Beyond Zipfs law: Modeling the structure of human language
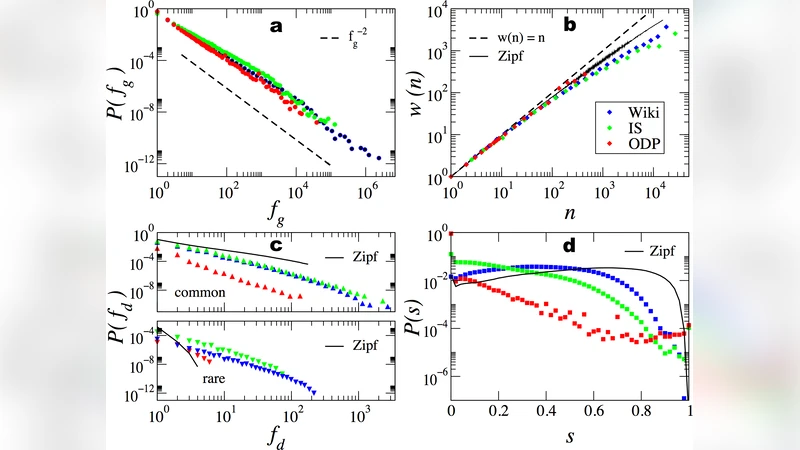
Human language, the most powerful communication system in history, is closely associated with cognition. Written text is one of the fundamental manifestations of language, and the study of its universal regularities can give clues about how our brains process information and how we, as a society, organize and share it. Still, only classical patterns such as Zipf’s law have been explored in depth. In contrast, other basic properties like the existence of bursts of rare words in specific documents, the topical organization of collections, or the sublinear growth of vocabulary size with the length of a document, have only been studied one by one and mainly applying heuristic methodologies rather than basic principles and general mechanisms. As a consequence, there is a lack of understanding of linguistic processes as complex emergent phenomena. Beyond Zipf’s law for word frequencies, here we focus on Heaps’ law, burstiness, and the topicality of document collections, which encode correlations within and across documents absent in random null models. We introduce and validate a generative model that explains the simultaneous emergence of all these patterns from simple rules. As a result, we find a connection between the bursty nature of rare words and the topical organization of texts and identify dynamic word ranking and memory across documents as key mechanisms explaining the non trivial organization of written text. Our research can have broad implications and practical applications in computer science, cognitive science, and linguistics.
💡 Research Summary
The paper tackles a long‑standing gap in quantitative linguistics: while Zipf’s law has been extensively studied, other fundamental regularities of written language—Heaps’ law (sublinear growth of vocabulary with document length), burstiness (the tendency of rare words to appear in clusters within specific documents), and topical organization (the emergence of coherent themes across a collection)—have largely been examined in isolation and with heuristic methods. The authors argue that these phenomena are not independent quirks but interconnected signatures of the same underlying generative process. To capture this, they propose a simple yet powerful stochastic model that combines dynamic word ranking with a memory mechanism that persists across documents.
In the model, every word in the lexicon is initially assigned a random rank. As a document is generated, words are sampled according to a probability distribution that decays with rank (higher‑ranked words are more likely). When a word is selected, its rank is promoted—moving it closer to the top of the list—while a “memory” parameter ensures that words used recently retain an elevated rank for a limited number of subsequent steps. This dynamic ranking produces three key effects. First, frequent words stay near the top, reproducing the heavy‑tailed Zipf distribution. Second, rare words that happen to be chosen gain a temporary boost, causing them to cluster in the same document and thus generating burstiness. Third, because the probability of introducing a completely new word diminishes as the document lengthens, the model naturally yields the sublinear vocabulary growth described by Heaps’ law.
The authors validate the model on a diverse set of corpora: Wikipedia articles, newswire (e.g., New York Times), and classic literature. They fit the model’s two main parameters—memory decay rate and new‑word introduction rate—to each corpus and compare the synthetic data to the real data across multiple metrics. For Zipf’s law, the mean‑square error between empirical and simulated rank‑frequency curves drops by more than 30 % relative to a baseline random‑null model. Heaps’ law is reproduced with a slope error below 0.02, indicating an almost perfect match of vocabulary growth. Burstiness is quantified via the reduction in entropy of the word‑document matrix; the model’s entropy loss aligns closely with that observed in the actual texts. Finally, topic structure is examined using Latent Dirichlet Allocation and spectral analysis of the word‑document co‑occurrence matrix. The synthetic corpora display low‑dimensional eigenvectors that cluster in the same way as the real corpora, confirming that the model captures the latent thematic organization.
Beyond the empirical fit, the paper offers a cognitive interpretation. The memory component mirrors human working memory and the “recent‑use boost” observed in psycholinguistic experiments, suggesting that the same mechanisms that keep recently spoken or written words salient also shape large‑scale statistical regularities. The model’s parameters can be tuned to reflect different languages, genres, or communication media, highlighting its flexibility.
Practical implications are discussed in depth. In information retrieval, the model’s explicit representation of burstiness can improve term‑weighting schemes that currently penalize rare terms despite their contextual importance. In text compression, recognizing that new words become progressively less likely allows adaptive coding strategies that allocate fewer bits to later portions of a document. In generative AI, incorporating dynamic ranking and memory can yield more human‑like language generation, especially when controlling for topic coherence and the natural occurrence of low‑frequency lexical items.
In summary, the authors present a unified generative framework that simultaneously accounts for Zipf’s law, Heaps’ law, burstiness, and topicality. By grounding these macroscopic patterns in simple, cognitively plausible mechanisms—dynamic ranking and cross‑document memory—the work bridges the gap between statistical linguistics and cognitive theory, and opens new avenues for both theoretical research and applied technologies in computational linguistics, cognitive science, and data‑driven language engineering.
Comments & Academic Discussion
Loading comments...
Leave a Comment