Constructing Folksonomies from User-specified Relations on Flickr
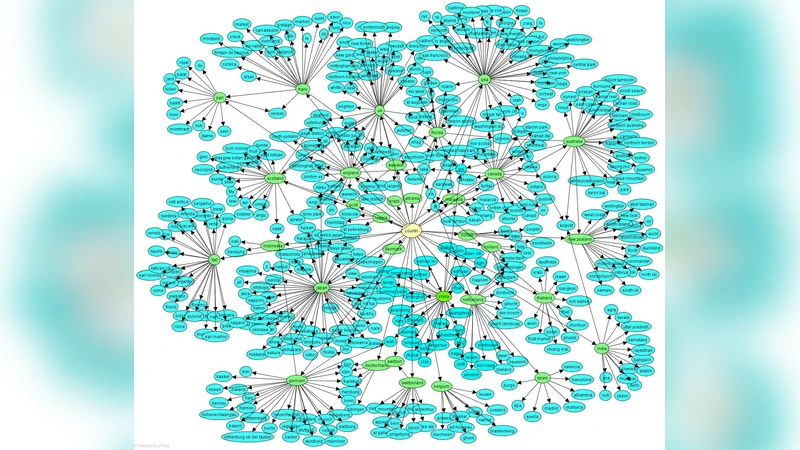
Many social Web sites allow users to publish content and annotate with descriptive metadata. In addition to flat tags, some social Web sites have recently began to allow users to organize their content and metadata hierarchically. The social photosharing site Flickr, for example, allows users to group related photos in sets, and related sets in collections. The social bookmarking site Del.icio.us similarly lets users group related tags into bundles. Although the sites themselves don’t impose any constraints on how these hierarchies are used, individuals generally use them to capture relationships between concepts, most commonly the broader/narrower relations. Collective annotation of content with hierarchical relations may lead to an emergent classification system, called a folksonomy. While some researchers have explored using tags as evidence for learning folksonomies, we believe that hierarchical relations described above offer a high-quality source of evidence for this task. We propose a simple approach to aggregate shallow hierarchies created by many distinct Flickr users into a common folksonomy. Our approach uses statistics to determine if a particular relation should be retained or discarded. The relations are then woven together into larger hierarchies. Although we have not carried out a detailed quantitative evaluation of the approach, it looks very promising since it generates very reasonable, non-trivial hierarchies.
💡 Research Summary
**
The paper investigates how to automatically construct a folksonomy—a user‑generated classification system—by aggregating the shallow hierarchical metadata that Flickr users create through its “collection‑set” feature. While many prior approaches rely solely on flat tags to infer broader‑narrower relations, they suffer from the popularity‑generality problem: frequently used tags are often mistaken for more general concepts. In contrast, Flickr’s collections (super‑albums) and sets (albums) are explicitly named by users, and the naming convention typically reflects a broader‑narrower relationship (the collection name subsumes the set names). The authors therefore treat these user‑specified relations as high‑quality evidence for building a taxonomy.
The proposed framework consists of three main stages:
-
Term Extraction and Normalization – Collection and set titles are tokenized using delimiters such as ‘&’, ‘:’, ‘/’, ‘<’, ‘>’. Non‑alphabetic characters and common stop‑words are removed, and the remaining tokens are stemmed with the Porter algorithm. This step consolidates variant spellings (e.g., “South Africa” vs. “south‑africa”) so that the same concept is consistently identified across users.
-
Relation Conflict Resolution – For each candidate directed edge x → y (meaning x is broader than y), the system counts how many users assert the edge (d₍x→y₎) and how many assert the opposite (d₍y→x₎). Two constraints are defined:
- Hard constraint: d₍x→y₎ > 1 and d₍y→x₎ ≤ 1. Only one dissenting user is tolerated.
- Soft constraint: d₍x→y₎ > 1 and d₍y→x₎ ≤ d₍x→y₎. The majority opinion must favor the edge. These simple voting‑based rules treat contradictory relations as noise and retain only those with clear majority support.
-
Concept Pruning and Linking – After conflict resolution, many nodes remain that are overly generic (e.g., “all set”, “occasion”) and have few or no children. The authors apply a heuristic based on the number of parent and child concepts to discard such uninformative nodes. The remaining concepts are then linked according to the retained broader‑narrower edges, producing a set of deeper hierarchies that together form the folksonomy.
The paper situates its contribution within related work. Earlier ontology‑extraction methods use linguistic patterns (e.g., “such as”) or statistical subsumption models on tag co‑occurrence, but these approaches are ill‑suited for the unstructured, noisy tags typical of social media. Tag‑based clustering and centrality methods also struggle with the popularity‑generality bias. The authors argue that collection‑set relations are less prone to this bias because users are unlikely to place a highly specific collection under a very generic one unless the relationship truly reflects a broader‑narrower semantics.
Limitations are openly acknowledged. The framework does not address path selection when multiple valid paths exist between the same concepts, nor does it resolve synonymy or polysemy (e.g., “Washington” the city vs. the state). Moreover, the study lacks a quantitative evaluation; the authors rely on informal inspection to claim that the generated hierarchies are “reasonable and non‑trivial.” Future work is suggested to incorporate disambiguation, more sophisticated conflict resolution, and rigorous performance testing in real‑world applications such as search or recommendation.
In summary, the paper presents a straightforward yet effective method for harvesting user‑specified hierarchical relations from Flickr, filtering noise through majority voting, and assembling a coherent folksonomy. By leveraging explicit collection‑set structures rather than flat tags, it mitigates the popularity‑generality problem and demonstrates that large numbers of shallow, noisy hierarchies can be merged into a useful classification system. The approach is attractive for its simplicity, scalability, and potential applicability to other social platforms that expose user‑defined hierarchical metadata.
Comments & Academic Discussion
Loading comments...
Leave a Comment