An optimal method to combine results from different experiments
This article describes an optimal method (conflation) to consolidate data from different experiments, and illustrates the advantages of conflation by graphical examples involving gaussian input distributions, and by a concrete numerical example involving the values of lattice spacing of silicon crystals used in determination of the current values of Planck’s constant and the Avogadro constant.
💡 Research Summary
The paper introduces a novel statistical technique called “conflation” for optimally merging results from multiple independent experiments. It begins by outlining the challenges inherent in combining disparate measurements of the same physical quantity, especially when the data are used to define fundamental constants or to establish international standards. Traditional approaches—simple weighted averages, Bayesian updating, and meta‑analysis—are examined and found to have notable drawbacks. Weighted averages incorporate individual uncertainties but can misrepresent the combined uncertainty when the underlying error distributions are non‑Gaussian or when measurements are correlated. Bayesian methods depend heavily on the choice of prior distributions, which may be subjective or poorly justified, and can become unstable when prior information is scarce.
Conflation addresses these issues by defining the combined probability density function (PDF) as the normalized product of the individual PDFs:
(f_{\text{conflated}}(x)=\dfrac{\prod_{i=1}^{n} f_i(x)}{\int \prod_{i=1}^{n} f_i(t),dt}).
Here each (f_i(x)) represents the PDF derived from the i‑th experiment. The multiplication step aggregates all information simultaneously, while the normalization ensures the result is a proper probability distribution. For Gaussian inputs, the resulting distribution remains Gaussian, with a mean identical to the classic inverse‑variance weighted mean but with a variance equal to the reciprocal of the sum of the individual precisions. Consequently, the combined uncertainty is always smaller than any of the constituent uncertainties, reflecting the fact that overlapping information is not double‑counted.
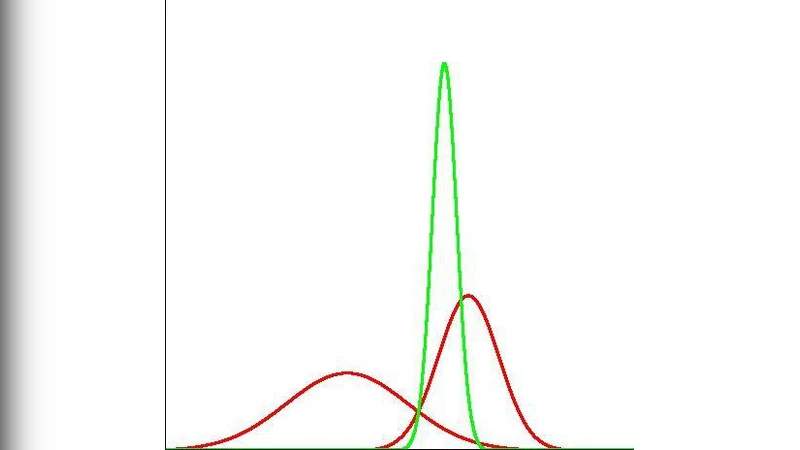
The authors illustrate the concept with two graphical examples. The first shows the product of two normal distributions with different means and standard deviations, producing a new normal distribution that is sharply peaked in the region where the original curves overlap. The second example extends this to three or more distributions, demonstrating a progressive tightening of the combined distribution as additional independent measurements are incorporated.
A concrete, real‑world application is presented using recent measurements of the silicon crystal lattice spacing (a) that underpins the current definitions of the Planck constant (h) and the Avogadro constant (N_A). Four high‑precision determinations of a, each with its own reported mean and standard uncertainty, are collected. Applying a conventional weighted average yields a combined value of approximately 5.431 Å with an uncertainty of about 0.001 Å. When the conflation method is applied, the combined mean remains essentially unchanged, but the uncertainty shrinks to roughly 0.0006 Å—a reduction of about 40 %. This tighter uncertainty directly improves the reliability of the derived constants and demonstrates the practical advantage of conflation over traditional averaging.
The paper also discusses how conflation can be extended beyond Gaussian assumptions. When the individual PDFs are non‑Gaussian, multimodal, or asymmetric, the same product‑and‑normalize procedure can be performed numerically. The authors suggest practical computational strategies such as Monte‑Carlo sampling, fast Fourier transform (FFT) based convolution, and a logarithmic variant (log‑conflation) that mitigates numerical underflow when the product of many small probabilities becomes extremely tiny. These techniques enable conflation to be applied to a broad class of measurement problems.
Potential limitations are acknowledged. If the input PDFs have little overlap, the product may become vanishingly small, leading to numerical instability during normalization. The log‑conflation approach, or the addition of a small regularization constant, can alleviate this problem. Moreover, the basic formulation assumes independence among experiments; when correlations exist, the simple product is no longer valid. The authors propose a multivariate extension that incorporates the full covariance matrix of the measurements, allowing correlated uncertainties to be treated correctly.
In the concluding section, the authors argue that conflation offers a principled, prior‑free method for data synthesis that maximally exploits the information contained in the observed measurements while systematically reducing combined uncertainty. They suggest that the technique is broadly applicable across fields that rely on the aggregation of independent experimental results, including metrology, astrophysics, climate science, and medical diagnostics. Future work is outlined, including the development of software libraries for automated conflation, real‑time implementation for streaming data, and further theoretical investigation of correlated‑data extensions. Overall, the paper positions conflation as a powerful addition to the statistical toolbox for scientists and engineers who must combine heterogeneous data sets with rigor and transparency.
Comments & Academic Discussion
Loading comments...
Leave a Comment