), any noise ad ded to z [ n ] will be exponentially we ighted in the observations p [ n ] . W e feel that this is the greatest s ource o f ill-conditioning. Becaus e of the three reaso ns high lighted above, there is a ne ed to explore new algorithms for finding the parameters. In Fig. 3, we s how a simulation with the parameters as ta bulated in T able I , but we varied the noise ( σ e = 10 − 6 giv e s SNR = 137 dB, a very low n oise level) . W e observe from Fig. 3(b) tha t (without oversampling) the an nihilating filter and root-finding method is not rob ust ev e n when a minisc ule amount of noise is added. Remark The roo t-finding method is s o uns table that, at times, even for low levels of noise, we obtain complex roots for the locations { t k } K − 1 k =0 . T o solve this problem, we orthogo nally projected the polynomial described by the filter coefficients a [ n ] to the closest polynomial that belongs to the space of po lynomials with rea l roo ts only . B. P erformance of our GS Algorithm Clearly , the a nnihilating filter/root-finding a lgorithm is not robust to noise. W e h ave sug gested an alternati ve reconstruction algorithm in Sec tion III, and in this s ection, we will present our results o n several s ynthetic examples. 6 1) Initial Demonstration: T o de monstrate the ev olution the Gibbs sampler , we performed an initial experiment and chos e the pa rameters to be those in T able I, with the exception that the noise stan dard deviation was increased to σ e = 2 . 5 , gi ving an SNR of 10 . 2 dB. W e plot the iterates in Fig. 4. The true filtered signa l z ( t ) and its es timate z est ( t ) are plotted in Fig. 5. W e note the close similarity b etween z ( t ) and z est ( t ) . 6 All the code, w ritten in MA TLAB, can be found at the first author’ s homepage http://web.mit.edu/vtan/frimcmc. May 22, 2018 DRAFT 13 0 20 40 60 80 100 0 5 10 15 c k Iteration (a) Evolution of the c k s 0 20 40 60 80 100 0 5 10 15 t k Iteration (b) Evolution of the t k s 0 20 40 60 80 100 0 1 2 3 4 σ e Iteration (c) Evolution of the σ e 0 20 40 60 80 100 150 200 250 −log(p) Iteration (d) Reduction of the (negati ve) log-likeliho od − log p ( c , t , σ e | y , M ) Fig. 4. Evolution of the GS algorithm. The iterates of the parameters { c k , t k } K k =1 and σ e are shown. The true values are indicated by t he broken red l ines. In Fig. 4(d), we see t hat the negati ve log-likelihoo d con verges to the global minimum i n fewer than 20 iterations for this problem size ( K = 5 ). W e observe that the s ampler con verges in fe we r than 2 0 iterations for t his r un, e ven thou gh t he parameter values were initialized f a r from their o ptimal v a lues. W e emphasize that as GS is es sentially a s tochastic optimization procedure (not unlike Simulated Annea ling or Genetic Algorithms), it is insensitive to the choice of starting point θ (0) . The Markov Chain is guaranteed to con ver g e to the s tationary distrib ution after the burn-in period [19]. 2) Fu rther Experiments: T o further validate our algorithm, we performed extensi ve simulations (Ex pts A an d B) on two diff erent p roblem s izes to v a lidate our algo rithm. For c onsistency , ea ch experiment was repeated using 100 different ran dom seed s a nd the means of E [cf. (7)] taken. The p arameters are chosen acc ording to T able II. The unknown p arameters we re initialized as c (0) = t (0) = [0 , . . . , 0] an d σ (0) e = 0 . 01 . Th e results for Expts A an d B are shown in Fig. 7(a) and 7(b) respectiv ely . W e noted from May 22, 2018 DRAFT 14 −5 0 5 10 15 20 25 0 5 10 15 20 z(t) z est (t) Fig. 5. Comparison between z ( t ) and z est ( t ) using the G S algorithm. For this run, E = 0 . 0072 . Param. K σ e N SNR E Expt A 5 1.5:0.25:3.0 50:25:150 Fig 6(a) Fig 7(a) Expt B 10 3.0 :0.50:6.0 100:50:250 Fig 6(b) Fig 7(b) T ABLE II P A R A M E T E R V A L U E S F O R N U M E R I C A L S I M U L A T I O N S . these experiments that: • T he GS algorithm is insensitiv e to initialization. It always finds approximately optimal estimates from any starting point because the Marko v cha in provably con verges to the stationary distrib ution [19]. • T he LLSE p ost-process ing step in the GS algorithm reduce s the reconstruction error E . This is a 1.5 2 2.5 3 8 10 12 14 16 σ e SNR (dB) (a) SNR (dB) against σ e for Expt A ( K = 5 ). 3 4 5 6 8 10 12 14 16 σ e SNR (dB) (b) SNR (dB) against σ e for Expt B ( K = 10 ). Fig. 6. SNR (dB) against σ e for the two experiments. May 22, 2018 DRAFT 15 1.5 2 2.5 3 0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 σ e E N=50 N=75 N=100 N=125 (a) Errors E against σ e for Expt A ( K = 5 ). 3 3.5 4 4.5 5 5.5 6 0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 σ e E N=100 N=150 N=200 N=250 (b) Errors E against σ e for Expt B ( K = 10 ). Fig. 7. Plots of E against σ e for va rious ov ersampling fac tors and problem sizes. conseq uence of using the (more accurate) t k s from the sampler to e stimate the c k s via LLS E, inste ad of using the c k s from the sampler d irectly . • F rom the two plots in Fig. 7 , we obse rve tha t, if the problem size do ubles (from K = 5 to K = 10 ), with correspo nding do ubling of ( σ e , N ) , E remains a pproximately cons tant. Th is insures sca lability of the a lgorithm. For example, E ( K = 5 , σ e = 2 . 5 , N = 50) ≈ E ( K = 10 , σ e = 5 . 0 , N = 100) ≈ 0 . 045 . • T he noise s tandard deviation σ e can be e stimated a ccurately in the GS algorithm as s hown in Fig. 4(c). This may be important in s ome applica tions. T o conclude, even though the annihilating filter approach [5] is more computationally e f ficient than our algorithms, it is certainly n ot ame nable to scena rio where noisy samples are a cquired. V . C O N C L U S I O N S In this paper , w e ad dresse d the problem of reconstructing a signal with F RI given noisy samples . W e showed that it is possible to circumvent some of the problems of the ann ihilating fi lter an d root-finding approach [5]. W e introduced the Gibbs sampling a lgorithm. From the performance plots, we observe tha t GS performs very well as c ompared to the annihilating filter method, which is not robust to noise . Perhaps the most important observation we made is the follo wing: The succ ess o f the fully Bayesian GS algorithm does not d epend on the c hoice of kernel h ( t ) . Th e formulati on of the GS does not depend on the specific form of h ( t ) . In f act, we used a Gaussian sampling kernel to illustrate tha t our algorithm is not restricted to the classe s of kernels considered in [6]. A natural extension to our work here is to assign structured priors to c , t and σ e . These priors can May 22, 2018 DRAFT 16 themselves be depen dent on their own set of hyper parameters , giving a hierarchica l Bayesian formulation. In this way , there would be greater flexibility in the paramete r estimation process . W e can also see k to improv e on the computationa l loa d of the a lgorithms introduced h ere. Another interesting research direction is to examine the feasibility of using the sub space -based app roaches [10] to solve the problem of acquired samples that a re no isy . A q uestion tha t remains is: How well can r eal-world signals (includ ing natural images) be modeled as signals with FRI? W e believe the answer will hav e profound ramifications for a reas s uch as sparse approximation [23] and compresse d sensing [24], [25]. A P P E N D I X D E R I V A T I O N O F T H E C O N D I T I O NA L D E N S I T I E S For brevity , we define g nk △ = h ( nT − t k ) = exp − ( nT − t k ) 2 2 σ 2 h . W e start from the log-likelihood of the parameters θ giv e n the data y and model M [cf. (8) ]. T o obtain p ( c k | θ − c k , y , M ) , we treat the o ther parameters θ − c k as cons tant, gi ving log p ( c k | θ − c k , y , M ) proportional to − 1 2 σ 2 e N − 1 X n =0 c 2 k g 2 nk + 2 c k g nk K X k ′ =1 k ′ 6 = k c k ′ g nk ′ − y [ n ] . Comparing this expression in c k to the Gaus sian distributi on with me an µ and v a riance σ 2 , log p ( c k ; µ, σ 2 ) ∝ − 1 2 σ 2 ( c k − µ ) 2 , and equating coefficients, we o btain (13) and (14). The distrib ution p ( t k | θ − t k , y , M ) c an be obtained similarly and is omitted. Finally for the noise standard deviation σ e , log p ( σ e | θ − σ e , y , M ) ∝ − ( N + 1) log ( σ e ) − λ σ 2 , where λ is defined in (20). T aking the antilog on bo th sides yields p ( σ e | θ − σ e , y , M ) ∝ σ − ( N +1) e exp − λ σ 2 , which is the ‘Square-root In verted-Gamma’ distribution with parameters gi ven by (19) and (20 ). All the densities ha ve been de ri ved. May 22, 2018 DRAFT 17 R E F E R E N C E S [1] C. E. S hannon, “Communication in the presence of noise, ” Proc. Institute of Radio E ngineers , vol. 37, no. 1, pp. 10–21, Jan. 1949. [2] H. Nyquist, “Certain topics in telegrap h t ransmission theory , ” T rans. American Institute of Electrical Engineers , vol. 47, pp. 617–644 , Apr . 1928. [3] A. J. Jerri, “The Shannon sampling theorem—its v arious extensions and applications: A tutorial revie w , ” Proc. IE EE , vol. 65, pp. 1565–159 6, No v . 1977. [4] M. Unser , “Sampling–50 years after S hannon, ” Pr oc. IEEE , vol. 88, no. 4, pp. 569–587 , 2000. [5] M. V ett erli, P . Marziliano, and T . Blu, “Sampling si gnals with finite rate of innov ation, ” IEEE T rans. Signal Proce ssing , vol. 50, no. 6, pp. 1417–14 28, 2002. [6] P . L. Dragotti, M. V etterli , and T . Blu, “Sampling moments and reconstructing signals of finite rate of innov ation: Shannon meets Strang–Fix, ” IEEE T rans. Signal Pro cessing , vol. 55, no. 5, pp. 174 1–1757 , 2007 . [7] R. H. W alden, “ A nalog-to-digital conv erter surv ey and analysis, ” IEEE J. Selected Areas of Communication , vol. 17, no. 4, pp. 539–550 , Apr . 1999. [8] G. Strang and G. Fix, “ A Fou rier analysis of the finite element v ariational method, ” Constructive Aspects of Functional Analysis , pp. 796–8 30, 1971. [9] M. Unser and T . Blu, “Cardinal expon ential splines: Part I – Theory and filtering algorithms, ” IEEE T rans. Signal Pr ocessing , vol. 53, no. 4, pp. 1425–14 38, Apr . 2005. [10] I. Maravic and M. V etterli, “Sampling and reconstruction of signals wi th finite r ate of innov ation in the presence of noise, ” IEEE T rans. Signal Process ing , vol. 53, no. 8, pp. 2788– 2805, 200 5. [11] A. Ridolfi, I. Maravic, J. Kusuma, and M. V etterli, “Sampling signals wi th fi nite rate of innov ation: T he noisy case, ” P r oc. IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) , 2002. [12] P . Stoica and R. Moses, Intr oduction to Spectr al Analysis . Prentice Hall, 1997. [13] S. Geman and D. Geman, “St ochastic relaxation, Gibbs distributions and the Bayesian restoration of images, ” IEE E T rans. P attern Analysis and Machine Intelligence , vol. 6, pp. 721 –741, 1984. [14] S. J. Godsill and P . J. W . Rayner , Di gital Audio Restoration: A Statistical Model Based Appr oach . S pringer-V erlag, 1998. [15] N. Metropolis, A. W . Rosenbluth, M. N. Rosenbluth, A. H. T eller , and W . T eller , “Equations of state calculations by fast computing machines, ” J . Chemical Physics , vol. 21, pp. 1087–1091, 1953. [16] W . K. Hastings, “Monte Carlo sampling methods using Markov chains and their applications, ” Biometrica , vol. 57, pp. 97–109 , 1970. [17] W . J. Fit zgerald, S. J. Godsill, A. C. Kok aram, and J. A. Stark, Bayesian Methods in Signal and Image Proc essing . Oxford Univ . Press, 1999, ch. Bayesian Statistics. [18] J. M. Hammersley and M. S. Cli fford , “Mark ov fields on finite graphs and lattices, ” Unpublished , 1970. [19] L. Tiern ey , “Markov chains for exploring posterior distributions, ” School of Statisti cs, Uni v . of Minnesota, T ech. Rep. 560, Mar . 1994. [20] C. P . Robert and G. Casella, Monte Carlo Statisti cal Methods , 2nd ed. New Y ork: S pringer-V erlag, 2004 . [21] J. M. Bernardo and A. F . M. Smith, Bayesian Theory , 1st ed. W iley , 2001. [22] G. Strang, Intr oduction to Linear Al gebr a , 3rd ed. W ellesley Cambridge P ress, 2001. [23] D. L. Donoho, M. V et terli, R. A. DeV ore, and I. Daubech ies, “Data compression and harmon ic analysis, ” IEEE T rans. Information Theory , vo l. 44, no. 6, pp. 2435–2476 , Oct. 1998 . May 22, 2018 DRAFT 18 [24] D. L. Donoho, “Compressed sensing, ” IEEE T rans. Information Theory , vol. 52, no. 4, pp. 1289–13 06, Apr . 2006 . [25] E. J. Cand ` es and T . T ao, “Near -optimal si gnal recov ery from random projections: Uni versal encoding strategies?” IEEE T rans. Information T heory , vol. 52, no. 12, pp. 5406– 5425, Dec. 2006. May 22, 2018 DRAFT
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment