Dynamic Network of Concepts from Web-Publications
The network, the nodes of which are concepts (people's names, companies' names, etc.), extracted from web-publications, is considered. A working algorithm of extracting such concepts is presented. Edges of the network under consideration refer to the…
Authors: D. V. L, e, A. A. Snarskii
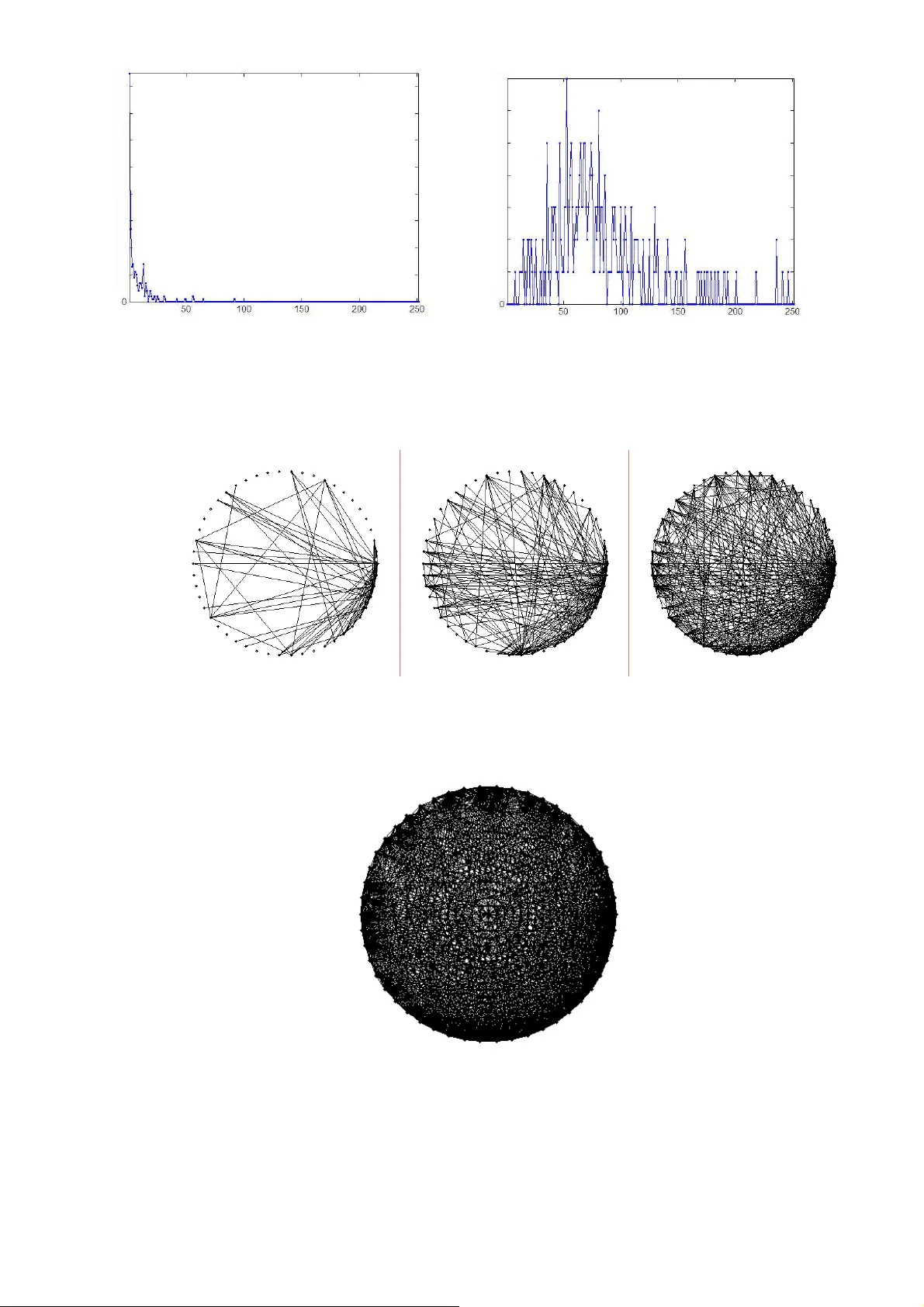
1 DYNAMIC NE TWORK OF CONC EPTS FROM WEB- PUBLICAT IONS Lande D.V. (dwl@visti.net), IC «ELVISTI», NTUU «KPI» Snarskii A.A. (asnarskii@gmail.com), NTUU «KPI» The network, the nodes of which are concepts (people's names, compani es' names, etc.), ex tracted from web-publications, is considered. A workin g algorithm of extracting such concepts is present ed. Edges of the n etwork under consideration refer to the reference frequenc y which depends on the fact how many times the concepts, which correspond to the nodes, are mentioned in the same documents. Web-documents bein g published withi n a period of time together form an inform ation flow, which defines the d yna mics of t he network studied. The p henomenon of its structure st abilit y , when the number of web- publications, constituting its formation bases, increases, is discussed. Key words: complex network, network of concepts, dyna mic networ k, extraction of concepts, internet-content The analysis of complex networks having a social nature is a topi c of pre sent interest in the research. Recently, a se parate branch of di screte mathematics, which is called the theory of complex networks, has been formed; it studies network characteristics taking into account not onl y their topology, but also the distributi on of ref erence frequency of individual nodes [ 1]. Today thi s is a very actual theor y in id entifying and v isualizi ng various communiti es, their i nternal correlations. A fast developm ent of the I nternet content made a great impetus on the development of theoretical and applied issues of the theor y of com plex networks. This research i s devoted to th e analysis of the network relations of the concepts (people's names), extracted from the non- structured texts. Document files, scanned from the Internet using t he InfoStream s ystem of content-monitoring, were used as an example [2]. While developing t he network of concepts, algorithms of automated extraction of concepts from non-structured texts were used. Man y works were devoted to the se technolo gies (see, fo r example [3, 4] ). I t is worth mentioning that the approaches to the extraction of various t ype s of concepts from t he tex ts differ considerably both b y thei r pres entation context and structural features. To identify th e document's belongin g to a themat ic column, requests made in a special wa y and i n information-retrieval languages, including logic and context oper ators, pare ntheses, etc., can be used. To identif y geographical names implies the use of tables, wh ere, except for spelling templates of these n ames, countr y codes, region and town names are used. As an example, we c an give a brie f description of al gorithm identification of company names in document tex ts. A document comes in the system entrance; it is anal yzed in th e pro cess of sequent scannin g. The do cument tex t is compared wit h templates, corresponding names of well-known firms, and in case of their existence, they are plac ed in a sp ecial table "document-firm". I n additi on, the ex traction s ystem of photo graphs envisages the identification of primaril y unknown companies' names b ased on both templates and structural studying of the text. In particular, a table of suffix of the companies' names, containing such elements as "Inc", "Corp.", "Ltd", "Company" and others, is used. Another kind of concepts, such as "persons", is e xtracted from texts based on the rules which consider tables of all owable names and surnames, initial templ ates, possible variants of joint spelling of initials/names and surnames. It is important t o st ate that the above-mentioned InfoStream s ystem contai ns means of concept extraction, and presents them to th e users i n the form of "informa tion portraits", which have such concepts as key words, geographical names, surnames of people, names of the companies etc. The properties of the n etworks, formed with concepts, which are conn ected with eac h other by being mentioned in the same documents, are described in this work. The netwo rk formed wi th people's names, extracted from I nternet-media te xt files according to common political topics during 2 1 (one) month and in 55 thousand documents, was studied more thoroughly. Over 19 thousan d persons were mentioned in the texts. As it has been found out i n the framework of this research, the di stribution of reference frequency of persons in the text file under consid eration corresponds to Tsypfa law [3] (Fig . 1). The network of concepts, whose nodes are persons, and edges connecting the nodes correspond to t he number of references of the persons in the same documents, is researched. The network formed with concepts, extracted from text flows, is not st atic, and it d epends on new documents which appear constantl y, and corresponding conc epts are ex tracted from them. Thus, to understand the structure of such network, it is necessar y to take into account its evolution [6]. Let us look at some imp ortant characteristics from the t heory of complex networks, whi ch are considered in the context of this work. Fig. 1. Plot of distribution of reference frequency of persons in a logarithmic scale The distance b etween no des can b e defined as a quantity of steps t o be ta ken to get from one node to the other. Naturall y, nodes can be conn ected directl y or indirectly. It i s possible to introduce a concept of an average dist ance for the whole s ystem, i.e., the shortest way betw een pairs of nodes . But some networks can be unbou nd ( a n etwork of persons, for example), it means t hat th ere m ight be nodes with an infinite dist ance between them. Correspondingly, an ave rage distance ma y appear to be infinite as well. To keep rec ord of such cases, we introduce a concept of an ave rage inverse distance between nodes, which is calculated as follows: 2 1 , ( 1 ) i j ij il n n d > = − ∑ where ij d − the shortest distance between nodes i and j . The ed ges of the initi al network are given wei ght meanings, equal to the n umber of documents (a document flow from Internet-media is anal y zed), i n which persons of corresponding nodes are mentioned. To prev ent "noise", edges wit h the weight l ess than 2, were ignored. Developing t he network wit h a fix ed number of persons ( e.g., i n Fig. 2 a network wit h 50 persons is conside red), which is realized t hrough the increase of the num ber of documents unde r consideration, an average inverse distance between nodes increases reaching its l ogical saturation. 3 Fig. 2. Dynamics o f changi ng an average invers e dis tance (Y-axis) when the number of documents increases (X-axis ) The coefficient o f clustering [6 ] characte rizes the tendency to t he development of groups of interconnected nodes, so-called cliques. For a separate node of the network, having a degree k , i.e., which k edges come from, connecting it with other k nodes (so-called the nearest neighbors), this parameter is defined as t he ratio between a real quantit y of edges, connecti ng the nearest neighbors among themselves, and a m aximum poss ible one. If to assume that the nearest n eighbors are connected directl y with e ach other, the quanti ty of edges b etween them wo uld be 1 ( 1 ). 2 k k − Hence, clustering coefficient is t he number that corresponds to a m aximum po ssible num ber of ed ges whi ch could connect the nearest neighbors of a chosen n ode. The level of clustering for the whole network is defined as a rated sum (based on the quantit y of nodes) of corresponding coefficients of individual nodes. Naturally, when the network unde r consideration (consistin g of a fix ed quantit y of con cepts) is developed, and the number of anal yzed documents increases, the quantit y of edges increases constantl y and clustering coefficient can reach meanings which are close to o ne (Fig. 3). Fig. 3. Dynamics of changi ng clustering coefficient (Y-axis) when the number of documents i ncreases (X-axis). 4 One of the main characteristi cs of t he network nodes i s betweenness , which is similar to load , a term used in lit erary sources som etimes. This feat ure ex presses the role o f the node in establi shing connections in the network and shows how man y shortest wa ys come th rough it; it i s also traditional for sociolog y whe re persons with a high level of betweenness pla y a leading role in establi shing contacts with other perso ns. Obviousl y, betweenness coefficient ( b ) is complementar y to clustering. One of the results received in the context of this research is the establi shment of the fact that nodes o f the person net work under consid eration with a maxi mum quantity of edges (a d egree) possess the highest level of betweenness in mos t cases ( Fig.4); this is the reason wh y t he y can rather be viewed as the elements which connect separate person groups than as the basis for developi ng clusters under automated grouping. Fig. 4. Coefficients b (Y-axis) for nodes, ranged by a degree An imp ortant ch aracteristic of t he network is the distributi on of node degrees ( ), P k which is defined as probability that the node i has a de gree . i k k = The networks, cha racterized by v arious ( ), P k demonstrate diff erent beh avior. In some cases ( ) P k can be Poiss on distribut ion, ex ponential or degree distributio n. The networks with ex ponential dist ribution o f node d egrees are c alled s cale- free. It is scale- free di stribut ions that are obs erved in re ally existi ng complex netwo rks. Th e existence of nodes wit h a very high degree is p ossible in degree di stribution; in fact they d o not occur in the networks wi th Poiss on or exponenti al distributions. In a dev eloping network under cons ideration wi th a fixed quant ity of nodes correspondi ng to persons and an increasing number of do cuments, at first the distribution appeared to be close to a degree dist ribution and then to a P oisson distrib ution (Fig. 5). This is explained b y the fact that a t first node degrees have a systematic n ature co rresponding t o real connectio ns, and then du e to a large quantity of "occasional contacts" which occur with large number of documents, the network becomes closer to an o ccasional one in whi ch a great num ber o f nodes are connected wit h numerous other ones (Fid. 6, 7). 5 а ) b) Fig. 5. Distri bution of n etwork degrees: а ) Low relation of the scope of t ext files to the number o f persons (1000:250); b) high relation (50000:250) Fig. 6. Dynamics of t he networ k development when th e number of docu ments in a text file increases Fig. 7. Netwo rk, close to a degradat ion condition : 50 persons, 50000 documents As it will be s hown below, when t he network under consideration is analyzed, the distribution of weight meanings of its edges, when various scopes of document flows are considered and whose rank distribution are shown in Fig. 8, is of great im portance. 6 Fig. 8. Distri bution of n etwork edge weight (X-axis) with 50 persons in a l ogarithmic scal e (Y-axis) for web-publicat ion files with 10 00, 10000 and 5 0000 documents To avoid the n etwork degradation, asso ciated with the accumulati on o f "occasional contacts ", let us determine a superimposed network, corresponding t o the desired one, wit h some rough meanings of edge wei ghts, nam ely, with help of the equati on: max max 1 , ' 0 , v v v v v ≥ ε = < ε where ' v - weight of the edge of a sup erimposed network, v - weight o f the edge of th e initial person network, max v - maximu m meaning of the ed ge weight, ε - coefficient of rough estim ate. As the measurement s show, weight me anings of t he network edges are dis tributed exponentiall y on a larger area; it allows assu ming: i a r i v e +λ = , where i v - edge weight of a person network, corr espondi ng to a certain number o f input documents i D , i a - a coefficient, depending on m eaning i D , λ - a co nstant, r - meaning of t he ed ge rank (numbers of decr easing ranking o f weight meanin gs of edges). Let us assume that for so me r r ε = ( 0 1 < ε ≤ ) the followin g is performed: i i a r a i v e e ε +λ = = ε . In this case for some quantit y of input documents k D for the same meaning r r ε = the following will be pe rformed: . k k i i i k i k a r a a a r a a a a k v e e e e e e ε ε + λ − + + λ − = = = ε × × = ε Thus, in accordance with a sug gested model, w here ε expresses a thresh old meaning in the conditions of rough estim ate of a superimposed model, tot al meanings o f all ' v (a quanti t y of edges in a superimposed netwo rk) appear to be a constant quantity. The studying of real da ta showed that the meanings of an avera ge distance and clus tering appeared to be constant as well. The effect proves the stabi lity of a superimp osed network and its relative independen ce from the scopes of in-coming docum ents. I n particul ar, for m eaning ε =0.001, 50 persons and the quantit y of d ocuments ran ging from 1 000 to 50 000, a clustering coefficient was 0.78 ± 0.01, and the avera ge inverse distance - 0.65 ± 0.02. The empiric results rec eived can be useful, fo r example, for t heoretical description and modeling of social and technological processes, identifying and visualizing im plicit connections of separate objects or subje cts in a competit ive survey. 7 The s tabilization phenomenon of a superimposed network m akes it pos sible to practicall y identify stable connectio ns, t o reduce the effect of noise factors through the analysis of relativel y small document files. A longside wi th this, t he issue of the estimation of the correlation of th e received information pe rson connection s calculat ed by countin g document frequenc y, wh ere p ersons are mentioned togeth er and real interconnecti ons, remains open/not studi ed. It is necessar y to s tate that the stabilization of a superimposed network was studied where ε was higher than a threshol d uni t. At the same time, in view of an exponential nature of the distribution of weight meanin gs of the ed ges in th e i nitial network, probably th e p art of conn ections , ignored by us, is as com plicated as th e whole netw ork. In a conclusi on, the authors woul d like to thank the staff m embers of the Information center ElVisti, S. M. Braichevs kiy and A.T. Darmokhv al for their participati on in constructive discuss ions of particular aspects , presented in t his work, and fo r their assistance in maki ng calculations. Reference 1. Newman M .E.J. The s tructure and function of com plex networks. // S IAM Revi ew. - 200 3. - Vol. 45. pp. 167– 256. 2. Br aichevskii, S.M. Lande, D.V. Urgent asp ects of current info rmation flow // Scientific and technical information pro cessing / - Allerton press, inc. – Vo l 32, part 6. -20 05. – P. 18-31. 3. Ralph Grishman. Information ext raction: Techniq ues and chall enges. In Information Extraction ( International Sum mer School SC IE-97). Springer-Verla g, 1997. 4. L ande, D., Darmokhv al A., Moroz ov A. The approach to duplication detection in news information flo ws // In Proc. Of the 8th Russi an Conference on Digital Libraries RCDL’2006, S uzdal, Russia, 2006. – P. 115-119. Available onli ne: http://www.rcdl20 06.uniyar.ac.ru/pape rs/paper_71_v2 .pdf 5. Newman M . E. J. , Barabasi A. L. , W atts D. J. T he Structure and Dynamics of Networks (Princeton Universit y Press, P rinceton, New Jersey, 2006). 6. Watts, D.J. Small W orlds: The Dynamics of Netwo rks between Order and Randomness (Princeton Universit y Press, P rinceton, NJ, 19 99).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment