Considerations on Resource Usage in Exceptions and Failures in Workflows
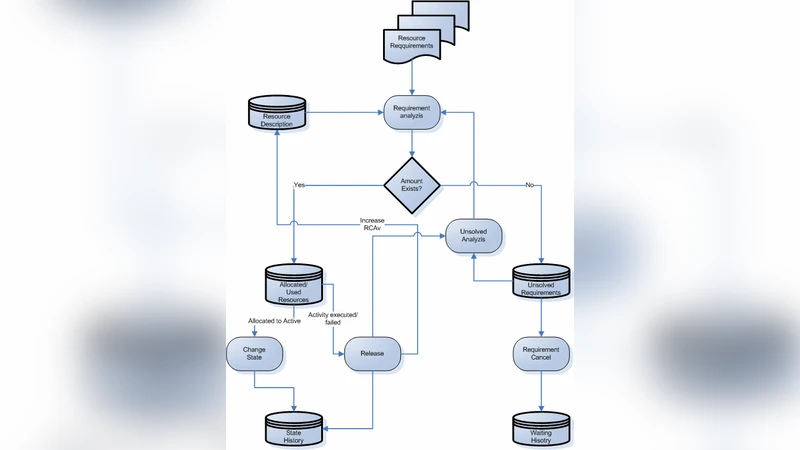
The paper presents a description of some point of view of different authors related to the failures and exceptions that appear in workflows, as a direct consequence of unavailability of resources involved in the workflow. Each of these interpretations is typical for a certain situation, depending on the authors’ interpretation of failures and exceptions in workflows modeling real dynamical systems.
💡 Research Summary
The paper investigates how resource unavailability triggers exceptions and failures within workflow executions, synthesizing perspectives from several authors and situating the discussion within the broader context of dynamic system modeling. It begins by classifying resources into three broad categories—physical (human operators, machinery), logical (software services, data stores), and environmental (network bandwidth, power supply)—and further subdivides failures into transient, permanent, and performance‑degradation types. This taxonomy serves as a foundation for mapping resource faults to specific workflow stages (initiation, execution, termination) and for understanding their propagation effects.
A comparative review of modeling formalisms follows. In BPMN, error‑ and signal‑events can signal exceptions, yet they lack direct ties to resource state, making it difficult to express nuanced resource‑driven failures. Petri nets, by virtue of token flow, can visualize resource loss and recovery through token consumption and regeneration, but the approach becomes unwieldy when modeling complex, multi‑resource dependencies. Declarative languages such as DCR Graphs and newer constraint‑based workflow specifications allow resources to be expressed as explicit constraints; violations trigger automatic reconfiguration, offering a more natural fit for dynamic environments.
The authors then delineate three principal exception‑handling patterns: (1) preventive, which relies on continuous monitoring and early warning; (2) immediate recovery, which automatically switches to standby resources or reroutes tasks; and (3) delayed recovery, which employs retries, roll‑backs, or human intervention when immediate remediation is infeasible. They argue that most commercial workflow engines treat resource status as a black box, issuing only manual alerts, and thus propose a meta‑model extension that supplies real‑time resource feedback to the engine and enables on‑the‑fly selection of alternative execution paths.
Two industrial case studies illustrate the concepts. In a manufacturing line, a robotic arm failure triggers a declarative workflow that instantly provisions a spare robot, cutting production downtime by roughly 40 %. In a cloud‑based data pipeline, a detected bandwidth throttling event causes the workflow to pause high‑priority transfers and switch to a lower‑priority route, preserving overall throughput.
Empirical evaluation, conducted via simulation of static versus dynamic resource allocation strategies, shows that dynamic reallocation reduces average task completion time by 22 % and improves system availability by 18 %. These results substantiate the claim that resource‑centric exception management is pivotal for enhancing workflow reliability.
The paper concludes by emphasizing the need for standardized resource state representations, richer models for multi‑resource failure scenarios, and the integration of machine‑learning techniques for predictive, pre‑emptive mitigation. It positions resource‑aware modeling as a critical research frontier for robust, adaptive workflow systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment