Discovering More Accurate Frequent Web Usage Patterns
Web usage mining is a type of web mining, which exploits data mining techniques to discover valuable information from navigation behavior of World Wide Web users. As in classical data mining, data preparation and pattern discovery are the main issues…
Authors: Murat Ali Bayir, Ismail Hakki Toroslu, Ahmet Cosar
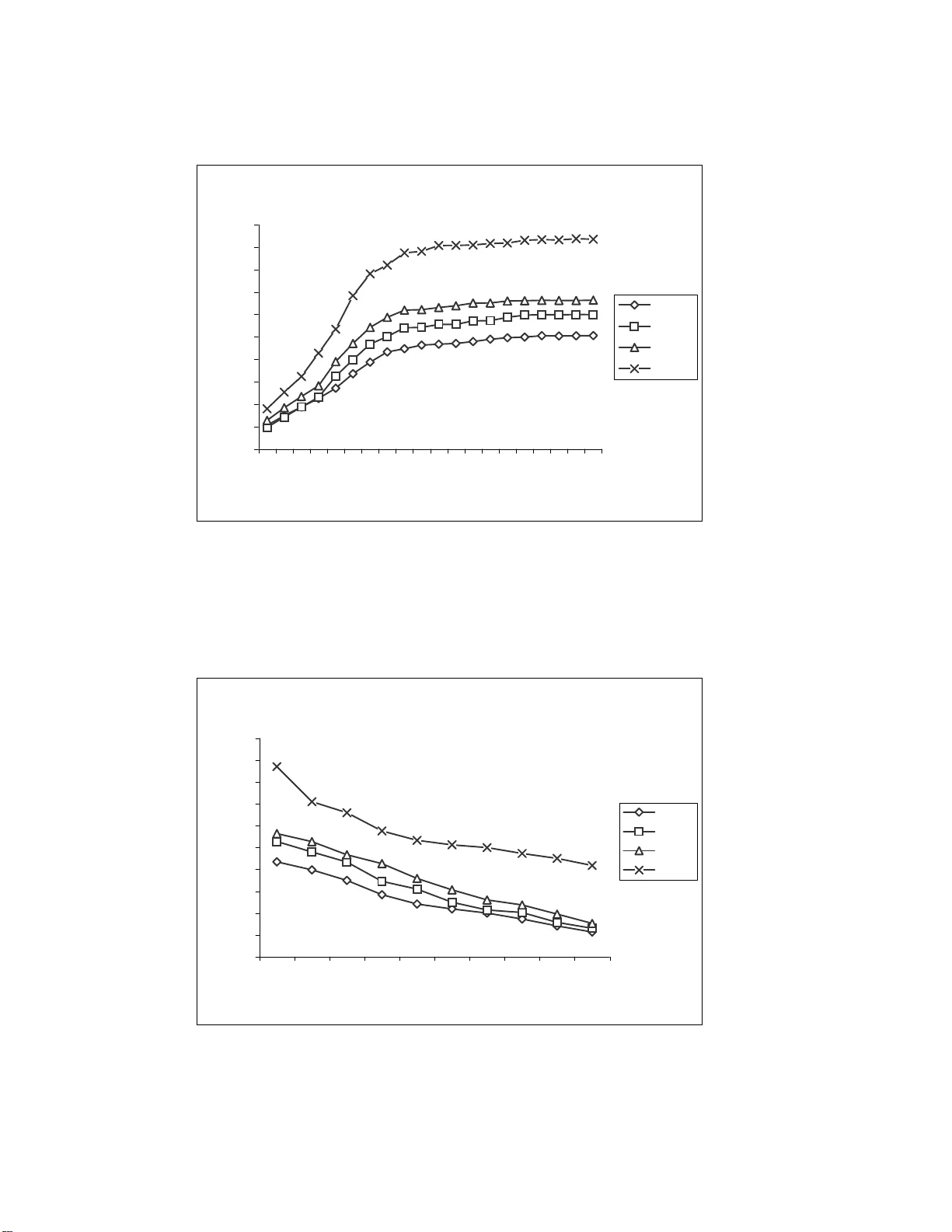
Discover ing M ore Accu rate Frequent W eb Usage Patterns Murat Ali Bayir a , Ismail Hakki T or oslu b , Ahmet Cosar b , Guven Fidan c a Department of Computer Scie nce and Engineeri ng, University at Bu ff alo, SUNY , 14260 , Bu ff alo, NY , USA b Department of Computer Engineering, Middle East T echnical University , 06531 , Ankara, T urkey c AGMLAB Informatio n T echnologi es, C yberPark Cyberpl aza, Bilkent, 06800, Ankara, T urkey Abstract W eb usage mining is a typ e of web mining, which ex p loits data mining techniques to discover v aluable information fr om navigation b ehavior of W orld W ide W eb users. The first phase of we b usage mining is the data processing phase, w hich includes the session r e con s truction operation from server logs. Session reconstruction success directly a ff ects the quality of the fr equent patterns discovered in the next phase . In r eactive web usage mini ng techniques , the so urce data is we b server logs and the to pology of the web page s serve d by the we b server domain. Othe r k inds of information collected during the inte ractive br owsing of web site by use r , such as cookies or web logs containing similar information, ar e not used. The next phase of we b usage mining is d iscovering frequent us er navigation patt erns. In this phase , pattern discovery methods are applied on the reconstructed se ssions obtained in the first ph ase in order to discover frequent us er patterns. In this paper , we propose a frequent web us age pattern discovery method that can be applied after sess ion reconstruction phase . In order to compar e accuracy pe rformance of session r econs truction phase and patte rn discovery p hase, we have us ed an agent simulator , which mode ls behavior of web us ers and ge nerates web user navigation as well as t he log data kept by the web server . Key words: W eb usage mining, ses sion reconstruction, apriori te chnique , agent simulator and web topolog y Email addr esses: mbayir@ cse.buffa lo.edu (Murat Ali Bayir), toroslu@ ceng.met u.edu.tr (I s mail Hakki T oroslu), cosar@ce ng.metu. edu.tr (Ahmet Cosar), guven.f idan@agm lab.com (Guven Fidan). 1 Introduction The goal in web mining [ 6 ] is to discover and ret rieve useful a nd interest ing patterns from a large dataset. The source da ta for web mining contains various information sources in di ff erent formats. W eb usage mining (WU M) [ 25 ] is a new resear ch area which can be defined as a proc ess of applying d a ta mining techniques to discover interesting patterns fr om web usage data. W eb usage mining provides information for better unde rstanding of se rver needs and web domain design requir ements of web-based applications. W eb usage da ta contains information about the identity or origin of web users with their br owsing behaviors in a web domain. W eb pr e-fetching [ 13 , 19 ], link p rediction [ 12 , 9 , 1 ], site r eor ganization [ 21 , 24 ] and web personalization [ 14 , 15 , 16 , 18 ] are common a pplications of WU M. WUM data contains users’ navigation behaviors on the we b. Navigation among web pages by using hyperlinks is the most common action of the web user . T wo web pages can be accepted as related to ea ch other if both of them are accessed in the same user session such that the first page accessed is connected to the second one with a hyperlink. In order to support the claim about two pages being related, such accesses must occur several times. Ther efor e, in WUM, first user navigation sessions must be r econstructed fr om server access logs, and then, frequent patterns in these sessions must be sear ched. Reconstruc tion of accurate user sessions fr om server access logs is a chal- lenging task since access log protoc ol is stateless and connectionless. For r eactive strategies, all users behin d a proxy server will have the same IP number also. Moreover , caching performed by the clients’ bro wsers and pr oxy servers will a ff ect the web log data. These problems can be handled by proactiv e strategies by using cookies and / or java applets. However , these solutions could have been disabled by some clients for security / privacy con- cerns. In such cases proactive strategies become unusable. Reactive session r econstr uction and proactive session r econstr uction strategies use di ff erent data sourc es. Proac tive strategies [ 10 , 20 ] uses raw data collected during run-time which is usually supported by dynamic server pages. Whereas in r eactive strategies [ 7 , 8 , 22 ], server logs are main da ta sour ce. Reactive strate- gies are mostly applied on static web pa ges. Because the content of dynamic web pages changes in time, it is di ffi cult to predict the relatio nship between web pages and obtain meaningful navigation path pa tterns. Ther efor e we r estrict our work to static web pages. As it is stated above, server logs a re the main data sour ce of react ive strategies. The information requir ed to ob- tain session information are user ’s IP address, a ccess date and time, and the URL of the page a ccessed. These thr ee attributes are in clude d in common 2 log format 1 . Ther e are several p revious works r ela ted to mining web access patterns [ 8 , 11 , 17 , 25 ]. W e use modified apriori technique adapted for sequence di s- covery for discovering frequent access paths. This idea is not new [ 3 , 11 , 17 ], however , to the best of our knowledge, the use of web topology for extend- ing the larg e itemsets throug h iterations of the apriori technique is novel. In this paper , not only we show that the discovery of fr e q uent ma ximal navigation p a tterns from already reco nstruc ted patterns utilizing the web topology can be done very easily , but we also show that the accuracy of the discovered frequent patterns is much higher than the accuracy of the r econstr ucted sessions. Therefor e, it is worthwhile to make extra e ff ort to incr e ase the accuracy of the reconstr ucted sessions. The main aim of our work is to discover frequent user session patterns. The r esults of this work can be used in ap p lications such as web pre-fetching. The pr oblem of which page will be requested fr om the current page can be solved by applying some statistical methods to frequent pattern se t gener - ated by our method. In a d d ition to web perfecting, link topology can be modified by examining frequent patterns. Reaching popular pages in fr e- quent patterns can be made easier by changing link topolo gy . Length of the most frequent navigation pa ths can be decreased by anal yzing frequent patterns discover ed by our method. B y changing the link topolog y , web users’ se a rches for tar get pages becomes ea sier . This p a per is or ganize d as follows. The next section is dedicated to ses- sion r econstr uction operation. It first summarizes previou sly used reactive heuristics, and a recently pr oposed heuristics. After that, it intr oduces the agent simulator that was used to e valuate di ff erent session reconst ruct ion heuristics, a nd finally it experimentally evaluates the accuracy of the first phase. Section 3 discusses pattern discovery fro m the reconst ruct ed ses- sions, firstly by intr oducing a modified apriori technique used for p a ttern discovery , and then it analyzes the performance of pattern discovery phase. Finally , we give our conclusions. 1 http: // www .w3.org / Daemon / User / Config / L o gging.html#common-logfile- format 3 2 Session Reconstruction 2.1 Previous Heuristics Pr evious Reactive session r econstruction heuristics [ 23 ] use page access timestamps and navigation information of the users. T ime oriented heuris- tics [ 7 , 22 ] are based on time limitations on total session time or page-stay time. In the first type, total time of the session can not be greater than pr edefined thr eshold. In the se cond type, predefined threshold is used for checking page-stay time. T ime oriented heuristics lack path information since they do not consider page connectivity . Navigation-oriented approach [ 7 , 8 ] takes web topology in graph format. I t considers webpage connectivity , however , it is not nece ssary to ha ve hyper- link be tween two consecutiv e pages. In case of any missing link, backwar d br owser movements are inserted if one of the previously accessed pages r efers to new page. In navigation-oriented heuristics artificially inserted links with backward browser movements is a major problem, since although the rest of the session always corr esponds to forwar d movements in we b topology graph. It is di ffi cult to interpret these pa tterns. Seq ue ntial pa ges accessed from server side can not be extracted. I n addition, extra backward movements makes sessions longer . A lso there is no time limitation, for a client which has access set in very di ff erent time. The length of the session becomes very long. 2.2 Smart-SRA Smart-SRA [ 5 , 4 ] is new method proposed by us for solving deficiencies of time and na vigation oriented heuristics. Smart-SRA produces sessions containing sequential pages accessed fro m server-side satisfying following rules: T imestamp Ordering Rule: • ∀ i : 1 ≤ i < n, T imestamp( P i ) < T imestamp( P i+1 ) • ∀ i : 1 ≤ i < n, T imestamp( P i+1 ) − T ime stamp( P i ) ≤ ρ (pa ge stay time) • T imestamp( P n ) - T imestamp( P 1 ) < δ (session duration time). T opology Rule: • ∀ i : 1 ≤ i < n, there is a hyperlink from P i to P i+1 4 P 13 P 1 P 20 P 23 P 49 P 34 Fig. 1. An example web s ite t opology gr aph Smart-SRA uses pa ge-stay a nd session duration rules of time-oriented heuris- tics. It uses topology rule as in navigation-oriented heuristics. It can be accepted as improved version of combined time and navigation oriented heuristics since it performs path completion and separation more intelli- gently . Smart-SRA composed of two phases. In the first phase of Smart- SRA, time criteria (page-stay and session duration) are applied for gen- erating shorter sequence s from raw input. I n the second phase, maximal sub-sessions are generated from seque nces generated in the first phase in a way that e ach consecutive page satisfies topology rule. Session duration time is a lso guaranteed by the first phase. However , page stay time should be contr olled since consecutive web pa ge pair generated in the first phase can be changed in second phase from the set of pa ges satisfying session duration time. In the first pha se of Smart-SRA, time criteria (pa ge-stay and session dura- tion) are a p p lie d for generating shorter sequences from raw input. In the second phase, maximal sub-sessions are generated fro m sequences gener- ated in the first phase in a way that each consecutive page satisfies topology rule. Session duration time is a l so guaranteed by the first phase. However , page stay time should be contr olled since consecutive web pa ge pair gener- ated in the first phase can be changed in second p ha se from the set of pages satisfying session duration time. The second phase adds r eferrer constraints of the topology rule by elimi- nating the ne ed for inserting backward browser moves. This is achieved by r epeating the following steps until all pages in a candidate session obtained after the first phase have been pro cessed: (1) The web pages without any r e ferr e rs a re determined in the candidate session fr om the web topolog y . (2) These pages ar e removed fr om the candidate session. (3) They ar e appended to the previously construct ed sessions, if there is a hyperlink fr om the last pa ge of a session to new we b pages. 5 Considering the web topology given in Figur e 1, for the candidate session [ P 1 , P 20 , P 23 , P 13 , P 34 ] obtained after the first phase, Smart-SRA discovers the sessions [ P 1 , P 20 , P 23 ] and [ P 1 , P 13 , P 34 ]. 2.3 Agent Simulator It is not possible to use we b server supplied real user navigation da ta for evaluating and comparing di ff erent web user se ssion reconstr uction heuris- tics since all of the actual user requests cannot be captured by p rocessing server side access logs. Especially the sessions containing access requests served from a client’s and / or proxy ’s local cache cannot be known or pre- dicted by a web server . Therefor e, we ha ve developed an a gent simulator that generates we b agent requests by simulating an actual web user [ 5 , 4 ]. Our agent simulator first randomly generates a typical web site topolog y and then simulates a user agent that accesses this domain fr om its client site and navigates (randomly) in this domain like a real user . In this way , we will have full knowledge about the sessions beforehand, and later when we use a heuristic to process user access log data to discover the sessions, we can evaluate how successful that heuristic was in reconstr ucting the known sessions. While generating a session, our agent simulator e liminates web user navigations provided via a client’s local cache. Since the simulator knows the full na vigation history at the client side, it can determine naviga- tion requests that are served by the we b server , a nd those are served from the client / proxy cache. Also, our agent simulator knows which page is the actual referr er (a p age with a hyperlink to the accessed page, and this new page is a ccessed by following this link) of any page r eq uested fr om se rver . Agent simulator pro duces an access log file at server side containing page r equests whose pages are provided by the web server . The sessions discov- ered by a he uristics ar e compar ed with the original complete session file. For example, consider an agent with complete page sequence s of [ P 1 , P 20 , P 23 ] and [ P 1 , P 13 , P 34 ] generated by the agent simulator , which corr espond to the real sessions. However , in the web server log, this sequence may appear as [ P 1 , P 20 , P 23 , P 13 , P 34 ], since the brow ser of the client can provide the movement from P 23 to P 13 thr ough P 1 using its local cache, which means the second request for page P 1 will not be sent to the web server . In this example, our agent simulator generates an agent acting as a web user who r equests pages P 1 , P 20 , P 23 consecutively , and then, returns backwar d to P 1 , and requests page P 13 . Therefor e, our agent simulator knows that the actual r eferr er of P 13 is P 1 . Finally , user agent requests page P 34 fr om pa ge P 13 , and thus, the agent simulator generates a session [ P 1 , P 13 , P 34 ]. Heuristics used to reconstr uct user sessions are run on the server side log data, and 6 they construct candidate session sequences. These candidate sequences are compar e d to the real session sequences in or der to determine the accuracy of the heuristics. An important fea tur e of our agent simulator is its ability to m odel dynamic behaviors of a web a gent. It simulates four basic behaviors of a web user . These behaviors can be used to construc t mor e complex navigation behav- iors in a single session. These four basic be haviors constr ucting complex navigations a r e given below: (1) A W eb user can start session with any one of the possible entry pages of a web site. This behavior includes ne w page which is not r e quested by any other p revious page accessed from the same domain in near-t ime (2) A W eb user can select the next page having a link from the most recently accessed page. (3) A W eb user can press the back button one mor e time and thus selects as the next page a page having a link fr om any one of the previously br owsed pages (i.e., p a ges accessed before the most recently accessed one). (4) A W eb user can terminate his / her session. Agent simulator also uses time considerations while simulating the behav- iors described above. In the second and the third behaviors, the time dif- fer ence between two consecutive page requests is smaller than 1 0 minutes. Also, in these behaviors, time di ff erences of access time of the ne xt page and the curr ent pa ge will have a normal distribution. In addition, the median value for a page stay time is taken as 2.12 minutes (from [ 23 ]), and the stan- dard deviation is taken as 0.5 minutes. The generated time di ff erences set for each type of these behaviors constitute a normal distribution. Four primitive basic behaviors given above are implemented in our agent simulator . Also, the following parameters a re used for simulating navigation behavior of a web user . Session T e rmination Probability (STP): STP is incr eased as the length of a user session incr e ases. The probability of terminating a session at the n th r equest is defined as (1 − (1 − STP ) n ). Link fr om Previous pages Probability (LPP): LPP is the pr obability of r eferring next page from one of the previously accessed pages except the most recently accessed one. This parameter is used to allow the generation of backwar d movements from br owser . New Initial page Probability (NIP): NIP repr esents the pro bability of se- lecting one of the starting pages of a web site during the navigation, thus starting a new session. 7 2.4 Performance Evaluation of Session Reconstruction Phase The most important performance criterion of the session r e constr uction heuristics is the accuracy of the construc ted sessions. A gent simulator can be used to me a sur e the accuracy of the session reco nstruct ion p ha se. W e can simply define the accuracy of a heuristic is as the ratio of correct ly r econstr ucted sessions over the number of r eal sessions generated by the agent simulator . A reconstr ucted session is corr e ct if it captur es a real session. W e assume that a session H, reconstr ucted by a heuristic, captur es a real session R, if R occurs as a subsequence of H. A session P with le ngth n is a sub-session of a session S with length m (denoted as P ⊏ S ) if there i s an ind ex k of S, such that, 1 = k = m a nd k + n-1 = m, that satisfies the following: S k = P 1 , S k+1 = P 2 , S k+2 = P 3 . . . S k+n-1 = P n For example, if R = [ P 1 , P 3 , P 5 ] and H = [ P 9 , P 1 , P 3 , P 5 , P 8 ], then, R ⊏ H since P 1 , P 3 and P 5 ar e elements of H and they are all in the same order . On the other ha nd , if H = [ P 1 , P 9 , P 3 , P 5 , P 8 ], then, R a H , because P 9 interrupt s R in H. Sear ching real sessions in candid ate sessions produced by heuristics can be done by using a simple algorithm adopted fr om an ordinary string sear ching algorithm. Our agent simulator first generates a web domain, and then it produces sim- ulated sessions and a corr esponding web log file containing client r equests for web pages. Then, a reconst ructio n he uristic processes this log file and generates candidate sessions. A fter that, the accuracy of the heuristics can be determined by using the reconst ructed sessions and original simulated sessions. As me ntioned above, the accuracy of session r e constr uction heuristics can be calculated with respect to 3 parameters, namely STP , LPP , and NIP . For evaluating the accuracy performance of di ff erent heuristics, random web sites and web agent navigations are generated by using the parameters given in T able 1. The number of web pages in a web site a nd the average number of out degr e es of the pages (number of links fro m one page to other pages in the same site) are taken fro m 2 . V arying values of the thr ee parameters defined in the previous section, namely STP , LPP , and NIP , ar e used for comparing the performances of the heuristics. In our experiments, we have fixed two of these parameters an d obtained 2 http: // www .sims.be rkeley .edu / resear ch / projects / how-much- info / internet / rawdata.html 8 T able 1 Agent Simulators parameters Parameter Range A verage N umber o f web p ages (node s) in t opology 300 A verage number of o utdegree 15 A verage number of page stay time 2 . 2min Deviation for page stay time 0 . 5min Number of agen t s 10000 Session T ermination Probabil ity (STP) Fixed: 5%, V arying:[1%,20%] Link F rom Previous Page probabili ty (LPP) Fixed: 30%, V arying:[0%,90%] New Initial Page p roba bility (NIP) Fixed: 30%, V arying:[0%,90%] performance r esults for the thir d parameter . Therefor e, three sets of exper- iments are performed. In the first experiment, LPP and NIP a r e fixed as 30%, and STP is varying from 1% to 20%. In the second e xperiment, LPP is varying fro m 1% to 90% and STP is fixed as 5% and NIP is fixed as 30% . Similarly , in the third e xperiment, NIP is varying and STP and LPP are fixed as 5% and 30% respectively . In the first experiment, increase in STP leads to sessions with fewer pa ges. The accuracy is higher for shorter sessions. If the navigation is a ff ected by LPP and NIP , then, the session becomes more complex. If there is no ret urn back to a n alr eady visited page and there is no new initial page, then, the session becomes simple and it can e a sily be captur e d . So, incr e a sing NIP and LPP decreases the accuracy performance in contrast to STP . The accuracies of 4 heuristics (limited total session time: TO1, limited page stay time: TO2, navigation oriented: NO and Smart-SRA: SSRA) for various p a rameters are given in Figur es 2, 3 and 4. A s it can be seen from these figures Smart-SRA outperforms other pr e vious he uristics (see [ 5 , 4 ] for more details). 3 Discovering Patterns 3.1 Sequential Apriori T echnique A modified version of the classical apriori [ 2 ] technique was used for dis- covering the frequent user access pa tterns fro m the r econstru cted maximal sessions. Unlike the or dinary la r ge itemset discovery pro blem, in the user web access pattern d i scovery problem, consecutive pages in the discover ed pattern should also appear in consecutive positions in the r econstr ucted ses- 9 Accuracy vs STP 0 5 10 15 20 25 30 35 40 45 50 1 3 5 7 9 11 13 15 17 19 STP Accuracy % TO1 TO2 NO SSRA Fig. 2. Reconstructed sess ion accuracy for varying STP Accuracy vs LPP 0 5 10 15 20 25 30 35 40 45 50 0 10 20 30 40 50 60 70 80 9 0 LPP Accuracy % TO1 TO2 NO SSRA Fig. 3. Reconstructed s e ssion accuracy for varying LPP 10 Accuracy vs NIP 0 5 10 15 20 25 30 35 0 10 20 30 40 50 60 70 80 90 NIP Accuracy % TO1 TO2 NO SSRA Fig. 4. Reconstructed se ssion accuracy for varying N IP 11 sions supporting the p a ttern. Therefor e, fr e q uent web access patterns can be obtained fr om reconstr ucted sessions by using a more e ffi cient and sim- plified version of apriori technique. A session S supports a pattern P if and only if P is a subsequence of S ( P ⊏ S ). W e call all the sessions supporting a pattern as its support set. That is, a r econstr ucted session S ∈ SupportSet(P) if P ⊏ S . Sequential AprioriAll Algorithm (Algorithm 3): In the beginning, each page with su ffi cient support forms a length-1 supported pattern. Then, in the main step, for e ach k value gr eater than 1 and up to the maximum r econstr ucted session length, supported patterns (patterns satisfying the support condition) with length k + 1 ar e constr ucted by using the supported patterns with length k and length 1 as follows: • If the last pa ge of the length-k pattern has a link to the page of the le ngth- 1 pattern, then by appending that pa ge length-k + 1 candidate pattern is generated. • If the support of the length-k + 1 pattern is greater than the requir ed sup- port, it becomes a support ed pattern. In a ddition, the new length-k + 1 pattern becomes ma ximal, and the extended length-k pattern and the appended length-1 pa ttern become non-maximal. • If the length-k pattern obtained from the new length-(k + 1) pattern by dr opping its first ele me nt was marked as maximal in the previous itera- tion, it also becomes non-maximal. • At some k value, if no new supported pattern is constructed, the iteration halts. Notice that in the sequen tial apriori algorithm, the patterns with length-k ar e joined with the patterns with length-1 by considering the topology rule. This step significantly eliminates many unnecessary candidate patterns be- for e even calculating their supports, and thus i ncreases the performance drastically . I n addition, since the definition of the support automatically contr ols the timestamp or dering rule with the sub-session check, all discov- ered patterns will satisfy both the topolog y and the timestamp rules, which ar e very important in web usage mining. An auxiliary function Support (I:Pattern,S) determines whether a given pat- tern has su ffi cient support fr om the given set of reconstr ucted user sessions. Support of a pattern I is de fined as a ratio between the numbers of r econ- stru cted sessions supporting the pattern I, the number of all sessions. Support ( I , S ) = |{ S i |∀ i and I i s substrin g o f S i }| | S | (1) 12 Algorithm 1 Sequential A priori 1: input: Minimum support fr equency: δ 2: Reconstru cted sessions: S 3: T opology information as matrix: Link 4: The Set of W eb Pages: P 5: output: Set of maximal frequent patterns: Max 6: procedure sequentialApriori ( δ , S, Link, P) 7: L 1 : = {} { Set of frequent length-1 patterns } 8: for i: = 1 to | P | do 9: L 1 : = L 1 U { [ P i ] | if Support([ P i ],S) > δ } 10: for k = 1 to N-1 do 11: if L k = then 12: Halt 13: else 14: L k+1 : = {} 15: for each I i ∈ L k 16: for each P j ∈ P 17: if Link[LastPage( I i ), P j ] = tr ue then 18: T : = I i • P j // Append P j to I i 19: if Support(T ,S) > the n 20: T .maximal : = TRU E 21: I i .maximal : = F ALSE / / since extended 22: V : = [ T 2 , T 3 ,. . . , T | T | ] { dr op first element } 23: if V ∈ L k then 24: V .maximal : = F A LSE 25: L k+1 : = L k+1 U { T } 26: end if 27: end if 28: end if 29: end for each 30: end for each 31: end if 32: end for 33: Max : = {} 34: for k : = 1 to N -1 do 35: Max : = Max U { S | S ∈ L k and S.maximal = true } 36: end for 37: end procedure 13 T able 2 Reconstructed Ses sions Database Session Id Session 1 [ P 1 , P 13 , P 49 , P 23 ] 2 [ P 1 , P 13 , P 34 , P 23 ] 3 [ P 1 , P 13 , P 49 ] 4 [ P 1 , P 20 , P 23 ] 5 [ P 13 , P 49 ] T able 3 Patterns Gen e rated at e ach I teration Step Patterns Frequencies 1 { [ P 1 ] , [ P 13 ] , [ P 23 ] , { 0.80, 0.80, 0.60, 0.60 } [ P 49 ] } ≥ 0 . 40 { [ P 20 ] , [ P 34 ] } { 0.20, 0.20 } < 0.40 2 { [ P 1 , P 13 ] , [ P 13 , P 49 ] } { 0.60, 0.60 } ≥ 0 . 40 { [ P 49 , P 23 ] } { 0.20 } < 0.40 3 { [ P 1 , P 13 , P 49 ] } { 0.40 } ≥ 0 . 40 { [ P 13 , P 49 , P 23 ] } { 0.20 } < 0.40 Let the list of sessions in T able 2 be generated by some session r econstru ction heuristic from the server logs. Let δ = 0 . 4 0 be taken as minimum support for the Sequential A priori algorithm. The n, the execution of the sequential apriori technique will gene rate patterns with their frequencies in thr ee it- erations as it is shown in T able 3. I n this table, the patterns shown in gray ar eas are eliminated due to their insu ffi cient support. Since at iteration 4, ther e are no remaining fr equent patterns, the algorithm stops. The maximal fr equent patterns a r e shown in bold in T able 3 . The only maximal pattern is [ P 1 , P 13 , P 49 ] with support 0. 4 0. 3.2 Performance of Sequential Apriori T echnique In this subsection, we experimentally de termine the a ccuracies of the max- imal frequent patterns generated by the sequential apriori technique using the sessions reconstr ucted by di ff erent session reco nstruc tion heuristics. Af- ter the reconst ructio n of the se ssions, they are processed by the sequential apriori algorithm in order to discover the fr equent patterns in these ses- sions. Sequential apriori technique is also applied to the actual sequences generated by the agent simulator . Since, we know the fr e q uent ma ximal 14 T able 4 Parameters Used for Modeling W eb Use rs Experiment No STP LPP N IP 1 0.10 0.20 0.20 2 0.10 0.20 0.40 3 0.10 0.40 0.20 4 0.10 0.40 0.40 5 0.20 0.20 0.20 6 0.20 0.20 0.40 7 0.20 0.40 0.20 8 0.20 0.40 0.40 patterns of the sequences of the agent simulator ( MP A ), which correspo nd to the corr ect frequent patterns, we can de termine the accuracies of di ff erent heuristics ( A H stands for the accuracy of a heuristic H) by using the maximal fr equent patterns generated by these heuristics ( MP H ) as follows: A H = | MP A ∩ MP H | | MP A | (2) In our experiments, we have studied the accuracy by varying 4 di ff erent parameters, namely STP , LPP , NIP and the support. I n e a ch experiment we have fixed the thr e e parameters (STP , LPP , and N IP) which are used to define the behavior of an agent, and obtained the accuracies for varying support values. For e ach one of these parameters, we have used two typical values, namely 0.10 and 0 . 2 0 for STP and 0. 2 0 and 0.40 for L PP and NIP . Also, in e ach experiment the support is defined from 0.05% to 0.2 5%. T able 5 summarizes the parameters used in these experiments. A mong these parameters the 4th experiment gave the lowest and the 5th experiment gave the highest accuracy r e sults for all heuristics and support values. The important result of these experiments is the large improvement of the accuracies of the frequent pattern sessions in the second phase. As it can be seen fro m Figures 5 and 6, corr esponding to the 4 th and the 5 th experiments, r espectively , the accuracy of the second phase is always much higher than the accuracy of the r e constr ucted sessions. I t is also observed that the ac- curacy of discover ed fr equent maximal patterns is about 30% higher when Smart-SRA is used. Similar r esults we re also obtained for other 6 experi- ments. This result is not surprising because in the first phase real sessions must 15 Support vs Accurac y 0 10 20 30 40 50 60 70 80 90 100 0.0005 0.0010 0.0015 0.0020 0.0025 Support Accuracy Percenta ge (%) TO1 TO2 NO SSRA Fig. 5. Support vs. Accuracy (Experiment no 4) Support vs Accurac y 0 10 20 30 40 50 60 70 80 90 100 0.0005 0.0010 0.0015 0.0020 0.0025 Support Accuracy Percenta ge (%) TO1 TO2 NO SSRA Fig. 6. Support vs. Accuracy (Experiment no 5) 16 appear as sub-sessions of reconstr ucted sessions in or de r to be considered as corr ect, but, on the other h a n d , in the second phase, only frequent real patterns must appear as sub-sessions of frequent reconst ructed sessions in or de r to be considered as correct . Thus, it is more likely to obtain higher accuracy in the second phase. In the session reco nstruct ion phase, for 1 00% accuracy of any pattern, it must appea r in the reconstr ucted sessions for each of its occurr ence in the actual sessions. On the other hand , for frequent pattern discovery phase, it is su ffi cient if the pattern appears as ma ny times as it is requir ed by the support value. The r efor e, for fr equent patterns we obtain much higher accuracies. 4 Conclusion and Future W ork In this paper we have intr oduced a new frequent web usage pattern dis- covery method. Frequent patterns are discover ed among the reconstr ucted sessions. Sessions can be recons truct ed by using various heuristics. In our experiments we have used a recently developed heuristic Smart-SRA and time and navigation oriented heuristics for this first phase. The n, we have used a newly proposed sequential apriori technique in order to discover fr equent patterns in the set of reconst ructed sessions. In the session reconst ructio n phase, for a reconstr ucted session to be as- sumed as accurate, it must include a session generated by the agent simula- tor . A fr equent p a ttern is accepted as accurate if it app e ars only as a frequent pattern in the reconstr ucted sessions. Therefor e, the accuracy increases after the pattern discovery phase, since complex navigational behaviors, which ar e hard to discover , but also infrequent are eliminated at this p ha se. The main purpose of W UM is to extract useful user navigation patterns. Ther efor e, it is not su ffi cient only to reconstr uct user sessions from server logs. Ca pturing fr equent user navigation patterns is more significant. This is achieved by employing frequent pa ttern discovery techniques after ses- sions are reconstr ucted. It is important to observe that the success of session r econstr uction phase of WUM a ff ects the success of the fr equent pattern discovery phase. Moreover , our experiments also show that r egardless of which heuristic is used for session r econstru ction, in frequent pattern dis- covery phase the accuracy always increases. Also, by adjusting the support parameter of the apriori technique it is possible to control the frequency r equirement of the common patterns searched in user navigation behaviors as well as the number of patterns discover ed. As a future work, modifying SRA heuristic for pro active session r econstr uc- tion can be consider ed by using other additional information sour ces. Also, 17 our agent simulator can be imp r oved in order to repr esent user navigation behaviors mor e correctly by adding ne w featur es. References [1] Y . M. A. Nanopoulos, D. Katsaros. E ff ective p rediction of w eb-user accesse s: A data mining approach. In W EBKDD , 2001. [2] R. Agrawal and R. Srikant. Fast algorithms for mining association rules in lar g e databases. In VLDB , pages 487–499, 1994 . [3] R. Agrawal and R. Srikant. Mining seque ntial patterns . In ICD E , pages 3–14 , 1995. [4] M. A. Bayir . A new reactive metho d for processing web usage d ata. Master ’s thesis, Middle East T echnical U n ivers ity , 2006. [5] M. A. B ayir , I. H. T oroslu, and A. Cos ar . A new app roach for reactive web usage data processing. In ICD E W orkshop s , page 44, 2006. [6] R. Coo ley , B. Mobasher , and J. Srivastava. W eb mining: Information and pattern discovery on the world wide web. In IC T AI , pages 558–567, 1997. [7] R. Coo ley , B . Mobasher , and J. Srivastava. Data preparation for mining wor ld wide web browsing patte rns. K nowl. Inf. Syst. , 1(1):5–32, 1999. [8] R. Cooley , P .-N. T an, and J. Srivastava. Discovery of interesting us age p atterns fr om we b data. In WEBKDD , page s 163–182, 1999. [9] E. Frias-Martinez and V . Karamcheti. A customizable behavior model for temporal prediction of web us e r seque nces. In W EBKDD , page s 66–85, 2002. [10] Y . Fu and M.-Y . Shih. A framework for pers onal web u sage mining. In International Confer ence on Internet Computing , page s 595–600 , 2002. [11] W . Gaul and L. Schmidt-Thieme. Mining we b navigation path fragments . In In Proce edings of the Works hop on W eb Mining for E-Commer ce , 2000. [12] S . G ¨ und ¨ uz and M. T . ¨ Ozsu. A web page prediction model based on click-stream tree repr esent ation of u s er behavior . In KDD , pages 535–540, 2003. [13] P . P . J. E . Pitkow . Mining longe st repeating subs equences to predict world w ide web surfing. In USE NIX , 1999. [14] B . Mobasher , R. Cooley , and J. Srivastava. A utomatic perso n alization based on web usage mining. Commun . ACM , 43(8):142– 151, 2000. [15] B . Mobasher , H . Dai, T . Luo, and M. N akagawa. Discovery and evaluation of aggregate usage profiles for web personalization. Data Min. Knowl. Discov . , 6(1):61 –82, 2002. 18 [16] O. Nasraoui and R. Krishnapuram. An evolutionary approach to mining robust multi-r esolution web pr o files and context sensitive url associations. International Journal of Computational Intellige nce and Applications , 2(3):339 –348, 2002. [17] J. Pei, J. Han, B. Mortazavi-Asl, and H. Zhu . Mining access patte rns e ffi ciently fr om we b logs . pages 396–407, 2000. [18] D. Pierrakos, G. Paliouras, C. Papatheodo rou, and C. D. S pyropoulos. W eb usage mining as a too l for personalization: A survey . User Model. U ser-Adap t. Interact. , 13(4):311 –372, 2003. [19] S . E. Schechte r , M. Krishnan, and M. D. Smith. U sing path profiles to predict http requests. Computer N etworks , 30(1-7 ):457–4 67, 1998. [20] C. Shahabi and F . B . Kashani. E ffi cient and anon y mous web-us age mining for web pers o nalizati on. INFOR MS Journal on Computing , 15(2):123– 147, 2003. [21] M. Spiliopoulou. W eb usage mining for w eb site evaluation. Commun . A CM , 43(8):1 27–134 , 2000. [22] M. Spiliopoulou and L . Faulst ich. W um - a to ol for www ulitiza tion analysis. In WebDB , pages 184–103 , 1998. [23] M. Spiliopoulou, B. Mo bashe r , B. Berendt, and M. Nakagawa. A framework for the evaluation of sess ion reconstruction heurist ics in we b-usage analysis. INFORMS Journal on Computing , 15(2):17 1–190, 2003. [24] R . Srikant and Y . Y ang. Mining web logs to improve we bsite organization. In WWW , pages 430–437 , 2001. [25] J. Srivastava, R. Cooley , M. Deshpande , and P .-N. T an. W eb usage mining: Discovery and applications of usage patte rns fr om web data. SIGKDD Explorat ions , 1(2):12 –23, 2000. 19
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment