Finger Indexed Sets: New Approaches
In the particular case we have insertions/deletions at the tail of a given set S of $n$ one-dimensional elements, we present a simpler and more concrete algorithm than that presented in [Anderson, 2007] achieving the same (but also amortized) upper b…
Authors: Spyros Sioutas
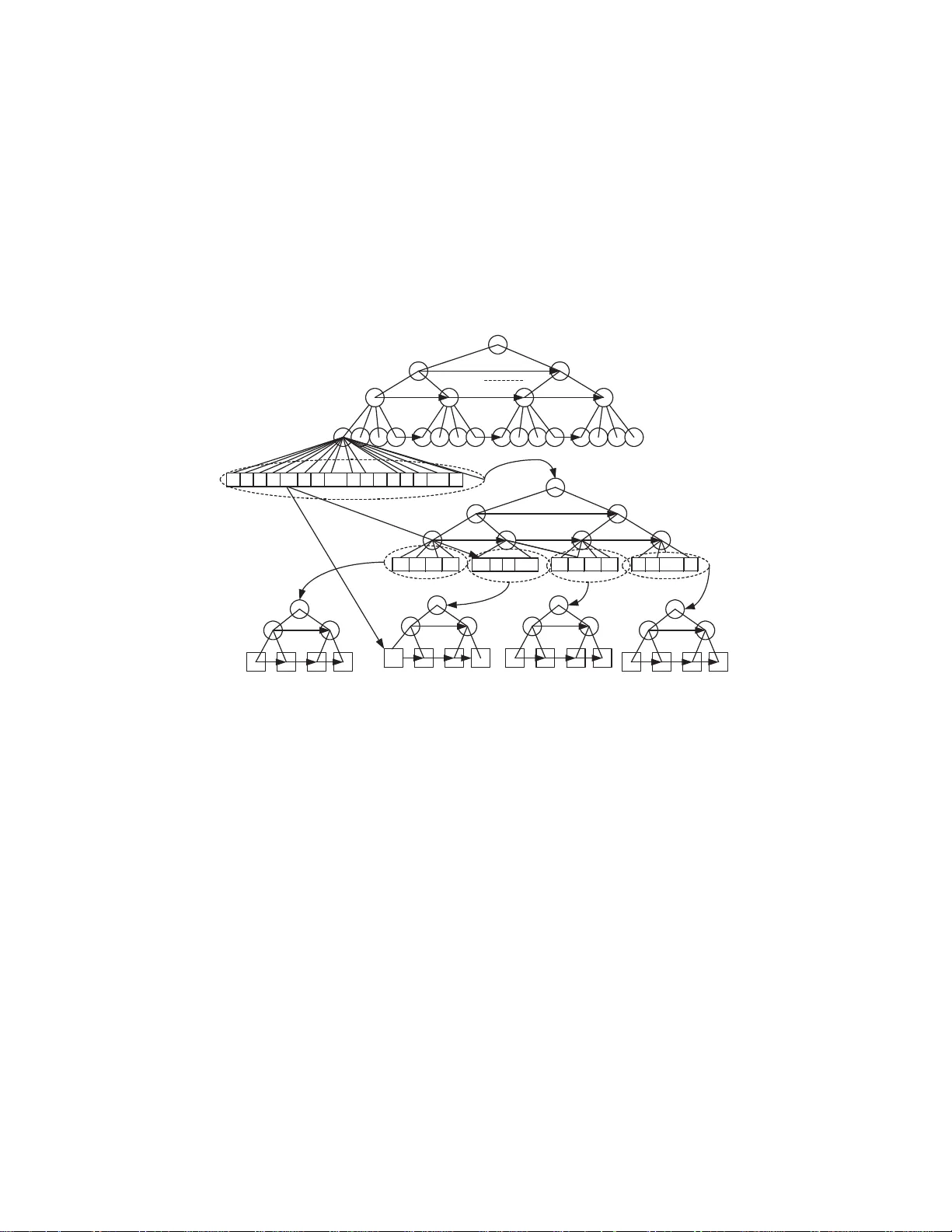
Finger Indexed Sets: New Approaches 1 Sp yros Sioutas (Ionian Univ ersity Corfu, Gr eece sioutas@io nio.gr) Abstract: In the particular cas e we ha ve insertions/deletions at the tail of a given set S of n one-dimensional elemen ts, w e present a simpler and more concrete algorithm than that presented in [Anderson, 2007 ] achieving the same (b ut also amortized) upp er b ound of O ( p log d/log l og d ) for finger searc hing qu eries, where d is the num b er of sorted keys b etw een the finger elemen t and the target element we are lo oking for. F urthermore, in general case we ha ve insertions/deletions anywhere we present a n ew rand omized algorithm achieving the same ex p ected time b ounds. Ev en the n ew solutions achiev e the optimal b ounds in amortized or exp ected case, the adv antage of simplicity is of great importance due to practical merits w e gain. Key W ords: Dictionary Problem, Algorithms and Data Stru ct u res, finger searc hing, Nested Balanced Distributed T rees, Randomization, Com binatorial Games Category: E.1, E.5 1 In tro duction By finger s earch we mean that we can hav e a finger p ointing at a so r ted key x when searching for a key y . Here a finger is just a re fer ence returned to the user when x is inserted or searched for . The goal is to do better if the num- ber d of so r ted keys be t ween x and y is small. Also, we hav e finger updates, where for deletions o ne has a finger on the key to be deleted, and for ins ertions, one has a finger to the k ey after whic h the new key is to be inserted. In the compariso n-based model of computation Ramman [Raman, 1992] has pr ovided optimal b ounds, s uppo rting finger sear ches in O ( log d ) time while supp orting finger updates in constant time. On the p ointer machine, Br o dal et al. [Bro dal, 2003] hav e s hown how to s upp or t finger searches in O ( l og d ) time and finger up- dates in constant time. Finally , Anderso n and Thorup pr esented in [Anderson, 2007] optimal b ounds on the RAM; namely O ( p l og d/l og l og d ) for fing e r sear ch with cons ta nt finger upda tes in w orst-ca se. This optimal solution is a lso very complicated a nd as a consequence no t a t a ll pra ctical. In this pap er, assuming that the inser t/delete op erations o ccur at the tail o f set S, we present a new alg orithm bas ed on an implicit Nested Bala nced Dis- tributed T ree (BDT), which handles finger - searching quer ies in optimal amor - tized (and not worst-case) time ( O ( p l og d/l og l og d ))but also in a simpler manner 1 Preliminary vers ion of this pap er was presented in Ad v ances in Informatics, LN CS 3746, pp 134-144, V olos, Greece, Nov em b er 2005 than that presented in [Anderson, 200 7]. Consequently , our metho d is muc h eas- ier to b e implemented. In general case we hav e insertions/ deletions an ywhere we present a new sim- ple randomized algo rithm based on application of oblivious o n-line simple p ebble games [Raman, 19 9 2] upo n a new 2-level h ybrid data structure where the top- level structure is a Level-Linked Ex po nent ial search tree [B eam, 2002] a nd the bo ttom lev el are buckets of sub-logarithmic size. Our new randomized metho d results in the following complexities: O ( p l og d/l og l og d ) and O (1) in exp ected case for finger sear ching and update queries resp ectively . In the follo wing section we review the preliminary data structures. In s e c tion 3 we review in detail an extended outline of our new solution in sp ecial case we have insertions/deletions at the tail of given set. In section 4 w e study the general case we ha ve insertions /deletions anywhere co nstructing a randomized algorithm ac hieving the same o ptimal exp ected time bounds . In section 5 w e conclude. 2 Preliminary Data Structures 2.1 Precomputation T ables Ajtai, F redman and Komlos ha ve shown in [Aj tai, 1984 ] that subsets of the int egers { 1 , . . . , n } of size p olylogar ithmic in n can b e maintained in consta nt time so that predeces sor quer ie s (find the larges t i ∈ S suc h that i ≤ x ) can be p erformed in constant time. In fact, their result is in the cell pro be model of computation; ho wev er, on a logarithmic word size RAM their functions can b e represented by tables that can b e incr e men tally pre computed at a cost of O (1) worst-case time and space per oper ation. The data structure o cc upies spa ce that is linear in the size of the subset. 2.2 F usion T ree A t STOC’90, F redman and Willard [F redman, 1990] sur passed the comparison- based low er b ounds for sorting and searching using the fea tures in a s tan- dard imp era tive pr ogramming languag es such as C . Their key r esult was an O ( l og n/l og l og n ) time bound for deter ministic search ing in linear space. The time b ounds for dynamic searching include b oth sear ching and up dates. Since then muc h effort has b een s pe nt o n finding the inherent complexity of funda- men tal searching problems. 2.3 Amortized Exp onen tial Searc h T ree In 1996 , Anderson [Anderso n, 1996] int ro duced exponential sea rch trees as a general technique reducing the problem of sea rching a dyna mic set in linea r space to the pro blem of cr e ating a search structure for a s ta tic set in po lynomial time and space. The search time for the static set essentially beco mes the amor tized search time in the dy namic set. F ro m F r e dma n a nd Willard [F r e dman, 199 0 ], he got a static structure with O ( √ l og n ) search time, and thus he o btained an O ( √ l og n ) time bo und for dynamic searching in linear space . Obviously the cost for s e arching is worst-case while the cost for up dates is amortized. 2.4 Beam-Fic h (BF) structure In 20 02 Bea me and Fic h [Beam, 20 02] showed that O ( p l og n/l og l og n ) is the exact worst-case co mplexity of sear ching static set using polynomia l space. Us- ing the abov e mentioned exponential sea rch trees, they obtained a fully dy- namic deterministic s earch structure suppor ting search, insert, and delete in O ( p l og n/l og l og n ) amortized time. The BF str ucture can use randomizatio n (for rehashing) in order to achiev e O ( l og l og N ) exp e cted upda te time, where N is the univ erse. The amortized o pe rations ar e v ery s imple to b e implemen ted in a sta ndard imp era tive programming lang uage such as C or C + + . 2.5 W orst - Case Expo nen tial Searc h T ree Finally , in 2007, Anderson and Thorup [Anderson, 2007] dev elop ed a worst- case version of exp onential sea rch trees, giving an optimal O ( p l og n/l og l og n ) worst-case time bound for dynamic sear ching. They also e x tended the ab ov e result to finger sear ching pr oblem, achieving the sa me optimal time b ound O ( p l og d/l og l og d ). The rebuilding o p e rations ar e also very complicated and very difficult to b e implemen ted in a s ta ndard imp er a tive prog ramming lang uage such as C or C + +. 3 A sp ecial case of finger searc hing W e use as a base structure a B alanced Distribution T ree (BDT). In s uch a tree the degree of the no des a t level i is defined to b e d ( i ) = t ( i ), wher e t ( i ) indica tes the num b er of no des pr e sent at level i . This is r e quired to hold for i ≥ 1, while d (0) = 2 and t (0) = 1. It is easy to see that we also have t ( i ) = t ( i − 1) ∗ d ( i − 1), so putting together the v arious co mp onents, we can solve the recur rence and obtain for i ≥ 1: d ( i ) = 2 2 i − 1 , t ( i ) = 2 2 i − 1 . One of the merits of this tree is that its heigh t is O ( l og l og n ), wher e n is the num be r o f elements stored in it. W e consider the case we hav e only insertions/deletio ns at the end of the set S , for example i nser t ( y ) or del ete ( y ) such as y > maximum { x i ∈ S } , 1 ≤ i ≤ n or y = m a ximum { x i ∈ S } , 1 ≤ i ≤ n respectively . W e build our structure b y rep eating the same kind of BDT tre e-structure in each g roup of no des having the s ame a nc e s tor, and doing this r ecursively . This str ucture may b e imp ose d throug h ano ther set of p ointers (it helps to think of these as different c o lor p ointers). The innermo st level of nesting will be characterized b y having a tree-structure, in which no more than tw o no des shar e the same direct ancestor . Figure 1 illustr ates a s imple exa mple (for the s ake of clarity we have omitted from the picture the links b etw een no de s with the same ancestor). F S1 F S1 S2 A 4 [1..4] L 8 [1..16] A 1 [1..2] A 2 [1..2] A 3 [1..2] A 5 [1..4] F S1 S2 1-st nested subtree 2-nd nested subtree 3-rd nested subtree 4-th nested subtree 1-st pointer 2-nd pointer Figure 1: The Level-linked lea f-oriented nested BDT tree Thu s, multiple independent tree str uc tur es are impo sed on the collection of no des inserted. Ea ch element inse r ted contains pointers to its repr esentativ es in each of the trees it b elong s. W e ne e d now to de ter mine what will be the maxim um num b er of nesting trees that can o ccur for n elements. Observe tha t the maxim um num b er of no des with the same direct a nce stor is d ( h − 1). W ould it b e p oss ible for a second level tree to have the same (or bigg er) depth than the outermost one? This w ould imply that P h − 1 j =0 t ( j ) > d ( h − 1) As other w is e we w ould b e able to fit all the d ( h − 1) elements within the first h − 1 levels. But we need to remember that d ( i ) = t ( i ), thus d ( h − 1)+ P h − 1 j =0 d ( j ) < d ( h − 1 ) This w ould imply that the num b er of nodes in the first h − 2 lev els is negative, clearly impos sible. Thus, the s econd level tree will hav e depth strictly low er than the depth of the outermos t tree. As a consequence, the maximum num b er of nesting o f tre es k that we ca n hav e is itself O ( l og l og n ). The basic intuition b ehind the use of BDT tree, is the reduction o f the whole set of O ( n ) elements to the appropr iate subset (nested s ubtr ee of fig ure 1) of O ( d ) elements. Then by applying in this subset the simple a mortized solution for general sea rching problem presented in [Beam, 2002], w e a chiev e an opti- mal amortized solution for fing er searching pr oblem. Despite the fact that the searching time complexity of our structure is amortized and not worst-cas e as it happ ens in [Anders on, 2007] s olution, it’s simplicit y also is o f g reat impor tance since we c a n ga in many practica l merits. W e equip each no de(leaf ) o f level i , say W i , with a s earching infor ma tion array A [1 . . . d ( i )] ( L [1 . . . d ( i )]), where d ( i ) is the size of the array at level i . W e organize the elements of the arrays a bove with the s tructure o f Bea m- Fich presented in [Beam, 20 02], le t’s call it B F ( W i ). W e a lso equip each lea f with k = O ( l og l og n ) p ointers to its resp ective copies at nested lev els (see in Fig ure 1 the p ointers from leaf f ). Eac h element of S is stored at most in O ( l og l og n ) levels, so the space of structure is non- line a r O ( nl og l og n ) and the up date (in- sertion/deletio n) o p e r ation is per formed in O ( l og l og n ) w orst-ca se time. In order to achiev e linear space and O (1) worst-ca se up date time w e use the buck eting techn ique. The esse nce o f the buc keting metho d is to get the b est feature s o f these tw o differ ent structures by combining them into a t wo-level structure. The data to b e stored is partitioned into buck ets and the chosen data structure for the repr e sentation o f each individual buck et is different from the representation of the top-level data structure, representing the collectio n of buck ets (for similar applications of this data structuring pa r adigm see a lso [Ov ermar s, 19 82], [Tsak a- lidis, 19 84], [Raman, 1992]). Mor e sp ecifically , we partition the elements of the set into co ntiguous buck ets of size O ( l og l og n ), with ea ch buck et b eing repre- sented b y the linear list sch eme and w e s tore the first element of each buc ket in the leaf-oriented nested balanced distributed tree scheme as its r epresentativ e. When a n item is inserted it is appended to the tail of the list implementing the last incomplete buck et. If the size of this bucket b ecomes O ( l og l og n ), then a new buc ket is created containing only the inserted element, and we sp end fur- ther O ( l og l og n ) time, in order to insert this element into the top-level structure. W e ha ve a total of O ( n/l og l og n ) r epresentativ es, each of whic h must b e inse r ted at mo s t in O ( l og l og ( n/l og l og n )) = O ( l og l og n ) nested lev els. F urthermore , at each of these levels (leaf-levels) we must upda te the resp ective B F structures in O ( l og l og ( d ( n i ))) worst-case time resp ectively , where d ( n i ) is the siz e of the resp ective arr ay L , a t the n th i , 1 ≤ n i ≤ O ( l og l og n ), level of nesting. Mo r e precisely the dynamic B F structure requires amortized upda te time but this sp ecial s e mi-dynamic ca se o f up dating implies the following: 1. If n < 2 log 2 logN /log log log N then the BF structur e has o nly one part, the simple static da ta structure pre s ented in[Anderson, 19 96]. In this case we m ust execute a num b er of partial rebuilding op era tions at the rig ht subtrees only of the whole structure, ensuring alwa ys that these subtrees hav e size at least n 2 ∗ ⌈ n 4 / 5 ⌋ ± 1 and at most 2 ∗ n ⌈ n 4 / 5 ⌋ ± 1, as follows. When an up date causes a r ight-subtree to vio late this condition, we exa mine the sum of the sizes of that subtree and its immediate neighbo r which is alwa ys a full subtree with 2 ∗ n ⌈ n 4 / 5 ⌋ ± 1 elements, tr ansferring the prop er num b er of ele ments fr o m the full neighbor no de to the rig ht-most one which we try to r econstruct. Un til the next reco nstruction we ha ve all the t ime to spre a d incr ement ally the reconstructio n c o st, a chieving O (1 ) worst-case time. So, for the O ( l og l og n ) levels of the tree depicted in figur e 1 the total a mount of upda te tim e b ecomes O ( l og l og n ) in worst-cas e. 2. If n ≥ 2 log 2 logN /log log log N or p l og n/l og l og n ≥ log l og N / ( √ 2 log l og l og N ) the B F structure consists o f t wo parts. The first part is a x − f ast tr ie of Willard [Willard, 19 83] with branching factor 2 k and depth u which orga- nizes the top 1 + 2 ∗ ⌈ log u ⌉ levels for a set of s ≤ n strings with length u , ( u = 2( l og l og N ) / ( l og l og l og N ) ⇒ √ n ≥ u u ≥ l og N ) ov er the alphab et [0 , 2 k − 1 ]. In tuitively the x − f ast trie reduce s the predecesso r and gen- erally the dictionary problem fr om a universe o f size 2 k to a s ubproblem with universe of size 2 b , where k = ( l og N ) / 2 1+2 ⌈ logu ⌉ ≤ ( l og N ) / 2 u 2 < u u − 2 , 2( u − 1 ) 2 − 1 k < l og N ≤ b and b ≥ 2( u − 1 ) 2 − 1 k . The se c ond par t consists of the a ppropriate hash functions constr ucted fo r each r e sulting sub- problem. When an insertion/deletion is o ccurred w e hav e to insert/delete the appropria te hashed v alues. Since we inv estigate the sp ecial c a se where the upda tes o ccur a t the tail only , the up date of the hash functions describ ed ab ov e can b e done in O (1) worst-case time. So , for the O ( l og l og n ) levels of the tree depicted in figure 1 the total amount of update time b eco mes again O ( l og l og n ) in worst-cas e. Due to the fact that d ( n i +1 ) = p d ( n i ) a t lev el i , the total a mount of up date op erations a t the appr o priate B F structures can be expres sed as follows: O ( l og l og ( d ( n 1 ))) + O ( log log ( p d ( n 1 ))) + O ( l og l og ( q p d ( n 1 ))) + . . . = O ( l og log n ) Spreading the total O ( l og l og n ) insertion co st, over the O ( l og l og n ) size o f e a ch buck e t, we achieve an O (1) a mortized insertion cost. F or the same r eason as ab ov e it is easy to pr ove that the whole spa c e is linear. W e eliminate the amor- tization by sprea ding the time cost for the insertion of the representativ e o ver the next O ( l og l og n ) upda tes of buc ket. Due to the fact that we ha ve no a priory knowledge of n , we use the global r ebuilding technique [O vermars, 19 81] in order to retain the buck ets in a a ppropriate size of O ( l og l og n ), where n is the cur rent nu mber of elements. The question is: has any affect to the search ( f , s ) query the fact that the time, in which the query is per formed, the incremental pro cess a nd consequently the insertio n of the buck et’s repr esentativ e in all po ssible nested levels, ha s not finished yet? In the following lemma we build the appr o priate algorithm a nd we show that there is no p ossibility of such an affect. Lemma 1. The search ∗ ( f , s ) op er ation is c orr e ct and r e quir es O ( p ( log d/log log d )) amortize d time Pr o of. Let’s give the new sear ch ∗ ( f , s ) a lg orithm. r f = r epresentativ e of bucket in which finger f belo ngs to r s = r epresentativ e of bucket in which s b elongs to r n =represe n tative of not full buck et Pro cedure S ear ch ∗ ( f , s ) 1. Begin 2. If f, s belong to same bucket (full or not) or s > r n then acces s directly s 3. else f sear ch ( r f , r s ) / * this pro cedur e follows */ 4. End Pro cedure f se a rch ( f , s ) 1. Begin 2. W = F ather(f ) 3. If s < A w [ rig htmost ] then go to L 1 /* f,s have the same parent */ 4. Else Begin 5. Repe a t 6. W1=F a ther (W) 7. If A w 1 [ rig htmost ] < s < A neighbour w 1[ r ightmost ] /* that means f,s b elong to neighbo rs no des W1 and neighbourW1 respec - tively */ 8. then f sear ch ( l ef tmostl eaf ( T neighbour w 1 ) , s ) 9. Un til s < A w 1 [ rig htmost ] 10. go to L2 11. end 12. L1: Beg in 13. j:= - 1, f=L[i] /* Find the appropr iate nested subtree s uch as F ather ( f ) 6 = F ather ( s ) */ 14. Repeat 15. j=j+1 16. Un til s ≤ A hj iD I V 2 2 j k 2 2 j + 2 2 j i 17. Access the ( j + 1) th copy o f f ( f j +1 ) /* b y F ollowing the ( j + 1) th po int er from finger (leaf ) f 18. f se arch ( f j +1 , s ) 19. End 20. L2: Beg in 21. j:=0 22. Repeat 23. j:=j+1 24. search for s in B F ( W j ) s tructure /* A t each no de o f the W 1 , W 2 , . . . , W k , s pa th sea rch for s at B F ( W 1 ) , . . . , B F ( W k ) structures resp ectively */ 25. un til s is found 26. end 27. END 1. S ear ch ∗ ( f , s ): According to [Ajtai, 1984] the statement 2 requires O (1) worst-case time. In statement 3 we call the pro cedure f sear ch ( f , s ) the c o m- plexity of which is analyze d as follows. 2. f search ( f , s ): When f , s hav e the sa me parent (see f , s 1 in fig ure 1), state- men t 3, w e m ust determine the appropriate nes ted- subtree of O ( d ) elements in which f , s do not belong to the s ame collection. So, in r ep e at-lo op 14-1 6 we execute exp onential steps in order to find an a ppropriate v a lue j w hich defines the collection (o f 2 2 j elements) in which the distance d ( f , s ) b elongs to and c o nsequently the appropria te ( j + 1) th po int er from finger (leaf ) f to its resp ective copy f j +1 . Then we call r e cursively the same routine (state- men t 18). O bviously the rep eat-lo op 14 -16 r e quires O ( l og l og d ) s teps due to the fact that the distance d betw een f and s is at least d ≥ 2 2 j . F ro m fing er f we hav e a num ber of k = O ( l og l og n ) p ointers, so by organizing them in a structure of [Ajtai, 19 8 4] we can access the ( j + 1) th po int er in O (1) time. If f , s do not hav e the same par e n t we execute the rep ea t-lo op o f 5-9 state- men ts that req uires O ( l og l og d ) steps in order to find the near est commo n ancestor of f and s , W 1 = nca ( f , s ). If f , s b elong to neighbors nodes W 1 and neig hbour W 1 resp ectively , (statement 7) we a ccess the ne ig hb ourW 1 no de in O (1) time by following the neighbor p ointer fro m W 1 to ne ig hb ourW 1 and we ca ll recurs ively the same sear ch routine with new fin ger the left- most leaf of the T neighbour W 1 subtree, els e by executing the rep eat-lo op of 22-26 statements, we visit the appr o priate search pa th W 1 , W 2 , . . . , W r , s a t each node o f which we search for s at B F ( W i ) str uctures, 1 ≤ i ≤ r and r = O ( l og l og d ),in O ( p l og d ( w i ) /l og l og d ( w i )) amortized time, where d ( w i ) is the deg ree of no de w i . This ca n b e expressed b y the following sum: P r = O ( log log d ) i =1 q logd ( w i ) loglo gd ( w i ) Let L 1 , L r the levels o f W 1 and W r resp ectively . So , d ( w 1 ) = 2 2 L 1 and d ( w r ) = 2 2 L r But, d ( w r ) = O ( d ), so L r = O ( l og l og d ). Now, the previo us sum can be expressed as fo llows: q 2 L 1 L 1 + q 2 L 1 +1 L 1 +1 + . . . + q log d log log d = q log d log log d W e denote that the recur s ive calls o f statements 8 , 18 are ex e cuted o ne time only (this fact stems from the pseudo co de structure w e us e d), conse q uent ly there is no reas on to pro duce and solve the resp ective r ecurrence e q uation, so, very simply the total time b eco mes T = O ( q logd loglo gd ). 4 A randomized algorithm w ith the same exp ected time b ounds Let’s give a brief description of the combinatorial pebble games we have to rely on for constructing our new s olution. P ebble Game s [Raman, 1992] : These games ar e play ed b et ween tw o play e r s, play er I (increas e r ) and player D (decreaser ) on a set o f n piles of pebbles, which are initially empty . The s e games hav e the following general form: the ga me is play ed in r ounds, each consisting of o ne mov e from each player. Play er I , on his mov e, increas es the num ber of p ebbles on of some of the piles, following which; play er D decrea ses the n um b er of p ebbles on so me pile. Let M b e the maximum v alue o f an y v aria ble at any p oint in the g a me. Play er I ′ s ob jectiv e is to maximize M , and player D ′ s to minimize it. Typically , play er D is an algorithm and pla yer I the en vironment. Oblivious P e bble Games [Raman, 1992] : In this t y pe of game play er I reveals his mo v es one at a time to pla yer D , but player D ′ s mov es (and the sta tus of the piles) a r e hidden from him. Play er D may use randomizatio n to make his mov es unpredictable to pla yer I . Here we are in terested either in the exp ected v alue of M or in studying the tails of M ′ s distribution. Als o , w e typically restrict the num ber of mov es this game is play ed, since, as it so ha ppe ns , the longe r the game is play e d, the more likely it is that play er I will come close to approaching his per formance in the on-line version of the g a me (for mo re details you can also see [Raman, 1 992]). According to Oblivious On-line Discrete Z eroing Game [Raman, 1992 ] there is a D-str ategy that ensures with high probability ( p > 1 − n − a , for any consta nt a > 0, for sufficien tly large n ) that ov er n mo ves, M ∈ O ( cl og l og n + cl og c ), where c is a n integer, c > 1. This str ategy is des crib ed from the following alg orithm1: Algorithm1 : Let c > 1 an in teger and δ 1 , . . . , δ n non-negative integers such that P n i =1 δ i = c . The n player D , on his move, does the following: 1. Picks i { 1 , . . . , n } with probability δ i /c a nd s ets x i to zer o 2. Picks i such tha t x i = max j { x j } a nd zero es x i . F or c = O ( l og l og n ), M ∈ O ( l og 2 l og n ) with high pr obability . Base d on D- strategy o f Alg orithm1 let’s describ e our r andomized Algorithm2: Algorithm2 : Let n b e the maximum num be r of keys present in the data structure at any previous time. In a similar wa y with that presented in [Raman, 1992], we can show that making the buck ets b e of s ize O ( l og 2 l og n ) and using as top-level the structure of Beam-Fich pres ent ed in [Bea m, 2002 ] with lev el-links suffice for our purpo ses, yielding a simple a lgorithm. W e define the fullness Φ ( b ) of a buck et b as in [Rama n, 1992 ]: Φ ( b ) = | b | /log 2 l og n . W e will ensure that 0 . 5 ≤ ( b ) ≤ 2. W e also define the criticality of a bucket b to be ρ ( b, n ) = 1 αlog log n max 0 , 0 . 7 l og 2 log n − | b | , | b | − 1 . 8 log 2 log n , for a n appropr iately chosen cons ta nt α . A buc ket b is ca lled critical if ρ ( b, n ) > 0. T o maintain the size o f the buck ets, every c = αl og l og n updates, we do the following: 1. W e chec k the i th buck e t, i ∈ 1 , . . . , n/l og 2 l og n , with probability δ i /c meaning that w e construct a randomized set of c = O ( l og l og ( n/l og 2 l og n )) = O ( l og l og n ) collections e a ch of whic h has O ( n/l og 3 l og n ) buc kets, w e c hoice one o f these collections rando mly and finally the buc k et o f co llection in whic h δ i = max j { δ j } up dates ha ve o ccurred. If this buc ket has non-zero critica lit y we apply the reba lancing trans formations of step 3. 2. W e check the mo st critical buck et and if it ha s non-zero cr iticality we apply the fo llowing rebalancing transformations. 3. Split : if φ ( b ) > 1 . 8 split the buc ket into t w o parts of approximately equa l size. T ransfer : If φ ( b ) < 0 . 7 and one of its a djacent buc kets b ′ has φ ( b ′ ) ≥ 1 then transfer element s from b ′ to b . F use : If φ ( b ) < 0 . 7 and transferring is not po ssible, then fuse with an adja- cent buck et b ′ . It is clea r that when a critical bucket is rebalanced, it bec omes non-critical. In addition to the time required to split/fuse buc kets, a buc ket rebala ncing step may requir e O ( log l og N ) exp ected time to inser t/delete a buc ket repres ent ative to/from the top-level tree. The top-level tree is the B F structure, whic h supp orts upda tes in O ( l og l og N ) exp ected time. Since the total work to reba lance a buc ket is O ( l og l og N ), we can p erform it with O (1) work per upda te spread ov er no more than αl og l og n up dates, where the chosen para meter α expressed as follows: α = O ( loglo gN loglo gn ). F or every r eal computer application N never exceeds the num b er 2 64 = 2 2 6 , thus α could b e considere d as a co nstant muc h less than 6 . So, if we can p ermit every buck et to be of size Θ ( l og 2 l og ˆ n ), where ˆ n the num b er of cur rent elements, we ca n guarantee that betw een rebala ncing o pe r ation of top-level tree [Beam, 200 2 ] there is no p o ssibility for an y other such op era tion to o ccur and consequently the incremental spr ead o f w ork is p oss ible. Let p b e a finger. W e search for a key k which is d keys a wa y from p . If p , k belo ng to the same buc ket of size O ( l og 2 l og n ), w e ca n a ccess direc tly the k a ccording to [Ajtai, 1984 ], else we firs t chec k whether r k (representativ e o f buck et in which k belo ngs to) is to the left o r r ight of r p , (representativ e of buc ket in which finger p belo ngs to ) s ay r k is to the rig ht of r p . Then we walk tow ards the ro ot, say w e r eached node u . W e c heck in O ( p l og d/l og l og d ) time whether r k is a de s cendant of u o r u ′ s right neighbor o n the same level of u or u ′ s rig ht neighbor resp ectively . If not, then we pro ceed to u ′ s father. Otherwise w e tur n ar o und and search for k in the ordinary w ay . Suppo se that we turn around at no de w of height h . Let v be that son of w that is on the path to the finger p . Then all descendants of v ′ s right neighbor lie b etw ee n the finger p and the k ey k . The s ubtr ee T w is a B F structure for d elements, so, the tota l time bound T becomes: T = O ( p l og d/l og l og d ) So, we pr ov ed the fo llowing theore m: Theorem 2. Ther e is a r andomize d algorithm with O (1) and O ( q logd loglo gd ) ex- p e cte d time for up date and finger se ar ching qu eries r esp e ctively. 5 Conclusions In this pap er w e fo cused on the finger searching problem. In spe c ia l case w e hav e insertio ns / deletions at the tail o f a given set S , we presented an extended outline of a simpler algorithm than that presented in [Ander son, 200 7] matching the optimal upper bound in amor tized cas e. Finally , in gener al case we have insertions / deletions an ywhere; we were based on a special com binatorial p e b- ble game pr esented in [Rama n, 199 2] in order to present a simple rando mized algorithm that achieves the same o ptimal expected b o unds. Even the describ ed solutions achiev ed the optimal b o unds in amortized and exp ected ca se resp ec- tively , the a dv antage of simplicity is of great impor tance due to practical merits we can gain. Ac kno wledgements. The author w ould lik e to thank the Progr am PYTHAGO- RAS, for funding the a b ove work. References [Aho, 1974] A.V.Aho, J.E.Hop croft, and J.D.Ullman. The Design and An alysis of Computer Algorithms. Addison-W esley , Reading, MA, 1974. [Ajtai, 1984] M.Ajtai, M.F redman, and J. Komlos. Hash functions for priorit y queues. Information and Contro l, 63:217-225, 1984 [Anderson, 1996] Anderson, A., ”F aster deterministic sorting and searching in linear space” 37th Annual I EEE Symp osium on F ound ations of Comput er Science, 1996. [Anderson, 1997] A. And erson and M. T horup. Ex p onential searc h trees fo r f aster deterministic searc hing, sorting and p riorit y queues in linear space. Manuscript, 1997. [Anderson, 2007] A. A nderson and M. Thorup . Dyn amic Ordered Sets with Exp onen- tial Search T rees, Journal of the AC M, 200 7, Com b ination of results presented in FOC S 1996, STOC 2000 and SODA 2001. [Beam, 2002] Paul Beam and F aith Fic h, O ptimal Bounds for th e Predecessor Problem, Journal of Computer and S ystem Sciences, 65(1):38-72, Augu st 2002. Sp ecial issue of selected pap ers from 1999 STOC conference. [Brodal, 2003] Gerth Stolting Brod al, George Lagogiannis, Christos Makris, Athana- sios K . Tsak alidis, Kostas Tsic hlas: Optimal finger search t rees in the p ointer ma- chine. J. Comput. Syst. Sci. 67(2): 381-418 (2003) [Dietz, 1987] P .F. Dietz and D.D. Sleator. Two algorithms for main taining order in a list. In Proc. 19th AC M STOC, pages 365-372, 1987. [F redman, 1990] M.L. F redman and D.E. Willard. Su rpassing the information theoretic b ound with fusion trees. . Comput. Sy st. Sci., 47:424-436, 1993. Announ ced at STOC ’90. [Levco p oulos, 1988] C. Lev cop oulos and M. H . Ov ermars . A balanced searc h tree wi th O(1) wo rst-case up d ate t ime. Acta I nformatica, 26:269 -278, 1988. [Overmars , 1981] M. Overmars and Jan v an Leeuw en, W orst case optimal insertion and deletion metho ds for decomp osable searc hing problems, In formation Pro cessing Letters, 12:168-173, 1981. [Overmars , 1982] M. Overmars, A O( 1) av erage time up date scheme for balanced bi- nary searc h trees, Bulletin of the EA TCS, 18:27-29, 1982. [Raman, 1992] Raman, R. Eliminating Amortization: On D ata S t ructures with Guar- anteed R esp onse Time. PhD Thesis, Universit y of Ro chester, New Y ork, 19 92. Com- puter Science Dept. U. Ro chester, T echnical Rep ort TR- 439. [Ranjan, 1999] D. Ranjan, E. P ontelli, G. Gup ta and L. Longpre, The T emp oral Prece- dence Problem, In Algorithmica 1999 (to app ear). [Tsak alidis, 1984] A. Tsak alidis, Main taining order in a generalized linked list, ACT A Informatica 21 (1984) [Willard, 1983] D.E.Willard. Loglogari thmic wo rst-case range queries are p ossible in space (n). Information Processing Letters, 17:81-84 , 1983.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment