Empirical null and false discovery rate inference for exponential families
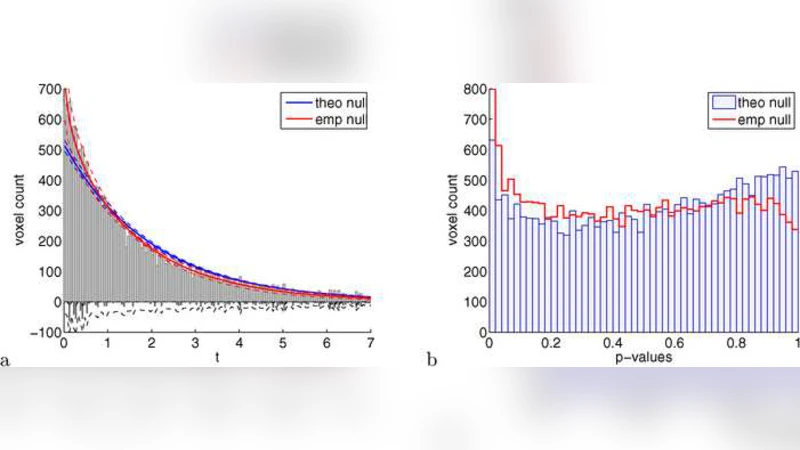
In large scale multiple testing, the use of an empirical null distribution rather than the theoretical null distribution can be critical for correct inference. This paper proposes a mode matching'' method for fitting an empirical null when the theoretical null belongs to any exponential family. Based on the central matching method for $z$-scores, mode matching estimates the null density by fitting an appropriate exponential family to the histogram of the test statistics by Poisson regression in a region surrounding the mode. The empirical null estimate is then used to estimate local and tail false discovery rate (FDR) for inference. Delta-method covariance formulas and approximate asymptotic bias formulas are provided, as well as simulation studies of the effect of the tuning parameters of the procedure on the bias-variance trade-off. The standard FDR estimates are found to be biased down at the far tails. Correlation between test statistics is taken into account in the covariance estimates, providing a generalization of Efron's wing function’’ for exponential families. Applications with $\chi^2$ statistics are shown in a family-based genome-wide association study from the Framingham Heart Study and an anatomical brain imaging study of dyslexia in children.
💡 Research Summary
In large‑scale multiple testing, the conventional practice of assuming a theoretical null distribution (e.g., standard normal, χ²₁) often fails to capture the true behavior of test statistics. Real data are frequently contaminated by hidden batch effects, measurement error, or model misspecification, causing the empirical null to shift away from its theoretical location or to exhibit inflated variance. If this discrepancy is ignored, false discovery rate (FDR) estimates become overly optimistic, leading to an excess of reported discoveries.
The paper introduces a general “mode‑matching” procedure that extends Efron’s central‑matching idea from the normal family to any exponential family. An exponential family has densities of the form
(f(x|\theta)=\exp{\theta^{\top}T(x)-A(\theta)}h(x)),
which includes normal, χ², gamma, Poisson, and many others. The key observation is that, near the mode of the null distribution, the histogram of observed test statistics can be approximated by a Poisson model whose mean is proportional to the null density evaluated at the bin centers.
The algorithm proceeds as follows: (1) construct a histogram of all test statistics with a fixed bin width Δ; (2) select a symmetric window around the theoretical null mode, (
Comments & Academic Discussion
Loading comments...
Leave a Comment