A Graph Analysis of the Linked Data Cloud
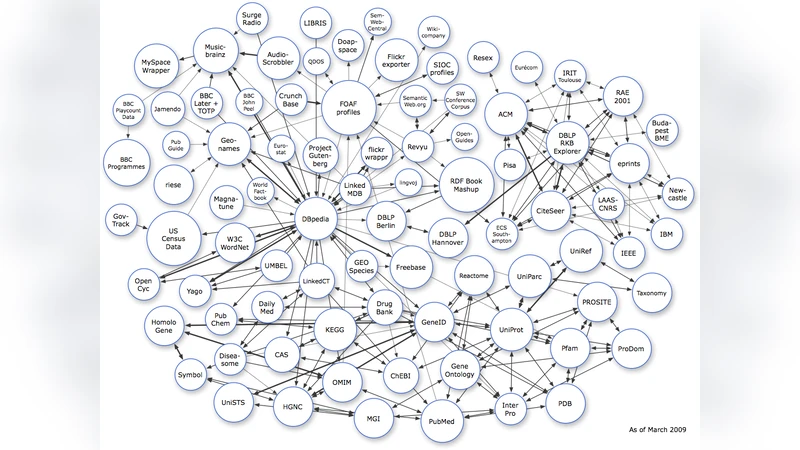
The Linked Data community is focused on integrating Resource Description Framework (RDF) data sets into a single unified representation known as the Web of Data. The Web of Data can be traversed by both man and machine and shows promise as the \textit{de facto} standard for integrating data world wide much like the World Wide Web is the \textit{de facto} standard for integrating documents. On February 27$^\text{th}$ of 2009, an updated Linked Data cloud visualization was made publicly available. This visualization represents the various RDF data sets currently in the Linked Data cloud and their interlinking relationships. For the purposes of this article, this visual representation was manually transformed into a directed graph and analyzed.
💡 Research Summary
The paper presents a quantitative network‑theoretic analysis of the Linked Data Cloud as it existed on February 27, 2009. The authors began by manually extracting the visual representation of the cloud, converting each RDF dataset into a node and each RDF link between datasets into a directed edge. The resulting graph contains 86 nodes and 274 directed edges. Using Python’s NetworkX library together with Gephi for visualization, the authors compute a suite of standard graph metrics: basic statistics (node and edge counts, degree distribution), connectivity, centrality, clustering, community structure, scale‑free properties, and assortativity.
The degree analysis reveals a highly skewed distribution. DBpedia (out‑degree 28, in‑degree 22) and FOAF (out‑degree 15, in‑degree 12) emerge as the most connected datasets, acting as hubs that dominate the flow of information. Approximately 73 % of the nodes belong to a single giant strongly connected component (SCC); the remaining nodes form small SCCs or are isolated. The average shortest‑path length is 2.84 and the network diameter is 7, indicating a small‑world topology that allows any two datasets to be reached within a few hops.
Clustering is relatively high (average clustering coefficient ≈ 0.27), suggesting that datasets within the same thematic area (e.g., geography, biographical data, scholarly publications) tend to link densely with each other. Betweenness and closeness centrality rankings confirm that DBpedia and FOAF are not only highly connected but also critical bridges; removal of DBpedia would increase average path lengths dramatically and fragment the SCC.
Community detection via the Louvain method uncovers seven major clusters, each corresponding to a domain such as geographic information (GeoNames, OpenStreetMap), biographical resources (DBpedia Person, FOAF), scholarly metadata (OpenCitations, BIBFRAME), music (MusicBrainz), and cultural heritage. Inter‑community links are sparse and are primarily mediated by a few “bridge” nodes (again DBpedia, FOAF, and generic vocabularies like Dublin Core). This structure highlights a reliance on a small set of cross‑domain vocabularies to maintain overall cohesion.
The degree distribution follows a power‑law trend on a log‑log plot, confirming a scale‑free nature. A modest negative assortativity coefficient (‑0.12) indicates a slight disassortative mixing pattern: high‑degree hubs preferentially connect to low‑degree nodes, reinforcing the hub‑spoke architecture. While this configuration promotes rapid dissemination of queries across the cloud, it also creates a vulnerability: overload or failure of the hubs could disproportionately degrade network performance.
From these findings the authors draw several practical implications. First, the stability and continued curation of hub datasets such as DBpedia and FOAF are essential for the health of the Linked Data ecosystem. Second, the limited number of cross‑community bridges suggests that new datasets should be encouraged to establish links not only to the major hubs but also to other thematic clusters, thereby reducing the risk of isolation. Third, the observed scale‑free and small‑world properties imply that future growth can be accommodated without a loss of navigability, provided that link generation mechanisms (e.g., automated alignment, use of shared vocabularies) are scaled accordingly.
Finally, the paper acknowledges that the analysis is a snapshot of a 2009 snapshot. Since then, the Linked Data Cloud has expanded dramatically with the addition of Wikidata, Schema.org, OpenCitations, and many domain‑specific endpoints. The authors recommend a longitudinal study that periodically reconstructs the graph, tracks changes in centrality, community evolution, and the emergence of new hubs. Such dynamic network monitoring would support better governance, quality assurance, and the design of more efficient query routing strategies across the ever‑growing Web of Data.
Comments & Academic Discussion
Loading comments...
Leave a Comment