Marginal Likelihood Integrals for Mixtures of Independence Models
Inference in Bayesian statistics involves the evaluation of marginal likelihood integrals. We present algebraic algorithms for computing such integrals exactly for discrete data of small sample size. Our methods apply to both uniform priors and Diric…
Authors: Shaowei Lin, Bernd Sturmfels, Zhiqiang Xu
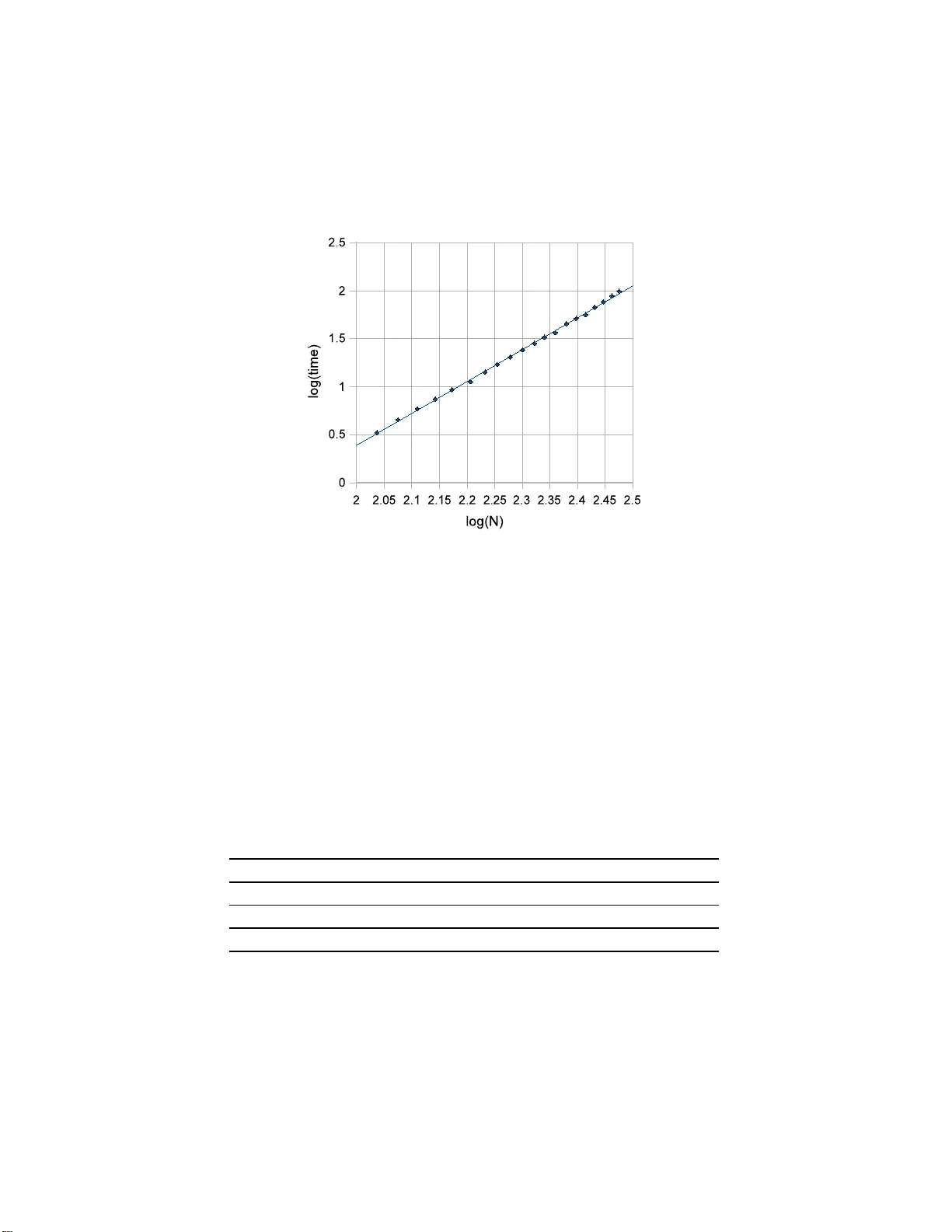
Marginal Lik eliho o d I ntegrals for Mix tu res of I n dep endence Mo del s Shaow ei Lin, Ber nd Stur m fels a n d Zhiqi a ng Xu Abstract Inference in Ba yesia n statistics in volv es the ev aluation of marginal lik eliho o d in tegrals. W e pr esen t algebraic algorithms for computin g suc h in tegrals exactly for discrete data of s mall sample size. Our meth- o ds apply to b oth uniform priors and Diric h let priors. T he underlying statistica l mo dels are mixtures of indep end en t distributions, or, in ge- ometric language, secan t v arieties of S egre-V eronese v arieties. Keyw ords: marginal l ikelihoo d , exact in tegration, mixtur e of inde- p end ence m o del, computational algebra 1 In tro ducti on Ev aluation of margina l likelihoo d integrals is central to Bay esian statistics . It is g enerally assumed that these in tegrals cannot b e ev aluated exactly , except in trivial cases, and a wide range of nume rical tec hniques (e.g. MCMC) hav e b een dev elop ed to obtain asymptotics and n umerical appro ximations [1 ]. The aim of this pap er is to show that exact integration is more feasible than is surmised in the literature. W e examine marginal lik eliho o d integrals fo r a class of mixture mo dels for discrete data. Bay esian inf erence for these mo d- els arises in many con texts, including machine learning and computational biology . Recen t w or k in these fields has made a connection to singularities in algebraic geometry [3, 9, 14, 15, 16]. O ur study augments these dev elopmen ts b y pro viding to ols for sy mbolic in tegra t io n when the sample size is small. The nume r ical v alue of the in tegral w e ha ve in mind is a rational num b er, and exact ev aluation means computing that rational num b er rather than a 1 floating p oin t appro ximation. F or a first example consid er the in tegral Z Θ Y i,j ∈{ A , C , G , T } π λ (1) i λ (2) j + τ ρ (1) i ρ (2) j U ij dπ dτ d λ dρ, (1) where Θ is the 13- dimensional p olytop e ∆ 1 × ∆ 3 × ∆ 3 × ∆ 3 × ∆ 3 . The factors are probability simplices, i.e. ∆ 1 = { ( π , τ ) ∈ R 2 ≥ 0 : π + τ = 1 } , ∆ 3 = { ( λ ( k ) A , λ ( k ) C , λ ( k ) G , λ ( k ) T ) ∈ R 4 ≥ 0 : P i λ ( k ) i = 1 } , k = 1 , 2 , ∆ 3 = { ( ρ ( k ) A , ρ ( k ) C , ρ ( k ) G , ρ ( k ) T ) ∈ R 4 ≥ 0 : P i ρ ( k ) i = 1 } , k = 1 , 2 . and w e in tegra te with resp ect to Leb esgue probability measure on Θ. If w e tak e the exp onen ts U ij to b e the en tr ies of the particular contingenc y table U = 4 2 2 2 2 4 2 2 2 2 4 2 2 2 2 4 , (2) then the exact v alue of the in tegra l (1) is the rational n um b er 571 · 773 4 26813 · 1768 20395969 93 · 62501542643 2626533 2 31 · 3 20 · 5 12 · 7 11 · 11 8 · 13 7 · 17 5 · 19 5 · 23 5 · 29 3 · 31 3 · 37 3 · 41 3 · 43 2 . (3) The particular table (2) is tak en from [12, Example 1.3], where the integrand Y i,j ∈{ A , C , G , T } π λ (1) i λ (2) j + τ ρ (1) i ρ (2) j U ij (4) w as studied using the EM algorithm, and the problem o f v alidating its global maxim um ov er Θ w as ra ised. See [6, § 4.2] and [13, § 3] for further discussions. That opt imizatio n problem, whic h w as widely kno wn as the 100 Swiss F r ancs pr oblem , has in the mean time b een solv ed b y Gao, Jiang and Z h u [8]. The main difficult y in p erforming computations such as (1) = (3) lies in the fact t hat the expansion of the integrand has many terms. A first naiv e upp er b ound o n the n um b er of monomials in the ex pansion of (4) w ould b e Y i,j ∈{ A , C , G , T } ( U ij + 1) = 3 12 · 5 4 = 332 , 150 , 625 . 2 Ho we ver, the true n um b er of monomials is o nly 3 , 892 , 0 9 7, and w e obt a in the rational num b er (3) b y summing the v a lues of the corresponding in tegrals Z Θ π a 1 τ a 2 ( λ (1) ) u ( λ (2) ) v ( ρ (1) ) w ( ρ (2) ) x dπ dτ d λ dρ = a 1 ! a 2 ! ( a 1 + a 2 +1)! · 3! Q i u i ! ( P i u i + 3)! · 3! Q i v i ! ( P i v i + 3)! · 3! Q i w i ! ( P i w i + 3)! · 3! Q i x i ! ( P i x i + 3)! . The geometric idea b ehind our a pproac h is that the Newton polytop e of (4 ) is a zo notop e and w e are summing ov er the lattice p oints in that zonoto p e. Definitions fo r these geometric ob jects are given in Section 3. This pap er is orga nized as follows. In Section 2 w e describe the class of algebraic statistical mo dels to which our metho d applies, and w e sp ecify the problem. In Section 3 we examine the Newton zonotop es of mixture mo dels, and we deriv e form ula s for marginal lik eliho o d ev aluation using to ols from geometric com binato rics. Our algorithms and their implemen tations are described in detail in Section 4 . Section 5 is concerne d with applications in Ba ye sian statistics. W e show ho w D irichlet priors can b e incorp ora ted in to our approac h, w e discuss the ev aluation of B ayes factors , w e compare our setup with that o f Chic k ering and Heck erman in [1], and w e illustrate the scop e of o ur metho ds b y computing an integral arising f r om a data set in [5]. A preliminary draf t v ersion of the presen t article w as publishe d as Section 5.2 of the Ob erwolfac h lecture notes [4]. W e refer to that volume for further information on the use of computational a lgebra in Bay esian statistics. 2 Indep ende nce Mo dels and thei r Mixt ures W e consider a collection of discrete r a ndom v ariables X (1) 1 , X (1) 2 , . . . , X (1) s 1 , X (2) 1 , X (2) 2 , . . . , X (2) s 2 , . . . . . . . . . . . . X ( k ) 1 , X ( k ) 2 , . . . , X ( k ) s k , where X ( i ) 1 , . . . , X ( i ) s i are identic a lly distributed with v alues in { 0 , 1 , . . . , t i } . The indep endence mo del M for these v ariables is a toric mo del [12, § 1.2] 3 represen ted b y a n integer d × n -matrix A with d = t 1 + t 2 + · · · + t k + k and n = k Y i =1 ( t i + 1) s i . (5) The columns of the matrix A are indexed b y elemen ts v of the state space { 0 , 1 , . . . , t 1 } s 1 × { 0 , 1 , . . . , t 2 } s 2 × · · · × { 0 , 1 , . . . , t k } s k . (6) The rows of the matrix A ar e indexed b y the mo del parameters, whic h are the d coo r dina t es of the p oin ts θ = ( θ (1) , θ (2) , . . . , θ ( k ) ) in the p olytop e P = ∆ t 1 × ∆ t 2 × · · · × ∆ t k , (7) and the mo del M is the subset of the simplex ∆ n − 1 giv en parametrically b y p v = Prob X ( i ) j = v ( i ) j for all i, j = k Y i =1 s i Y j =1 θ ( i ) v ( i ) j . (8) This is a monomial in d unkno wns. The matrix A is defined b y taking its column a v to b e the exp onen t v ector of this monomial. In algebraic geometry , the mo del M is kno wn as Se gr e-V er onese variety P t 1 × P t 2 × · · · × P t k ֒ → P n − 1 , (9) where the em b edding is giv en b y the line bundle O ( s 1 , s 2 , . . . , s k ). The man- ifold M is the t oric v ariet y of the p olytop e P . Both ob jects ha v e dimens ion d − k , and they are iden tified with eac h other via the momen t map [7, § 4]. Example 2.1. Consider three binary random v ariables where the last t w o random v ariables are iden tically distributed. In o ur notation, this corresponds to k = 2 , s 1 = 1, s 2 = 2 and t 1 = t 2 = 1. W e find that d = 4 , n = 8, and A = p 000 p 001 p 010 p 011 p 100 p 101 p 110 p 111 θ (1) 0 1 1 1 1 0 0 0 0 θ (1) 1 0 0 0 0 1 1 1 1 θ (2) 0 2 1 1 0 2 1 1 0 θ (2) 1 0 1 1 2 0 1 1 2 . 4 The columns of this matrix represen t the monomials in the parametrization (8). The mo del M lies in the 5-dimensional subsimplex of ∆ 7 giv en b y p 001 = p 010 and p 101 = p 110 , and it consists of all rank one matrices p 000 p 001 p 100 p 101 p 010 p 011 p 110 p 111 . In algebraic geometry , the surface M is called a r ation al normal scr ol l . The ma t rix A has rep eated columns whenev er s i ≥ 2 for some i . It is sometimes con venie nt to represen t the mo del M b y the matrix ˜ A whic h is obtained from A b y removin g rep eated columns. W e lab el the columns of the matrix ˜ A b y elemen ts v = ( v (1) , . . . , v ( k ) ) of (6) whose comp onen ts v ( i ) ∈ { 0 , 1 , . . . , t i } s i are w eakly increasing. Hence ˜ A is a d × ˜ n -matrix with ˜ n = k Y i =1 s i + t i s i . (10) The mo del M and its mixtures are subsets of a subsimplex ∆ ˜ n − 1 of ∆ n − 1 . W e no w in tro duce ma r ginal likeliho o d inte gr als . All our do ma ins of in te- gration in this pap er are p o lytop es that are pro ducts of standard probability simplices. On each suc h p olytop e w e fix the standard Leb esgue probability measure. In other w ords, o ur discuss io n of Bay esian inference refers to the uniform prior on eac h parameter space. Natura lly , other prio r distributions, suc h as Dirichlet priors, are of in terest, a nd o ur metho ds are extended to these in Sec t io n 5. In what follo ws, w e simply w ork with uniform prior s. W e identify t he state space (6) with the set { 1 , . . . , n } . A data ve ctor U = ( U 1 , . . . , U n ) is th us an elemen t of N n . The sample size of these data is U 1 + U 2 + · · · + U n = N . If the sample size N is fixed then the probability of observing t hese data is L U ( θ ) = N ! U 1 ! U 2 ! · · · U n ! · p 1 ( θ ) U 1 · p 2 ( θ ) U 2 · · · · · p n ( θ ) U n . This expres sion is a function on the p olytop e P whic h is know n as the like- liho o d function of the data U with resp ect to the indep endence mo del M . The mar ginal likeliho o d of the data U with respect to the model M equals Z P L U ( θ ) dθ . 5 The v alue of this integral is a rational num b er whic h we no w compute explic- itly . The data U will en ter t his calculation b y w a y of the sufficient statistic b = A · U , whic h is a v ector in N d . The co o rdinates of this v ector are denoted b ( i ) j for i = 1 , . . . , k and j = 0 , . . . , t k . Th us b ( i ) j is the total num b er of times the v alue j is attained b y one of the r a ndom v ariables X ( i ) 1 , . . . , X ( i ) s i in the i -th group. Clearly , the sufficien t statistics satisfy b ( i ) 0 + b ( i ) 1 + · · · + b ( i ) t i = s i · N for all i = 1 , 2 , . . . , k . (11) The lik eliho o d function L U ( θ ) is the constant N ! U 1 ! ··· U n ! times the monomial θ b = k Y i =1 t i Y j =0 ( θ ( i ) j ) b ( i ) j . The logarithm o f this function is conca ve on the p olytop e P , and its maxi- m um v alue is attained at the p oin t ˆ θ with co ordinates ˆ θ ( i ) j = b ( i ) j / ( s i · N ). Lemma 2.2. The in tegral of the monomial θ b o ve r the polytop e P equals Z P θ b dθ = k Y i =1 t i ! b ( i ) 0 ! b ( i ) 1 ! · · · b ( i ) t i ! ( s i N + t i )! . The pro duct of this num b er with the m ultinomial co efficien t N ! / ( U 1 ! · · · U n !) equals the marginal lik eliho o d of the data U for the indep endence mo del M . Pr o of. Since P is the pro duct of sim plices (7), this follo ws fro m the fo rm ula Z ∆ t θ b 0 0 θ b 1 1 · · · θ b t t dθ = t ! · b 0 ! · b 1 ! · · · b t ! ( b 0 + b 1 + · · · + b t + t )! (12) for the in tegral of a monomial ov er the standard probability simplex ∆ t . Our ob j ective is to compute marginal lik eliho o d in tegrals for the mixture mo del M (2) . The natural parameter space of this model is the polytop e Θ = ∆ 1 × P × P . Let a v ∈ N d b e the column v ector of A indexed b y the state v , whic h is either in (6) or in { 1 , 2 , . . . , n } . The parametrization (8 ) can be written simply as 6 p v = θ a v . The mixture mo del M (2) is defined to be the subset of ∆ n − 1 with the parametric represen tation p v = σ 0 · θ a v + σ 1 · ρ a v for ( σ, θ , ρ ) ∈ Θ . (13) The lik eliho o d function of a data ve cto r U ∈ N n for the mo del M (2) equals L U ( σ , θ , ρ ) = N ! U 1 ! U 2 ! · · · U n ! p 1 ( σ , θ , ρ ) U 1 · · · p n ( σ , θ , ρ ) U n . (14) The mar ginal likeliho o d o f the data U with resp ect to the mo del M (2) equals Z Θ L U ( σ , θ , ρ ) dσ dθ dρ = N ! U 1 ! · · · U n ! Z Θ Y v ( σ 0 θ a v + σ 1 ρ a v ) U v dσ dθ d ρ. (15) The following prop osition sho ws that w e can ev aluate this in tegral exactly . Prop osition 2.3. The mar ginal likeliho o d (1 5) is a r ational numb er. Pr o of. The lik eliho o d function L U is a Q ≥ 0 -linear com binatio n of monomials σ a θ b ρ c . The integral (15) is the same Q ≥ 0 -linear com binatio n of the num b ers Z Θ σ a θ b ρ c dσ dθ dρ = Z ∆ 1 σ a dσ · Z P θ b dθ · Z P ρ c dρ . Eac h of the t hr ee factors is an easy-to- ev aluate rational num b er, b y ( 12). Example 2.4. The in tegral (1) expresse s the margina l lik eliho o d of a 4 × 4 - table of coun ts U = ( U ij ) with respect to the mixture mo del M (2) . Sp ecifi- cally , the marginal lik eliho o d of the data (2) equals the normalizing constan t 40! · (2!) − 12 · (4!) − 4 times the n um b er (3). The mo del M (2) consists of all non-negativ e 4 × 4- matrices of rank ≤ 2 whose en tries sum to one. Here the para metrization ( 13) is not iden tifiable b ecause dim( M (2) ) = 11 but dim(Θ) = 13. In this example, k = 2, s 1 = s 2 =1, t 1 = t 2 =3, d = 8, n = 16. In algebraic geometry , the mo del M (2) is kno wn a s the first secan t v ariet y of the Segre-V eronese v ariet y (9 ). W e could also consider the higher secan t v arieties M ( l ) , whic h corresp ond to mixtures of l indep enden t distributions, and muc h of our analysis can b e extended to that case, but for simplicit y w e restrict ourselv es to l = 2. The v ariet y M (2) is embedded in the pro jectiv e space P ˜ n − 1 with ˜ n as in (10). Note that ˜ n can b e m uc h smaller than n . If this is the case then it is con v enient to aggregate states whose probabilities a re iden tical and to repres ent the data by a vec to r ˜ U ∈ N ˜ n . Here is a n example. 7 Example 2.5. Let k =1, s 1 =4 and t 1 =1, so M is the indep endence mo del for four identic ally distributed binary random v ariables. Then d = 2 and n = 1 6. The corresp onding in teger matrix and its ro w and column lab els are A = p 0000 p 0001 p 0010 p 0100 p 1000 p 0011 · · · p 1110 p 1111 θ 0 4 3 3 3 3 2 · · · 1 0 θ 1 0 1 1 1 1 2 · · · 3 4 . Ho we ver, t his matrix has only ˜ n = 5 distinct columns, and w e instead use ˜ A = p 0 p 1 p 2 p 3 p 4 θ 0 4 3 2 1 0 θ 1 0 1 2 3 4 . The mixture mo del M (2) is the subs et of ∆ 4 giv en b y the parametrization p i = 4 i · σ 0 · θ 4 − i 0 · θ i 1 + σ 1 · ρ 4 − i 0 · ρ i 1 for i = 0 , 1 , 2 , 3 , 4. In alg ebraic geometry , this threefold is the secan t v a r iet y of the ratio nal normal curv e in P 4 . This is the cubic h yp ersurface with the implicit equation det 12 p 0 3 p 1 2 p 2 3 p 1 2 p 2 3 p 3 2 p 2 3 p 3 12 p 4 = 0 . In [11, Example 9] the lik eliho o d function (14) w as studied for the dat a v ector ˜ U = ( ˜ U 0 , ˜ U 1 , ˜ U 2 , ˜ U 3 , ˜ U 4 ) = (51 , 1 8 , 73 , 25 , 75) . It has t hree lo cal maxima (mo dulo sw apping θ and ρ ) whose co ordinates are algebraic n umbers of degree 12. Using the metho ds to b e describ ed in the next t w o sections, we computed the exact v alue of the marg inal lik eliho o d for the data ˜ U with respect t o M (2) . The rational n um b er ( 1 5) is found to be the ratio of tw o relativ ely prime in t egers hav ing 530 digits and 5 52 digits, and its n umerical v alue is appro ximately 0 . 778 87163388 3867861 1 335742 · 10 − 22 . 3 Summation o v er a Zon otop e Our starting p oin t is the observ ation that the Newton p olytop e of the lik e- liho o d function (14) is a zonotop e. Recall that the Newton p olytop e of a 8 p olynomial is the con ve x h ull of a ll exp onen t ve ctors app earing in the ex- pansion of that p olynomial, and a p o lytop e is a zonotop e if it is the image of a standard cub e under a linear map. See [2, § 7] a nd [17, § 7] for further discussions . W e are here considering the zonotop e Z A ( U ) = n X v =1 U v · [0 , a v ] , where [0 , a v ] represen ts t he line segmen t b et we en the or ig in and the p o in t a v ∈ R d , and the sum is a Mink ows ki sum of line segmen ts. W e write Z A = Z A (1 , 1 , . . . , 1) for the basic zonotop e whic h is spanned b y the ve cto r s a v . Hence Z A ( U ) is obtained by stretc hing Z A along those ve ctors by factors U v resp ectiv ely . Assuming that the coun ts U v are all po sitiv e, w e ha v e dim( Z A ( U )) = dim( Z A ) = rank( A ) = d − k + 1 . (16) The zonotop e Z A is related to the p olytop e P = con v ( A ) in (7) a s fo llows. The dimension d − k = t 1 + · · · + t k of P is one less than dim( Z A ), and P app ears a s the vertex figur e of the zonotop e Z A at the distinguished vertex 0. Remark 3.1. F or hig her mixtures M ( l ) , the Newton p olytop e o f the lik e- liho o d function is isomorphic to the Mink ow ski sum of ( l − 1)- dimensional simplices in R ( l − 1) d . O nly when l = 2, this Mink ows ki sum is a zonotop e. The mar g inal lik eliho o d (15) w e wish to compute is the in tegral Z Θ n Y v =1 ( σ 0 θ a v + σ 1 ρ a v ) U v dσ d θ dρ (17) times the constant N ! / ( U 1 ! · · · U n !). Our a ppro ac h to this computation is to sum ov er the lattice p oints in the zonoto p e Z A ( U ). If the matrix A has rep eated columns, w e ma y replace A with the reduced matrix ˜ A and U with the corresp onding reduced data ve ctor ˜ U . If one desires the mar g inal lik eliho o d for the reduced data v ector ˜ U instead of the o r ig inal data vector U , the in tegral remains the same while the normalizing constant b ecomes N ! ˜ U 1 ! · · · ˜ U ˜ n ! · α ˜ U 1 1 · · · α ˜ U ˜ n ˜ n , where α i is the num b er of columns in A equal to the i -th column o f ˜ A . In what follows w e ignore the normalizing constan t and fo cus o n computing the in tegral (17) with respect to the original matrix A . 9 F or a ve ctor b ∈ R d ≥ 0 w e let | b | denote its L 1 -norm P d t =1 b t . Recall fro m (8) that all columns of the d × n -matrix A ha v e the same coo r dinate sum a := | a v | = s 1 + s 2 + · · · + s k , f o r all v = 1 , 2 , . . . , n, and from (11) that we ma y denote the en tries of a vec tor b ∈ R d b y b ( i ) j for i = 1 , . . . , k and j = 0 , . . . , t k . Also, let L denote the image of the linear map A : Z n → Z d . Th us L is a sublattice of ra nk d − k + 1 in Z d . W e abbreviate Z L A ( U ) := Z A ( U ) ∩ L . No w, using the binomial theorem, w e hav e ( σ 0 θ a v + σ 1 ρ a v ) U v = U v X x v =0 U v x v σ x v 0 σ U v − x v 1 θ x v · a v ρ ( U v − x v ) · a v . Therefore, in the expans io n of the in tegrand in (17), the exp onen ts o f θ a r e of the form of b = P v x v a v ∈ Z L A ( U ) , 0 ≤ x v ≤ U v . The other exp onen ts ma y be express ed in terms of b . This giv es us n Y v =1 ( σ 0 θ a v + σ 1 ρ a v ) U v = X b ∈ Z L A ( U ) c = AU − b φ A ( b, U ) · σ | b | /a 0 · σ | c | /a 1 · θ b · ρ c . (18) W riting D ( U ) = { ( x 1 , . . . , x n ) ∈ Z n : 0 ≤ x v ≤ U v , v = 1 , . . . , n } , w e can see that the co efficien t in ( 1 8) equals φ A ( b, U ) = X Ax = b x ∈ D ( U ) n Y v =1 U v x v . (19) Th us, b y fo r mulas (12) and (18), the in tegral (17) ev aluates to X b ∈ Z L A ( U ) c = AU − b φ A ( b, U ) · ( | b | /a )! ( | c | /a )! ( | U | + 1)! · k Y i =1 t i ! b ( i ) 0 ! · · · b ( i ) t i ! ( | b ( i ) | + t i )! t i ! c ( i ) 0 ! · · · c ( i ) t i ! ( | c ( i ) | + t i )! ! . (2 0 ) W e summarize the result of this deriv ation in the f ollo wing theorem. Theorem 3.2. T h e mar ginal likeliho o d of the data U in the mix tur e mo del M (2) is e qual to the sum (20) times the normalizing c onstant N ! / ( U 1 ! · · · U n !) . 10 Eac h individual summand in the form ula (20) is a ratio of factor ia ls and hence can b e ev aluated sym b olically . The c hallenge in turning Theorem 3.2 in to a pra ctical algorithm lies in the fact that b o th o f the sums (19) and (20) are o ver v ery large sets. W e shall discuss these challenges and presen t tec hniques from b oth computer science and mathematics for a ddressing them. W e first t ur n our atten tion to the co efficien ts φ A ( b, U ) of the expansion (18). These quantities are written as an explicit sum in (1 9). The first useful observ ation is that these co efficien ts ar e also the co efficien ts of the expansion Y v ( θ a v + 1) U v = X b ∈ Z L A ( U ) φ A ( b, U ) · θ b , (21) whic h comes from substituting σ i = 1 and ρ j = 1 in (18). When the cardi- nalit y of Z L A ( U ) is sufficien tly small, the quan tit y φ A ( b, U ) can be compute d quic kly b y expanding (21) using a computer algebra system. W e used Maple for this purpo se and all other sym b olic computations in this pro ject. If the expansion (2 1) is not feasible, then it is tempting to compute the individual φ A ( b, U ) via the sum-pro duct formula ( 19). This metho d requires summation ov er the set { x ∈ D ( U ) : Ax = b } , whic h is t he set of lattice p oin ts in an ( n − d + k − 1)-dimensional p olytop e. Ev en if this loo p can b e implemen ted, p erforming the sum in (19) sym b olically requires the ev aluation of many la rge binomia ls, whic h causes the pro cess to be rather inefficien t. An alternative is offered b y the follow ing recurrence form ula: φ A ( b, U ) = U n X x n =0 U n x n φ A \ a n ( b − x n a n , U \ U n ) . (22) This is equiv alent to writing the integrand in (17) as n − 1 Y v =1 ( σ 0 θ a v + σ 1 ρ a v ) U v ! ( σ 0 θ a n + σ 1 ρ a n ) U n . More generally , for eac h 0 < i < n , we ha ve the recurrenc e φ A ( b, U ) = X b ′ ∈ Z L A ′ ( U ′ ) φ A ′ ( b ′ , U ′ ) · φ A \ A ′ ( b − b ′ , U \ U ′ ) , where A ′ and U ′ consist of the first i columns and en tries of A and U resp ec- tiv ely . This corresponds to the factorization i Y v =1 ( σ 0 θ a v + σ 1 ρ a v ) U v ! n Y v = i +1 ( σ 0 θ a v + σ 1 ρ a v ) U v ! . 11 This for mula gives flexibilit y in designing algorithms with differen t pa yoffs in time and space complexity , to b e discuss ed in Section 4. The next result records use f ul facts ab out the quan tities φ A ( b, U ). Prop osition 3.3. Supp ose b ∈ Z L A ( U ) and c = AU − b . T h e n, the fol low i n g quantities ar e al l e qual to φ A ( b, U ) : (1) # z ∈ { 0 , 1 } N : A U z = b , wher e A U is the extende d matrix A U := ( a 1 , . . . , a 1 | {z } U 1 , a 2 , . . . , a 2 | {z } U 2 , . . . , a n , . . . , a n | {z } U n ) , (2) φ A ( c, U ) , (3) X Ax = b l j ≤ x j ≤ u j n Y v =1 U v x v , wher e u j = min { U j } ∪{ b m /a j m } n m =1 and l j = U j − min { U j } ∪{ c m /a j m } n m =1 . Pr o of. (1 ) This follo ws directly from (21). (2) F or each z ∈ { 0 , 1 } N satisfying A U z = b , note that ¯ z = ( 1 , 1 , . . . , 1) − z satisfies A U ¯ z = c , and vice v ersa. The conclu sion th us follows from ( 1 ). (3) W e require Ax = b and x ∈ D ( U ). If x j > u j = b m /a j m then a j m x j > b m , whic h implies Ax 6 = b . The low er b o und is deriv ed b y a similar argumen t. One asp ect of our a pproac h is the decision, for any given mo del A a nd data set U , whether or not t o attempt the expansion (21) using computer algebra. This decision dep ends on the cardinalit y of the set Z L A ( U ). In what follo ws, w e compute the n um b er exactly whe n A is unimo dular. When A is not unimo dular, w e obtain useful lo w er and upp er b ounds for # Z L A ( U ). Let S b e any subset of the columns of A . W e call S indep endent if its elemen ts are linearly independen t in R d . With S w e asso ciat e the inte ger index( S ) := [ R S ∩ L : Z S ] . This is t he index of the ab elian group generated b y S inside the p ossibly larger ab elian group of all lattice p oints in L = Z A that lie in the span of S . The following for m ula is due t o R. Stanley a nd app ears in [10, Theorem 2 .2 ]: Prop osition 3.4. T h e numb er of lattic e p oints in the zonotop e Z A ( U ) e quals # Z L A ( U ) = X S ⊆ A indep . index( S ) · Y a v ∈ S U v . (23) 12 In f a ct, the n umber of monomials in (18) equals # M A ( U ), where M A ( U ) is t he set { b ∈ Z L A ( U ) : φ A ( b, U ) 6 = 0 } , and this set can b e differen t from Z L A ( U ). F o r that n um b er w e hav e the follow ing upp er and lo wer b ounds. The pro of of Theorem 3.5 will b e omitted here. It uses the methods in [10, § 2]. Theorem 3.5. The numb er # M A ( U ) of monom ials i n the exp ansion (18) of the likeliho o d f unction to b e inte gr ate d satisfies the two ine qualities X S ⊆ A indep . Y v ∈ S U v ≤ # M A ( U ) ≤ X S ⊆ A indep . index( S ) · Y v ∈ S U v . ( 2 4) By definition, the matrix A is unimo dular if index( S ) = 1 for a ll indep en- den t subs ets S of t he columns of A . In this case, the upp er bound coincides with the low er b ound, and so M A ( U ) = Z L A ( U ). This happ ens in the classical case of tw o-dimensional contingency tables ( k = 2 and s 1 = s 2 = 1). In gen- eral, # Z L A ( U ) / # M A ( U ) tends to 1 when all co ordinates o f U tend to infinity . This is wh y w e b eliev e that # Z L A ( U ) is a go o d a ppro ximation o f # M A ( U ). F or computatio nal purp oses, it suffices to kno w # Z A ( U ). Remark 3.6. There exist integer matrices A for whic h # M A ( U ) do es not agree with the upp er b ound in Theorem 3.5. How ev er, we conjecture that # M A ( U ) = # Z L A ( U ) holds for matrices A of Segre-V eronese type as in (8) and strictly po sitiv e data v ectors U . Example 3.7. Consider the 100 Swiss F r ancs example in Section 1. Here A is unimo dular and it has 16145 indep enden t subsets S . The corresp onding sum of 16 145 squarefree monomials in (23) give s the num ber of terms in the expansion of (4). F or the data U in (2) this sum ev aluates to 3 , 89 2 , 097. Example 3.8. W e consider the matrix and data from Example 2.5. ˜ A = 0 1 2 3 4 4 3 2 1 0 ˜ U = 51 , 18 , 73 , 25 , 75 By Theorem 3.5, the low er b ound is 22,273 and the upp er b ound is 4 8,646. Here the n um b er # M ˜ A ( ˜ U ) o f monomials agrees with the latter. W e next presen t a form ula for index( S ) when S is a ny linearly indepen- den t subset of the columns of the matrix A . Aft er relab eling we may assume 13 that S = { a 1 , . . . , a k } consists of the first k columns of A . Let H = V A denote the row Hermite normal form of A . Here V ∈ S L d ( Z ) and H satisfies H ij = 0 for i > j and 0 ≤ H ij < H j j for i < j. Hermite normal form is a built-in function in computer algebra systems. F or instance, in Maple the command is ihermite . U sing the in vertible matrix V , we ma y replace A with H , so tha t R S b ecomes R k and Z S is the image o ve r Z of the upp er left k × k -submatrix of H . W e seek the index of that lattice in the p ossibly larg er lattice Z A ∩ Z k . T o this end w e compute the column Hermite normal form H ′ = H V ′ . Here V ′ ∈ S L n ( Z ) and H ′ satisfies H ′ ij = 0 if i > j or j > d and 0 ≤ H ij < H ii for i < j. The lattice Z A ∩ Z k is spanned b y the first k columns of H ′ , and this implies index( S ) = H 11 H 22 · · · H k k H ′ 11 H ′ 22 · · · H ′ k k . 4 Algorith ms In this section we discuss algorithms for computing the integral (17) exactly , and w e discuss their a dv an tages and limitations. In particular, w e examine four main tec hniques whic h represen t the form ulas (20), (21), (16) and (2 2) resp ectiv ely . The practical p erfo rmance o f the v arious algorithms is compared b y computing the in tegral in Example 2.5. A Maple library whic h implemen ts our algo rithms is made a v ailable at http://math .berkeley.edu/ ~ shaowei/int egrals.html . The input for our Maple code consists of para meter v ectors s = ( s 1 , . . . , s k ) and t = ( t 1 , . . . , t k ) as we ll as a data v ector U ∈ N n . This input uniquely sp ecifies the d × n -matrix A . Here d and n are as in (5). The output features the matrices A and ˜ A , the marginal like liho o d in tegrals for M a nd M (2) , as w ell as the b ounds in (24). W e tacitly assume tha t A has b een replaced with the reduc ed matrix ˜ A . Th us from no w on we assume that A has no rep eated columns. This requires some care concerning the normalizing constan ts. All columns of the matrix A ha v e the same co ordinate sum a , a nd the con ve x hu ll of the columns is 14 the p olytop e P = ∆ t 1 × ∆ t 2 × · · · × ∆ t k . Our domain of integration is the follo wing p olytop e o f dimension 2 d − 2 k + 1: Θ = ∆ 1 × P × P. W e seek to compute the rational num b er Z Θ n Y v =1 ( σ 0 θ a v + σ 1 ρ a v ) U v dσ d θ dρ, (25) where in tegratio n is with resp ect to Leb esgue pro babilit y measure. Our Maple co de o utputs this integral m ultiplied with the statistically correct normalizing constan t. That constan t will b e ignored in what follows. In our complexit y a nalysis, w e fix A while allowin g the data U to v ary . T he complexities will b e given in terms of the sample size N = U 1 + · · · + U n . 4.1 Ignorance is Costly Giv en a n integration problem suc h as (25), a first a t t empt is to use the sym- b olic in tegratio n capabilit ies of a computer algebra pac k age suc h as Maple . W e will refer to this metho d as ignor ant inte gr ation : U := [51, 18, 73, 25, 75]: f := (s*t^4 +(1-s)*p^4 )^U[1] * (s*t^3*(1-t ) +( 1-s)*p^3*(1-p) )^U[2] * (s*t^2*(1-t )^2+(1-s)*p^2*(1-p)^2)^U[3] * (s*t *(1-t)^3+(1- s)*p *(1-p)^3)^U [4] * (s *(1-t)^4+(1-s ) *(1-p)^4)^U[5 ]: II := int(int(i nt(f,p=0.. 1),t=0..1),s=0..1); In the case of mixture mo dels, recognizing the inte gral as the sum of in tegrals of monomials o v er a p olytop e allows us to av oid the exp ensiv e in- tegration step a b ov e by using (20). T o demonstrate the p ow er of using (20), w e implemen ted a simple algorithm that computes eac h φ A ( b, U ) using the naiv e expansion in (19). W e computed the in tegral in Example 2.5 with a small data v ector U = (2 , 2 , 2 , 2 , 2), whic h is the rational n umber 66364720 654753 59057383 98721701 5339940 0 00 , and summarize the run-times and memory usages o f the tw o algo r it hms in the table b elow. All exp erimen ts rep orted in this section are done in Maple . 15 Time(seconds ) Memory(b ytes) Ignoran t In tegration 16.331 155,947,12 0 Naiv e Ex pansion 0.007 458,668 F or the remaining comparisons in this section, we no long er consider the ignoran t in tegration algorithm b ecause it is computationally to o exp ensiv e. 4.2 Sym b olic Expansion of the In tegrand While ignorant use of a computer alg ebra system is unsuitable fo r computing our in tegrals, we can still exploit its p ow erful p olynomial expansion capa bil- ities to find the co efficien ts of (2 1). A ma jor adv an tage is that it is very easy to write co de f o r this metho d. W e compare the p erformance of this sym b o lic expansion a lg orithm against that of the naive expansion algorithm. The ta- ble b elo w concerns computing the co efficien ts φ A ( b, U ) for the original data U = (51 , 18 , 73 , 25 , 7 5). The column “Extract” refers to the time tak en t o extract the co efficien ts φ A ( b, U ) from the expansion of the p olynomial, while the column “Sum” sho ws the time taken to ev aluate (20) af t er all the needed v alues of φ A ( b, U ) had b een computed and extracted. Time(seconds ) Memory φ A ( b, U ) Extract Sum T o tal (b ytes) Naiv e Expansion 2764.35 - 31.19 2795.54 10,287,268 Sym b olic Expansion 28 .73 962.86 2 9.44 1021.03 66,965,528 4.3 Storage and Ev aluation of φ A ( b, U ) Sym b olic expansion is fast for computing φ A ( b, U ), but it has t wo dra wbac ks: high memory consumption and the lo ng time it tak es to extract the v alues of φ A ( b, U ). One solution is to create sp ecialized data structures and algorithms for expanding (21), rather using than t hose offered b y Mapl e . First, w e tackle the problem o f storing t he co efficien ts φ A ( b, U ) fo r b ∈ Z L A ( U ) ⊂ R d as they are b eing computed. One naiv e metho d is to use a d -dimensional arr a y φ [ · ]. How ev er, noting tha t A is not ro w rank f ull, w e can use a d 0 -dimensional array to store φ A ( b, U ), where d 0 = rank( A ) = d − k + 1. F urthermore, b y Prop o sition 3.3(2), the expanded integrand is a symmetric p olynomial, so only half the co efficien ts need to b e stored. W e will lea v e out the implemen tation details so as not to complicate o ur discussions. In o ur 16 algorithms, w e will assume that the coefficien ts are stored in a d 0 -dimensional arra y φ [ · ], and t he en try that represen ts φ A ( b, U ) will be referred to as φ [ b ]. Next, w e discuss how φ A ( b, U ) can b e computed. One could use the naiv e expansion (19), but t his in volv es ev aluating ma ny binomials co efficien ts and pro ducts, so the algorithm is inefficien t for data v ectors with large co ordi- nates. A m uc h more efficien t solution use s the recurrence form ula (22): Algorithm 4.1 (RECURRENCE( A , U )) . Input: The matrix A a nd the vector U . Output: The coefficien ts φ A ( b, U ). Step 1 : Create a d 0 -dimensional arr ay φ of zeros. Step 2 : F or eac h x ∈ { 0 , 1 , . . . , U 1 } set φ [ xa 1 ] := U 1 x . Step 3 : Create a new d 0 -dimensional arra y φ ′ . Step 4 : F or eac h 2 ≤ j ≤ n do 1. Set all the entries of φ ′ to 0. 2. F or eac h x ∈ { 0 , 1 , . . . , U j } do F or each non-zero en try φ [ b ] in φ do Incremen t φ ′ [ b + xa j ] b y U j x φ [ b ] . 3. Replace φ with φ ′ . Step 5 : Output the array φ . The space complexit y o f this algorithm is O ( N d 0 ) and its time complex- it y is O ( N d 0 +1 ). By comparison, the naive expansion algorithm has space complexit y O ( N d ) and time complexit y O ( N n +1 ). W e no w turn our atten tio n to computing the in tegral (25). One ma jor issue is the lac k of memory to store all the terms o f the expansion of t he in tegrand. W e ov ercome this problem b y writing the integrand as a pro duct of smaller factors whic h can b e expanded separately . In particular, we partition the columns of A into submatrices A [1] , . . . , A [ m ] and let U [1] , . . . , U [ m ] b e the corresp onding partition of U . Th us the in tegr a nd b ecomes m Y j =1 Y v ( σ 0 θ a [ j ] v + σ 1 ρ a [ j ] v ) U [ j ] v , where a [ j ] v is the v t h column in the matrix A [ j ] . The resulting a lgorithm for ev aluating the in tegral is as follow s: 17 Algorithm 4.2 (F ast Integral) . Input: The matrices A [1] , . . . , A [ m ] , v ectors U [1] , . . . , U [ m ] and the v ector t . Output: The v alue of the in tegral (2 5) in exact rational a rithmetic. Step 1 : F or 1 ≤ j ≤ m , compute φ [ j ] := RECURRENCE( A [ j ] , U [ j ] ). Step 2 : Set I := 0. Step 3 : F or eac h non-zero en try φ [1] [ b [1] ] in φ [1] do . . . F or each non-zero en try φ [ m ] [ b [ m ] ] in φ [ m ] do Set b := b [1] + · · · + b [ m ] , c := AU − b , φ := Q m j =1 φ [ j ] [ b [ j ] ]. Incremen t I b y φ · ( | b | /a )!( | c | /a )! ( | U | +1)! · Q k i =1 t i ! b ( i ) 0 ! ··· b ( i ) t i ! ( | b ( i ) | + t i )! t i ! c ( i ) 0 ! ··· c ( i ) t i ! ( | c ( i ) | + t i )! . Step 4 : Output the sum I . The algorithm can b e sp ed up by precomputing the factorials used in the pro duct in Step 3. The space and time complex it y of this algo rithm is O ( N S ) and O ( N T ) resp ectiv ely , where S = max i rank A [ i ] and T = P i rank A [ i ] . F rom this, we see tha t the splitting of the in tegra nd should b e chos en wis ely to achie ve a go o d pay-off b etw een t he t w o complexities. In the table b elow, w e compare the naiv e expansion algorithm and the fast in tegral algorithm fo r the data U = (51 , 1 8 , 73 , 25 , 75). W e also compare the effect o f splitting the integrand in t o tw o factors, as denoted by m = 1 and m = 2. F or m = 1 , the fast in tegral algorithm tak es significan tly less time tha n naive expansion, and requires only ab out 1.5 times more memory . Time(min utes) Memory(b ytes) Naiv e Ex pansion 43.67 9,173,360 F ast Integral (m=1) 1.76 13,497,944 F ast Integral (m=2) 139.47 6,355,828 4.4 Limitations and App lications While our algorit hms are optimized for exact ev aluation of in tegrals for mix- tures o f indep endence mo dels, they may not b e practical for applicatio ns in v o lving large sample sizes. T o demonstrate their limitations, w e v ary the sample sizes in Example 2.5 and compare the computation times. The data v ectors U are generated by scaling U = (51 , 18 , 73 , 25 , 75 ) according to the sample size N and rounding off the en tries. Here, N is v aried fr om 1 10 to 300 18 Figure 1 : Comparison of computation time against sample size. b y incremen ts of 10. Figure 1 shows a logarithmic plot of the results. The times tak en for N = 110 a nd N = 300 a r e 3 . 3 and 98 . 2 seconds resp ectiv ely . Computation times for larger samples may b e extrap olated from the graph. Indeed, a sample size of 5000 could tak e more than 13 da ys. F or other mo dels, suc h as the 1 0 0 Swiss F r ancs example in Section 1 and that of the schiz o phrenic patients in Example 5.5, the limitations ar e ev en more a pparen t. In the table b elo w, for eac h example we list the sample size, computation time, rank of the corresp onding A -matrix and the num b er of terms in the expansion of the in tegrand. Despite ha ving smaller sample sizes, the computations for the latter tw o examples tak e a lo t more time. This ma y b e attributed to the higher ranks of the A -matrices and the la r g er num b er of terms that need to b e summed up in o ur a lgorithm. Size Time Rank #T erms Coin T oss 242 45 sec 2 48,646 100 Swiss F r a ncs 40 15 hrs 7 3,892,097 Sc hizophrenic P atien ts 132 1 6 day s 5 34,177,836 Despite their high complex it ies, w e b eliev e our algorit hms are imp ortant b ecause t hey pro vide a go ld standard with whic h appro ximatio n metho ds suc h as those studied in [1] can b e compared. Belo w, w e use our exact meth- 19 o ds to ascertain the accuracy of asymptotic form ula derive d b y W a tanab e et al. using des ingularization metho ds fro m alg ebraic geometry [14, 15, 16]. Example 4.3. Consider the mo del from Example 2.5. Cho ose data ve cto r s U = ( U 0 , U 1 , U 2 , U 3 , U 4 ) with U i = N q i where N is a m ultiple of 16 and q i = 1 16 4 i , i = 0 , 1 , . . . , 4 . Let I N ( U ) b e the in tegral (25). D efine F N ( U ) = N 4 X i =0 q i log q i − lo g I N ( U ) . According to [16], for large N w e ha v e the asy mptotics E U [ F N ( U )] = 3 4 log N + O (1) (26) where the exp ectation E U is tak en o v er all U with sample size N under the distribution defined b y q = ( q 0 , q 1 , q 2 , q 3 , q 4 ). Thus , w e should exp ect F 16+ N − F N ≈ 3 4 log(16 + N ) − 3 4 log N =: g ( N ) . W e compute F 16+ N − F N using our exact metho ds and list the results b elo w. N F 16+ N − F N g ( N ) 16 0 .2 1027043 0.2257724 97 32 0 .1 2553837 0.1320684 44 48 0 .0 8977938 0.0937040 53 64 0 .0 6993586 0.0726825 10 80 0 .0 5729553 0.0593859 34 96 0 .0 4853292 0.0502100 92 112 0.0 4209916 0.0434939 60 Clearly , the ta ble suppo r ts our conclusion. The co efficien t 3 / 4 of log N in the formula (26) is know n as the r e al lo g-c anonic al thr eshold o f the statistical mo del. The example suggests tha t our metho d could b e dev elop ed in to a n umerical tec hnique for computing the real lo g -canonical threshold. 20 5 Bac k t o Ba y es ian statis tics In this section w e discuss ho w the exact integration appro ac h presen ted here in terfaces with issues in Bay esian statistics. The first concerns the rat her restrictiv e assumption that our marginal like liho o d in tegral b e ev aluated with resp ect t o the uniform distribution (Lesb egue measure) on t he para meter space Θ. It is standard practice t o compute suc h integrals with resp ect to Dirichlet priors , and w e shall no w explain ho w our alg orithms can b e extended to Dirich let priors. That extension is also a v ailable as a feature in our Maple impleme n tation. Recall that the Dirichlet distribution Dir( α ) is a con tin uous probabilit y distribution whic h is parametrized b y a vec t o r α = ( α 0 , α 1 , . . . , α m ) of p os- itiv e reals. It is the m ultiv ariate generalization of t he beta distribution and is conjugate prior (in the Bay esian sense) to the m ultinomial distribution. This means that the probability distribution function of D ir( α ) sp ecifies the b elief that the probabilit y of t he i th among m + 1 ev en ts equals θ i giv en tha t it has b een observ ed α i − 1 times. More precisely , the probabilit y densit y function f ( θ ; α ) of Dir( α ) is suppor ted on the m -dimensional simplex ∆ m = ( θ 0 , . . . , θ m ) ∈ R m ≥ 0 : θ 0 + · · · + θ m = 1 , and it equals f ( θ 0 , . . . , θ m ; α 0 , . . . , α m ) = 1 B ( α ) · θ α 0 − 1 0 θ α 1 − 1 1 · · · θ α m − 1 m =: θ α − 1 B ( α ) . Here the normalizing constan t is the m ultinomial b eta function B ( α ) = m !Γ( α 0 )Γ( α 1 ) · · · Γ( α m ) Γ( α 0 + α 1 + · · · + α m ) . Note that, if the α i are a ll in tegers, then this is the ratio na l n umber B ( α ) = m !( α 0 − 1)!( α 1 − 1)! · · · ( α m − 1)! ( α 0 + · · · + α m − 1)! . Th us the iden tity (12) is the sp ecial case of the iden tity R ∆ m f ( θ ; α ) dθ = 1 for the densit y of the Diric hlet distribution when a ll α i = b i + 1 a re integers . W e no w return t o the marginal lik eliho o d for mixtures of indep endence mo dels. T o compute t his quan tity with resp ect to Diric hlet priors means 21 the follo wing. W e fix p ositive real num b ers α 0 , α 1 , and β ( i ) j and γ ( i ) j for i = 1 , . . . , k and j = 0 , . . . , t i . Thes e sp ecify Diric hlet distributions on ∆ 1 , P and P . Namely , the D ir ic hlet distribution on P giv en b y the β ( i ) j is the pro duct probabilit y measure giv en b y taking the Diric hlet distribution with parameters ( β ( i ) 0 , β ( i ) 1 , . . . , β ( i ) t i ) on the i -th factor ∆ t i in the pro duct (7) and similarly for the γ ( i ) j . The resulting pro duct probability distribution on Θ = ∆ 1 × P × P is called the Dirichlet distribution with parameters ( α, β , γ ). Its probability densit y function is the pro duct of the respectiv e densities: f ( σ, θ , ρ ; α, β , γ ) = σ α − 1 B ( α ) · k Y i =1 ( θ ( i ) ) β ( i ) − 1 B ( β ( i ) ) · k Y i =1 ( ρ ( i ) ) γ ( i ) − 1 B ( γ ( i ) ) . (27) By the marginal lik eliho o d with Dirichle t priors we mean the in tegral Z Θ L U ( σ , θ , ρ ) f ( σ , θ , ρ ; α , β , γ ) dσ d θ dρ. (28) This is a mo dification of (15) and it dep ends not just on the data U and the mo del M (2) but a lso on the ch oice of D ir ichlet parameters ( α, β , γ ). When the co ordinates of these parameters are arbitrar y p ositiv e reals but not in- tegers, t hen t he v alue of the integral (28) is no longer a rational n umber. Nonetheless, it can b e computed exactly a s f ollo ws. W e abbreviate the pro d- uct of gamma functions in the denominator of the densit y (2 7) as follo ws: B ( α, β , γ ) := B ( α ) · k Y i =1 B ( β ( i ) ) · k Y i =1 B ( γ ( i ) ) . Instead of the in tegrand ( 1 8) w e now need to in tegrate X b ∈ Z L A ( U ) c = AU − b φ A ( b, U ) B ( α, β , γ ) · σ | b | /a + α 0 − 1 0 · σ | c | /a + α 1 − 1 1 · θ b + β − 1 · ρ c + γ − 1 with resp ect to Leb esgue proba bilit y measure on Θ. Doing this term by term, as b efore, w e obtain the follo wing modification of Theorem 3.2. Corollary 5.1. The mar ginal likeliho o d of the data U in the mixtur e mo del M (2) with r esp e ct to Dirichle t priors with p ar ameters ( α, β , γ ) e q uals N ! U 1 ! ··· U n ! · B ( α,β ,γ ) · P b ∈ Z L A ( U ) c = AU − b φ A ( b, U ) Γ( | b | /a + α 0 )Γ( | c | /a + α 1 ) Γ( | U | + | α | ) · Q k i =1 t i !Γ( b ( i ) 0 + β ( i ) 0 ) ··· Γ( b ( i ) t i + β ( i ) t i ) Γ( | b ( i ) | + | β ( i ) | ) t i !Γ( c ( i ) 0 + γ ( i ) 0 ) ··· Γ( c ( i ) t i + γ ( i ) t i ) Γ( | c ( i ) | + | γ ( i ) | ) . 22 A w ell-known exp erimen tal study b y Chic k ering and Hec ke rma n [1] com- pares differen t metho ds for computing numerical appro ximations of marginal lik eliho o d in tegra ls. The mo del considered in [1 ] is the naive-B a yes mo del , whic h, in t he languag e of alg ebraic geometry , corresp onds to ar bitrary se- can t v arieties of Segre v arieties. In this pap er we considered the first secan t v ariet y of a r bit r a ry Segre-V eronese v a r ieties. In what follo ws we restrict our discussion to the in tersection of b o t h classes of mo dels, namely , to the first secan t v ariet y of Segre v arieties. F or the remainder of this section w e fix s 1 = s 2 = · · · = s k = 1 but w e allow t 1 , t 2 , . . . , t k to b e arbitrary p ositive integers. Th us in the mo del of [1, Eq ua tion (1)], w e fix r C = 2, and the n there corresp onds to our k . T o k eep things as simple as p ossible, w e shall fix the uniform distribution as in Sections 1–4 ab ov e. T hus, in t he notation of [1, § 2], all D iric hlet hy- p erparameters α ij k are set to 1 . This implies tha t , for an y data U ∈ N n and an y of our mo dels, the pro blem of finding the maximum a p o steriori (MAP) configuration is equiv alen t to finding the maxim um likelihoo d ( ML) configu- ration. T o b e precise, the MAP c onfigur ation is the p oin t ( ˆ σ , ˆ θ, ˆ ρ ) in Θ whic h maximizes the like liho o d f unction L U ( σ , θ , ρ ) in (14). This maxim um may not b e unique, and there will t ypically b e man y lo cal maxima. Chic k ering and Hec ke r ma n [1, § 3.2] use the exp ectation maximization (EM) alg o rithm [12, § 1.3] to compute a n umerical appro ximation of the MAP configuration. The Laplace appro ximation and the BIC score [1, § 3.1] are predicated on the idea that the MAP configura t ion can b e found with high a ccuracy and that the data U w ere actually drawn from t he correspo nding distribu- tion p ( ˆ σ , ˆ θ , ˆ ρ ). Let H ( σ, θ , ρ ) denote the Hessian matrix of t he log-lik eliho o d function log L ( σ, θ , ρ ). Then the Laplace approxim a tion [1, equation (15)] states that the logarithm of the marginal likelih o o d can b e approx imated b y log L ( ˆ σ , ˆ θ , ˆ ρ ) − 1 2 log | det H ( ˆ σ , ˆ θ , ˆ ρ ) | + 2 d − 2 k + 1 2 log(2 π ) . (29) The Ba ye sian informatio n criterion (BIC) suggests the coarser appro ximatio n log L ( ˆ σ , ˆ θ , ˆ ρ ) − 2 d − 2 k + 1 2 log( N ) , (30) where N = U 1 + · · · + U n is the sample size. In algebraic statistics, we do not conten t ourselv es with the output of the EM algorithm but, to the exten t p ossible, w e seek to actually solve the 23 lik eliho o d equations [11] and compute all lo cal maxima o f the lik eliho o d function. W e conside r it a difficult pro blem to reliably find ( ˆ σ , ˆ θ , ˆ ρ ), and w e are concerned ab out the accuracy of an y approximation lik e (29) o r (30). Example 5.2. Consider the 100 Swiss F r ancs table (2) discussed in the In tro duction. Here k = 2, s 1 = s 2 = 1, t 1 = t 2 = 3, the matrix A is unimo dular, and (9) is the Segre em b edding P 3 × P 3 ֒ → P 15 . The parameter space Θ is 13-dimensional, but the mo del M (2) is 11-dimensional, so the giv en parametrization is not iden tifiable [6 ]. This means that the Hessian matrix H is singular, and henc e the Laplace appro ximation (29) is not defined. Example 5.3. W e compute (29) and (30) for the mo del and dat a in Example 2.5. According to [11, Example 9], the lik eliho o d function p 51 0 p 18 1 p 73 2 p 25 3 p 75 4 has three lo cal maxima ( ˆ p 0 , ˆ p 1 , ˆ p 2 , ˆ p 3 , ˆ p 4 ) in the mo del M (2) , and these translate in to six lo cal maxima ( ˆ σ , ˆ θ , ˆ ρ ) in the parameter space Θ , whic h is the 3-cub e. The tw o g lo bal maxima ( ˆ σ 0 , ˆ θ 0 , ˆ ρ 0 ) in Θ are (0 . 336769 1 969 , 0 . 0287 713237 , 0 . 6 536073424) , (0 . 663230 8 031 , 0 . 6536 073424 , 0 . 0 287713237) . Both of thes e p oints in Θ giv e the same point in the mo del: ( ˆ p 0 , ˆ p 1 , ˆ p 2 , ˆ p 3 , ˆ p 4 ) = (0 . 121 04 , 0 . 25662 , 0 . 20556 , 0 . 10 7 58 , 0 . 30920) . The lik eliho o d function ev aluates to 0 . 1 3954711 0 1 × 10 − 18 at this p oint. The follo wing ta ble compares the v arious appro ximations. Here, “Actual” refers to the base-10 logarithm of the marg ina l lik eliho o d in Example 2.5. BIC -22.43100220 Laplace -22.396662 81 Actual -22.108534 11 The metho d for computing the marginal lik eliho o d whic h w as f ound to b e most accurate in the exp erimen ts of Chic k ering and Hec k erman is the c andidate metho d [1, § 3.4]. This is a Mon te-Carlo metho d whic h in v olves running a G ibbs sampler. The basic idea is that one wishes to compute a large sum, suc h as (20) by sampling among the terms rather than listing all terms. In the candidate metho d one uses not the sum (20) o ver the la ttice p oin ts in the zonotop e but the more naive sum ov er all 2 N hidden data that 24 w ould result in the observ ed data represen ted b y U . The v alue of the sum is the n umber of t erms, 2 N , times the av erage of the summands, eac h of whic h is easy to compute. A comparison of the results of the candidate metho d with our exact computations, as w ell as a more accurate vers io n o f Gibbs sampling whic h is a dapted fo r (20), will b e the sub ject of a future study . One of the applications of marginal lik eliho o d in tegrals lies in mo del se- lection. An imp ortan t concept in that field is that o f Bayes factors . Giv en data and tw o comp eting mo dels, the Bay es factor is the rat io of the marginal lik eliho o d in tegral of the first mo del o v er the margina l lik eliho o d in t egral of the second mo del. In our con text it mak es sense to form that ratio for the independence mo del M and its mixture M (2) . T o b e precise, giv en any indep endence mo del, sp ecified by p ositiv e in tegers s 1 , . . . , s k , t 1 , . . . , t k and a corresp onding data v ector U ∈ N n , the Bay es factor is the ra tio of the marginal lik eliho o d in Lemma 2.2 and the marginal lik eliho o d in Theorem 3.2. Both qu an tities are ra t ional num bers and hence so is their ratio. Corollary 5.4. Th e Bayes fa ctor which discriminates b etwe en the indep en- denc e m o del M and the mixtur e m o del M (2) is a r ational n umb er. It c an b e c ompute d exa ctly using A lg o rithm 4.2 (and our Maple -implem entation). Example 5.5. W e conclude b y applying our metho d to a data set tak en from the Ba yes ia n statistics literature. Ev ans, Gilula and G ut t ma n [5, § 3] analyzed t he asso ciation betw een length of hospital stay (in y ears Y ) of 132 sc hizophrenic pa t ients and the frequency with whic h they are visited b y their relativ es. Their data set is the follo wing con tingency table of format 3 × 3: U = 2 ≤ Y < 10 10 ≤ Y < 20 20 ≤ Y T otals Visited regularly 43 16 3 62 Visited rarely 6 11 10 27 Visited neve r 9 18 16 43 T otals 58 45 29 132 They presen t estimated p osterior means and v ariances for these data, where “e ach estimate r e quir es a 9 -dimen s ional inte gr ation ” [5, p. 561]. Computing their integrals is essen tially equiv alen t t o our s, for k = 2 , s 1 = s 2 = 1 , t 1 = t 2 = 2 and N = 132. The autho rs emphasize t hat “the d i m ensionality of the inte gr al do es pr esent a pr oblem” [5, p. 5 62], and they p oin t out that “al l p osterior moments c an b e c alculate d in cl o se d form .... how ever, even fo r mo dest N these exp r ession s ar e far to c omplic ate d to b e useful” [5, p. 559]. 25 W e differ on that conclusion. In our view, the closed form expressions in Section 3 are quite useful for mo dest sample size N . Us ing Algorithm 4 .2, w e compute d the in tegral ( 25). It is the r a tional num b er with n umerator 27801948 85310633 8912064 3 60032498932910 3876 1408 0 5 28524283 95820925 6935726 5 88667532284587 4097 5280 3 3 99493069 71310363 3199906 9 39405711180837 5688 5373 7 and denominator 12288402 87359193 5400678 0 94796599848745 4428 3 3177572204 50448819 97928645 6995185 5 42195946815073 1124 2 9169997801 33503900 16992191 2167352 2 39204153786645 0291 5 3951176422 43298328 04616347 2261962 0 28461650432024 3563 3 9706541132 34375318 47188027 4818667 6 57423749120000 0000 0 0000000 . T o obt a in the ma r g inal lik eliho o d for the data U ab ov e, that ratio nal n um b er (of mo derate size) still nee ds to b e m ultiplied with the normalizing constant 132! 43! · 16! · 3! · 6! · 11! · 10! · 9! · 18! · 16! . Ac knowledgem ents. Shaow ei Lin w as supp orted b y g raduate fellows hip from A*ST AR (Agency for Science, T ec hnolog y and Researc h, Singap ore). Bernd Sturmfels w as supp orted b y an Alexander von Hum b oldt researc h prize and the U.S. National Science F o undation (DMS-04 56960). Zhiqiang Xu is Supp o rted b y the NSF C gran t 108711 96 and a Sofia K o v alevsk a y a prize a warded to Olg a Holtz. References [1] D.M. Chic k ering and D. Hec k erman: Efficien t appro ximations for the marginal lik eliho o d of Bay esian net w orks with hidden v ariables, Machine L e arning 29 (199 7) 181- 212; Microsoft Researc h Rep ort, MSR-TR-96 -08. 26 [2] D. Co x, J. Little and D. O’Shea: Using A lgeb r aic Ge ometry (2nd ed.), Springer-V erlag, 2 0 05. [3] M. Drton: Lik eliho o d ratio tests and singularities, to app ear in A n nals of Statistics , arXiv:math/0703 360 . [4] M. Drton, B. Sturmfels and S. Sulliv an t: L e ctur es on A lgeb r aic Statistics , Ob erw olfa c h Seminars, V ol. 39, Birkh¨ auser, Basel, 2009. [5] M. Ev ans, Z. Gilula and I. Gut t ma n: Laten t class analysis of tw o-w ay con tingency tables b y Bay esian metho ds, Biometrika 76 ( 1989) 557 –563. [6] S. F ein b erg, P . Hersh, A. Rinaldo and Y. Zhou: Maxim um lik eli- ho o d estimation in laten t class mo dels for con tingency ta ble data, arXiv:0709. 3535 . [7] W. F ulton: Intr o duction to T ori c V arieties , Princeton Univ. Press, 1 993. [8] S. Ga o, G. Jiang and M. Zh u: Solving the 100 Swiss F rancs Problem, arXiv:0809. 4627 . [9] D. G eiger a nd D. R usak o v: Asymptotic model se lection for naiv e Ba ye sian net works , Journal of Machine L e arning R ese ar ch 6 (20 05) 1–35. [10] R. Stanley: A zonotop e asso ciated with graphical degree sequences, in Applie d Ge ometry and Discr ete Mathematics: The Victor Kle e F e stschrift (eds. P . Gritzmann and B. Sturmfels), Amer. Math. So c., DIMA CS Series in Discrete Mathematics 4 (1991) 555–570. [11] S. Ho ¸ sten, A. Khetan and B. Sturmfels: Solving the lik eliho o d equations, F ounda tions of Com p utational Mathematics 5 (2 005) 3 8 9–407. [12] L. P ach ter and B. Sturmfels: Algebr a i c Statistics for Computational Biolo gy , Cam bridge Univ ersit y Press, 2005. [13] B. Sturmfels: Op en problems in algebraic statistics, Em er ging Applic a- tions of Algebr aic Ge ometry (eds. M. Putinar and S. Sulliv an t), I.M.A. V olumes in Mathematics and its Applications 149 (2008) 3 5 1–364. [14] S. W atanab e: Algebraic analysis f or noniden tifiable learning machines , Neur al Computation 13 (2001 ) 899– 9 33. 27 [15] K.Y amazaki and S.W atanab e: Singularities in mixture mo dels and up- p er bo unds of sto chastic complexity , I n ternational Journal of Neur al Net- works 16 (2003) 1 029–103 8 . [16] K. Y ama zaki and S. W a tanab e: Newton dia gram and sto c hastic com- plexit y in mixture of binomial distributions, in A lg orithmic L e arn ing The- or em , Springer Lecture Notes in Computer Science 3244 (200 4) 350–364. [17] G. Ziegler: L e ctur es o n Polytop es , Springer-V erlag, 1995. 28
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment