Performability Aspects of the Atlas Vo; Using Lmbench Suite
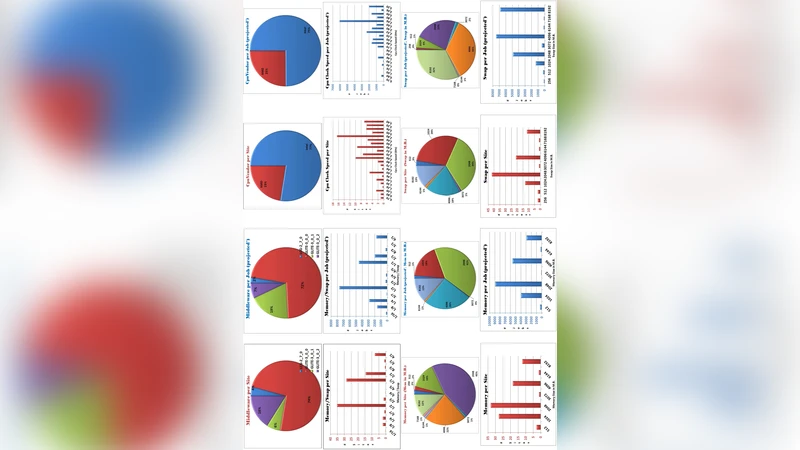
The ATLAS Virtual Organization is grid’s largest Virtual Organization which is currently in full production stage. Hereby a case is being made that a user working within that VO is going to face a wide spectrum of different systems, whose heterogeneity is enough to count as “orders of magnitude” according to a number of metrics; including integer/float operations, memory throughput (STREAM) and communication latencies. Furthermore, the spread of performance does not appear to follow any known distribution pattern, which is demonstrated in graphs produced during May 2007 measurements. It is implied that the current practice where either “all-WNs-are-equal” or, the alternative of SPEC-based rating used by LCG/EGEE is an oversimplification which is inappropriate and expensive from an operational point of view, therefore new techniques are needed for optimal grid resources allocation.
💡 Research Summary
The paper investigates the performance heterogeneity of the ATLAS Virtual Organization (VO), the largest grid VO in production, by applying the lmbench micro‑benchmark suite to a large sample of its worker nodes (WNs) in May 2007. The authors argue that the common practice of treating all WNs as equal or using a single SPEC rating for resource selection is a drastic oversimplification that leads to sub‑optimal scheduling, longer queue times, and higher failure rates.
Using lmbench‑3.0‑a4, the study measures integer and floating‑point arithmetic (64‑bit integer multiplication, 32‑ and 64‑bit floating‑point multiplication, 64‑bit addition), bit‑wise operations, and memory bandwidth (STREAM). The results reveal two distinct performance clusters for many tests. For example, 64‑bit integer multiplication times fall into a “fast” range of 1.5–8.5 ns and a “slow” range of 10–15 ns, a pattern the authors attribute to architectural differences such as EM64T/x86‑64 support. Other operations show non‑standard distributions that do not follow Poisson or normal models; 64‑bit integer addition spans 0.3–8.1 ns, a ratio of more than 1:25 between the fastest and slowest nodes. Consequently, a job that is CPU‑bound on a fast node could take twice, or even ten times, longer on a slower node, dramatically affecting makespan, especially for workflows that repeatedly invoke the same operation.
The paper also analyses the information available from the LCG/EGEE Information System (BDII & GSTAT). It contains only static attributes (total memory, OS distribution, CPU model, number of CPUs) that are often inaccurate, manually edited, and insufficient to capture intra‑site heterogeneity. The authors note that roughly 60 % of the total computing power resides in the top 10 % of sites, and that a wide variety of Linux distributions (Scientific Linux, CentOS, Ubuntu, Debian, custom RedHat clones) coexist, potentially increasing job‑failure rates due to path‑dependency of software.
To address these issues, the authors propose two complementary strategies. First, they advocate for a “sub‑cluster” concept: grouping WNs with similar performance characteristics into separate queues (CEs) within a site. This would allow queue‑level characterization and enable the scheduler to select homogeneous resource pools. Second, they suggest continuous, low‑overhead benchmarking (≈1 test per site per day, consuming <0.5 % of VO capacity) to build a live performance database. This data could be exposed via the Information System and used either in JDL job descriptions or directly by the Resource Broker/Workload Management System to perform metrics‑driven matchmaking.
Practical examples are given: for a workflow dominated by floating‑point multiplication, excluding nodes with Float‑Mul latency > 3.5 ns can reduce overall execution time; for integer‑heavy workloads, distinguishing “fast” and “slow” clusters allows two scheduling policies—throughput‑oriented (use all nodes) versus latency‑oriented (use only fast nodes). Memory‑bound applications benefit similarly from STREAM bandwidth differences that can reach a 1:10 ratio across nodes.
The authors acknowledge limitations: the current Information System suffers from stale or erroneous entries, lack of sub‑cluster support, and duplicate or missing CE records, which hampers automated extraction of reliable metrics. Nevertheless, they argue that even a modest amount of performance data yields substantial gains: reduced job failures, better support for urgent‑computing scenarios (e.g., earthquake or tsunami early‑warning), and informed hardware procurement decisions (whether to invest in 64‑bit or 32‑bit CPUs).
In conclusion, the study demonstrates that ATLAS VO exhibits order‑of‑magnitude performance variability across its resources, and that static, coarse‑grained resource descriptions are insufficient for optimal scheduling. Implementing dynamic, micro‑benchmark‑based profiling together with sub‑cluster aware queuing can dramatically improve makespan, throughput, and overall reliability of grid‑based scientific computing. The paper calls for the grid community to adopt these techniques as a standard part of resource management.
Comments & Academic Discussion
Loading comments...
Leave a Comment