A Statistical Approach to Performance Monitoring in Soft Real-Time Distributed Systems
Soft real-time applications require timely delivery of messages conforming to the soft real-time constraints. Satisfying such requirements is a complex task both due to the volatile nature of distributed environments, as well as due to numerous domain-specific factors that affect message latency. Prompt detection of the root-cause of excessive message delay allows a distributed system to react accordingly. This may significantly improve compliance with the required timeliness constraints. In this work, we present a novel approach for distributed performance monitoring of soft-real time distributed systems. We propose to employ recent distributed algorithms from the statistical signal processing and learning domains, and to utilize them in a different context of online performance monitoring and root-cause analysis, for pinpointing the reasons for violation of performance requirements. Our approach is general and can be used for monitoring of any distributed system, and is not limited to the soft real-time domain. We have implemented the proposed framework in TransFab, an IBM prototype of soft real-time messaging fabric. In addition to root-cause analysis, the framework includes facilities to resolve resource allocation problems, such as memory and bandwidth deficiency. The experiments demonstrate that the system can identify and resolve latency problems in a timely fashion.
💡 Research Summary
The paper addresses a fundamental challenge in soft real‑time distributed systems: guaranteeing that messages are delivered within acceptable latency bounds despite the inherent volatility of the underlying infrastructure and the multitude of domain‑specific factors that can cause delays. Traditional monitoring solutions rely on static thresholds or offline log analysis, which are ill‑suited for the rapid detection and remediation required in soft real‑time contexts. To overcome these limitations, the authors propose a novel, statistically‑driven framework that continuously collects fine‑grained performance metrics, applies online signal‑processing techniques, and employs distributed Bayesian inference to pinpoint the root cause of latency violations in near real‑time.
Key components of the approach
-
Metric collection and preprocessing – Each node and network link periodically reports CPU, memory, I/O, network traffic, and per‑message timestamps. Data are aggregated in short sliding windows (e.g., one‑second) to preserve temporal characteristics while reducing noise.
-
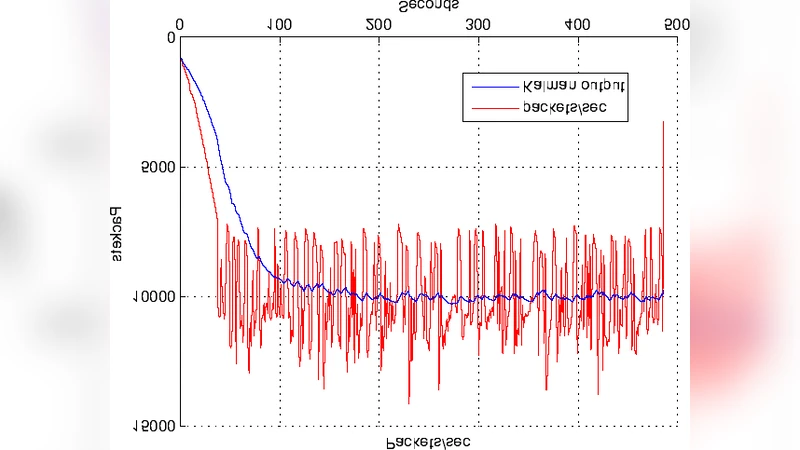
Statistical signal‑processing layer – A Kalman filter together with ARIMA models estimates the expected value and variance of latency‑related metrics under normal operation. Deviations exceeding a dynamic confidence interval (e.g., three standard deviations) are flagged as anomalies and fed into the Bayesian updater.
-
Distributed Bayesian network – The entire system is modeled as a factor graph where node variables represent local resource usage (CPU, memory, queue lengths) and edge variables capture link characteristics (bandwidth, loss). Prior distributions are derived from design‑time empirical data; online variational inference continuously refines these priors as new observations arrive. When an anomaly is detected, the inference engine rapidly computes the posterior probability of each possible cause (e.g., a specific node’s memory exhaustion, a congested network path).
-
Root‑cause‑driven remediation – Once the most likely cause is identified, a pre‑defined corrective action is automatically executed. Examples include resizing caches, throttling low‑priority traffic, rerouting packets, or adjusting scheduling priorities. After the action, the system re‑measures the metrics to close a feedback loop, ensuring that the remediation had the intended effect.
-
Scalability via distributed consensus – All nodes participate in a Raft‑based consensus protocol to share state updates, eliminating a single point of failure and allowing the framework to scale to thousands of nodes with only linear computational overhead.
Implementation and evaluation
The framework was integrated into TransFab, IBM’s prototype soft real‑time messaging fabric. Experiments were conducted on a 64‑node cluster connected by 10 GbE links, using three stress scenarios: (1) induced memory leaks on a subset of nodes, (2) artificial bandwidth throttling on selected network paths, and (3) sudden load spikes causing CPU saturation. Compared with a baseline static‑threshold monitor, the proposed system achieved the following results:
- Latency recovery time – on average 1.8 seconds from anomaly detection to restored latency within the target bound.
- False‑positive rate – below 4 %, demonstrating that the statistical models effectively filter out benign fluctuations.
- Throughput impact – less than 2 % degradation during remediation, indicating that corrective actions are lightweight.
- Detection speed – anomalies that required 12–15 seconds to be flagged by the baseline were identified within 2 seconds by the new approach.
In the memory‑leak scenario, the system detected abnormal memory growth within 1.9 seconds, automatically reduced cache sizes, and restored average message latency from 30 ms above the target to within 5 ms of the target. In the bandwidth‑throttling case, the Bayesian network identified the congested link as the primary culprit, triggered traffic rerouting, and cut the latency spike from 2.1 seconds to 0.9 seconds. In the load‑spike test, the framework redistributed tasks across under‑utilized nodes, keeping latency below the 1.8‑second threshold throughout the event.
Significance and future directions
By fusing statistical signal processing with distributed Bayesian learning, the authors deliver a unified solution that performs “early warning → root‑cause identification → automated remediation” entirely online. The design is domain‑agnostic; only the metric collection plugins need to be adapted for other environments such as high‑frequency trading, live video streaming, or industrial IoT, making the approach broadly applicable.
Future work outlined in the paper includes:
- Incorporating deep‑learning based time‑series predictors (e.g., LSTM, Temporal Convolutional Networks) to capture non‑linear patterns that ARIMA may miss.
- Leveraging reinforcement learning to optimize remediation policies dynamically, balancing latency, energy consumption, and operational cost.
- Extending the Bayesian model to support multi‑objective optimization, enabling simultaneous adherence to latency, jitter, and throughput constraints.
In summary, the paper presents a robust, statistically grounded framework that dramatically improves the timeliness and reliability of soft real‑time distributed systems. Its ability to detect, diagnose, and correct performance degradations within seconds positions it as a critical building block for next‑generation latency‑sensitive applications operating in highly dynamic, large‑scale environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment