Unified storage systems for distributed Tier-2 centres
The start of data taking at the Large Hadron Collider will herald a new era in data volumes and distributed processing in particle physics. Data volumes of hundreds of Terabytes will be shipped to Tier-2 centres for analysis by the LHC experiments us…
Authors: Greig A. Cowan, Graeme A. Stewart, Andrew Elwell
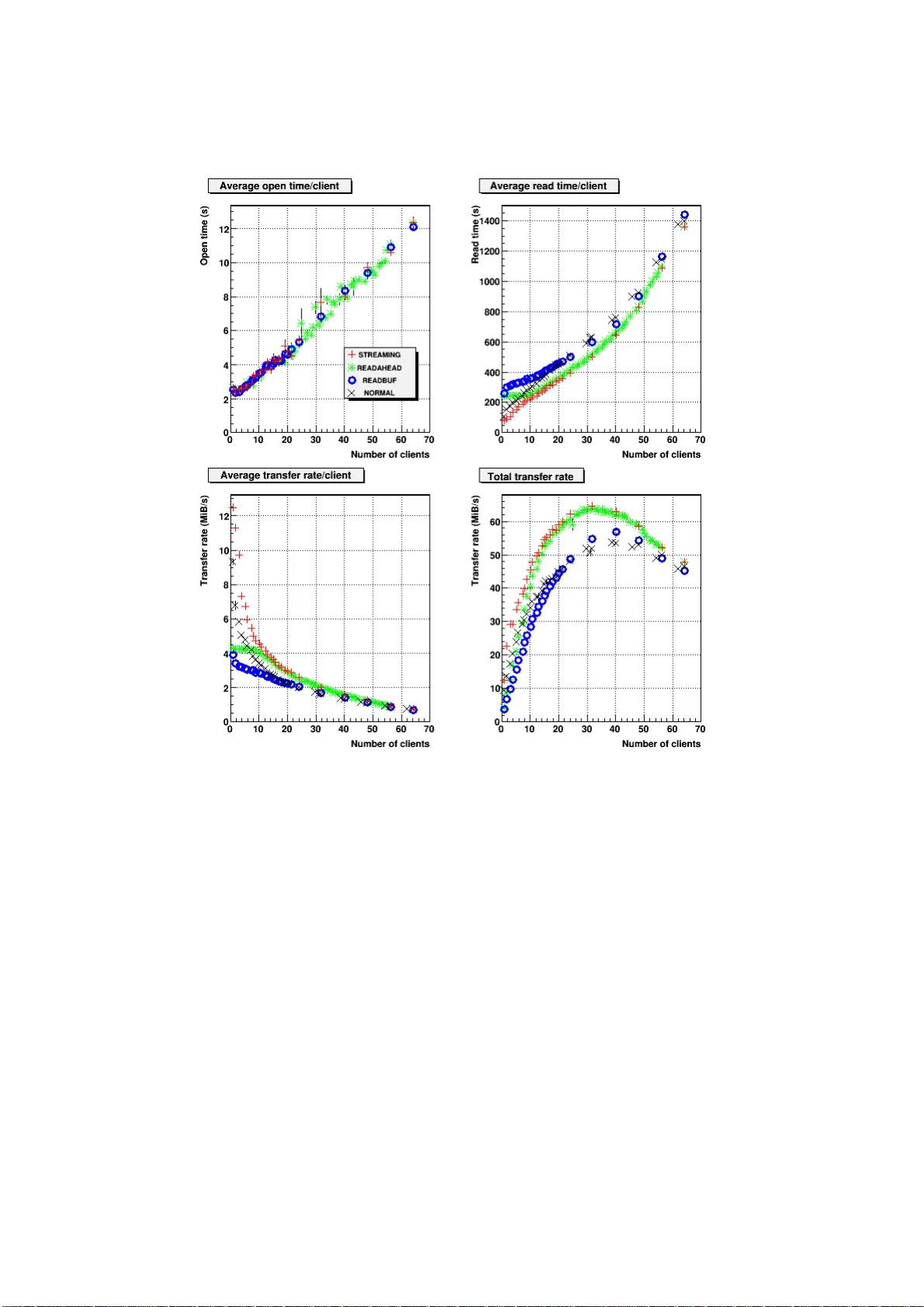
Unified storage s ystems for d istribut ed Tier-2 ce ntres G A Co w an 1 , G A Stewart 2 and A Elwell 2 1 Department of Physics , Universit y of Edinburgh, Edinburgh, UK 2 Department of Physics , Universit y of Glasgo w, Glasgo w, UK E-mail: g.cowan@ed. ac.uk Abstract. The start of data taking at th e Large Hadron Collider will herald a n ew era in data vol umes and d istributed processing in particle physics. Data volumes of hundreds of T erab ytes will b e shipp ed to Tier-2 centres for analysis by the LHC exp eriments u sing the W orldwide LHC Computing Grid (WLCG). In many coun tries Tier-2 centres are distributed b etw een a n umber of institutes, e.g., the geographically spread Tier-2s of GridPP in the UK . This presents a n umber of c hallenges for exp eriments to u tilise these centres efficaciously , as CPU and storage resources ma y b e sub- divided and exp osed in smaller units th an t h e exp eriment w ould ideally w ant to w ork with. In addition, unhelpful mismatc hes b etw een storage and CPU at the ind ividual cen tres may b e seen, which make efficient exploitation of a Tier-2’s resources difficult. One meth od of addressing this is to un ify the storage across a distributed Tier-2, presenting the centres’ aggregated storage as a single system. This greatly simplifies data management for the VO, whic h then can access a grea ter amoun t of d ata across the Tier-2. How ev er, suc h an approac h will lead t o scenarios where analysis jobs on one site’s batch system must access data hosted on another site. W e inv estigate this situation using th e Glasgo w and Edinburgh clusters, which are part of th e ScotGrid d istributed Tier-2. In particular we lo ok at ho w to mitigate the problems associated with “d istant” d ata access and d iscuss the security implications of h aving LAN access protocols tra verse the W AN betw een cen tres. 1. In tro duction One of the ke y concepts b ehind Grid computing is th e transparent use of distr ib uted compute and storage resources. Users of the Grid should not need to kno w where their d ata resides, nor where it is p ro cessed and analysed. When the Large Hadron Collider at CERN b egins to run at luminosities sufficien t for ph ysics studies, it will pro duce aroun d 15 petabytes of data a y ear. In ord er to analyse such a large quan tit y of information, the W o rldwide LHC Computing Grid (WLCG) has b een created. This is an in ternational collab oration of ph ysics lab oratories and institutes, sp read across three m a jor grids (EGEE, OSG and Nordugrid). The UK’s Grid for particle p h ysics (GridPP ) [1] started in 2001 with the aim of creating a computing grid that would meet the needs of particle physici sts wo rking on th e next generation of particle physic s exp eriments, suc h as th e LHC. T o meet this aim, participating institutions w ere organised in to a set of Tier-2 cen tres according to th eir geographical lo cation. ScotGrid [2] is one su c h d istributed T ier-2 computing cent re formed as a collab oration b et w een th e Univ ersities of Du rham, Ed in burgh and Glasgo w. T o the Grid, the three collaborating institutes app ear as individual sites. Currently , the close asso ciation b et w een them exists only at a managerial and tec hnical supp ort lev el. O ne of the aims of this p ap er is to stud y the p ossibilit y of ha ving eve n closer-coupling b et w een the sites of S cotGrid (or other collections of sites on the Grid) fr om the p oint of view of accessing storage resources fr om geographically distributed compu ting cen tres. Current estimates suggest that th e maxim um rate with whic h a physic s analysis job can read data is 2MB/s. W e w an t to in v estiga te if such a rate is p ossible using distributed storage when using pro d uction quali t y hardwa re that is current ly op erational on the WLCG grid. Ph ysics analysis code will use the POSIX-lik e LAN access proto cols to read data, whic h for DPM is the Remote File I/O p rotocol (RFIO). Data transp ort using GridFTP across the W AN access has b een consid ered previously [3]. The structur e of this pap er is as follo ws. Section 2 describ es the storage midd lew are tec hnology that w e use in this study . W e further motiv at e this work in Section 3 . Section 4 discu sses th e storage, compute and netw o rking h ardwa re that is employ ed to p erform the testing. Section 5 explains the r easoning b ehind our testing m etho dology . W e presen t and in terp ret th e resu lts of this testing in Section 6, presen t futur e w ork in 7 and conclude in Section 8. 2. Storage middleware The Disk P o ol Manager (DPM) [4] is a storage middlew are pr o duct created at C ERN as part of the EGEE [5] p r o j ect. It has b een dev elop ed as a ligh tw eigh t solution f or disk storage managemen t at Tier-2 institutes. A priori , there is no limitation on the amount of disk space that the DPM can handle. 2.1. Ar chite ctur e The DPM consists of the follo wing comp onent serv er s , • DPM ( dpm ): ke eps track of all requests for file access. • DPM name serv er ( dpnsd ): handles the n amespace for all files under the con trol of DPM. • DRPM RFIO ( rfiod ): hand les the transfers for the RFIO pr otocol (See section 2.2). • DPM GridFTP ( dpm- gsiftp ): handles data transfers requirin g u se of the GridFTP proto col (See Section 2.2). • Storage Resour ce Manager ( srmv 1 , srmv2 , srmv2.2 ): receiv es t he S RM requests, passing them on to the DPM server. The pr otocols listed ab o ve will b e describ ed in the S ection 2.2. Figure 1 shows how the comp onen ts can b e configur ed in an instance of DPM. T ypically at a Tier-2 the serv er daemons ( dpm , dpns , srm ) are sh ared on one D PM he adno de , with sep arate large disk servers actually storing and serving files, runn ing dpm-gsif tp and r fiod serv ers. 2.2. Pr oto c ols DPM currently uses t wo differen t proto cols for data transfer and one for storage man agement, • GridFTP: typica lly used f or wide area transfer of data fi les, e.g., mo vemen t of data from Tier-1 to Tier-2 s torage. • Remote File IO (RFIO): GSI-enabled [6] pr oto col which pr ovides P O SIX [7] file op er ations, p ermitting byte-lev el access to fi les. • Storage Resource Manager: Th is standard in terface is used on the WLCG grid to p ermit the different storage serve r and client implemen tations to interop erate. RFIO is the proto col that ph ysics analysis co de should use in order to r ead data stored within a DPM instance and is the proto col used to p erform the tests in this p ap er. Clien t ap p lications Figure 1. S ho w s one p ossible configuration of the DPM s er ver comp onents. can link aga inst the RFIO clien t library p ermits byte lev el access to files stored on a DPM. The library allo ws for four differen t mo des of op eration, • 0 : Normal read with one request to the serv er. • RFIO READBUF : an inte rnal buffer is allo cated in the clien t API, eac h call to th e serve r fills this buffer and the us er b uffer is filled from the in ternal buffer . T h ere is one serve r call p er buffer fill. • RFIO READAHEA D : RFIO READ BUF is forced on and an internal buffer is allocated in the clien t API, Then an in itial call is sent to th e serv er which pu shes d ata to the clien t u n til end of file is reac hed or an error o ccurs or a n ew request comes f rom the clien t. • RFIO STREAM (V3):This read mo de op ens 2 connections b et ween the clien t and server, one data so ck et and one con trol so c ke t. T his allo ws the o v erlap of d isk and netw ork op erations. Data is pushed on the data sock et un til EOF is r eac hed. T ransfer is in terrup ted by sending a pac k et on the con trol so c k et. 3. RFIO ov e r the W AN Current Grid middlew are is designed suc h that analysis jobs are sen t to the site wh er e the data resides. T he wo rk p resen ted in this pap er p resen ts an alternativ e use case where analysis jobs can use RFIO for access to data held on a DPM w h ic h is remote to th e lo cation analysis job is pro cessed. Th is is of int erest due to a num b er of reasons, • Data at a site may b e hea vily sub scrib ed b y u ser analysis jobs, leading to many jobs b eing queu ed while r emote computing resources remain under used . O n e solution (whic h is currentl y used in WLCG) is to replicate the data across m u ltiple s ites, putting it close to a v ariet y of compu ting centres. Another w ould b e to allo w access to the data at a site from remote centres, whic h w ould help to optimise the use of Grid resources. • The con tinued expans ion of national and international lo w latency optical fibre n et wo rks suggest that accessing data across the wide area netw ork could p ro vid e the dedicated bandwidth that ph ysics analysis jobs will require in a pro duction environmen t. • Simplification of V O data managemen t m o dels due to the fact that an y data is, in essence, a v ailable from any computing cent re. The A TLAS computing mo del already has the concept of a “cloud” of sites w h ic h s tore datasets. 3.1. Se c urity RFIO u s es the Grid Security In frastructure (GSI) mo del, meaning that clients using the pr oto col require X.509 Grid certificate signed b y a trusted C ertificate Authority . Th erefore, within the framew ork of x.509, RFIO can b e used ov er the wide area net w ork w ithout fear of data b eing compromised. Additional p orts m u st b e op ened in the site fir ew all to allo w access to clien ts u sing RFIO . They are listed b elo w. Data transf er will use the site defined RFIO p ort range. • 5001: for access to the RFIO serv er. • 5010: for namespace op erations via the DPNS serv er. • 5015: for access to the DPM serve r. 4. Hardware setup 4.1. DPM server Y AIM [8] w as used to install v1.6.5 of DPM on a d ual core disk serv er with 2GB of RAM. The serv er w as run n ing SL4.3 32bit with a 2.6.9- 42 ke rnel. VDT1.2 was used [9]. All DPM services w er e d eplo yed on the same s erv er. A s in gle disk p o ol w as p opulated with a 300GB fi lesystem. 4.2. Computing cluster T o facilita te the testing, w e had use of the UKI-SC OTGRID-GLASGO W WLCG grid site [2 ]. The computing cluster is comp osed of 140 d ual core, d ual CPU Opteron 282 p ro cessing no d es with 8GB of RAM eac h. Being a pr o duction site, the compu te cluster was t ypically pr o cessing user analysis and exp eriment al Mon te Carlo pro du ction jobs while ou r p erform ance studies w er e ongoing. How ev er, obs er v ation sho wed that jobs on the cluster were t ypically CPU b ound , p erforming little I/O. As our test jobs are just the opp osite (little CPU, I/O and n et work b ound) tests we re able to b e p erform ed wh ile the cluster was still in pr o duction. 1 4.3. Networking The clien ts and serv ers at UKI-S C OTGRID-GLASGO W and ScotGRID-Edin bu rgh are connected (via local campus routing) to the J ANET -UK p ro duction aca demic netw ork [10] using gigabit ethernet. Figure 3 shows the results of ru nning ip er f b et wee n the t wo sites. This sho w s that the maxim u m file transf er rate that w e could hop e to ac h ieve in ou r studies is appro ximately 900Mb/s (100MB/s). The roun d trip time for th is connection is 12ms. 5. Metho dology 5.1. Phase sp ac e of inter est Analysis jobs will read d ata in storage elemen ts, so we restrict our exploration to j obs wh ich read data from DPM. W e explore the effects of using different RFIO r eading mo des, setting differen t RFIO b u ffer sizes and clien t application b lo c k sizes. S ince we are s tu dying transfers across the W AN, w e also lo ok at th e effect of v arying TCP window sizes on the total d ata throughput. 5.2. RFIO client applic ation In ord er to exp lore the p arameter space outlined ab o ve, we devel op ed our o wn RFIO clien t application. W ritten in C, this application links against the RFIO clien t lib r ary for DPM ( libdpm ). Th e application w as designed suc h that it can simulat e differen t t yp es of file access patterns. In our case, w e w ere intereste d in using the client where it sequential ly r eads blo c ks of a file and also the case where it reads a blo c k, skip s ahead a d efi ned num b er of blo cks and then 1 In fact this is quite reasonable, as in mo dern multicore SMP systems analysis jobs will share no des with additional batc h jobs, whic h will typically b e CPU intensiv e. Figure 2. The hard w are setup used during the tests and the net work connection b et ween sites. Number of streams 0 10 20 30 40 50 60 Rate (Mb/s) 0 100 200 300 400 500 600 700 800 iperf results Gla to Ed Ed to Gla Figure 3. Left: The J ANET -UK net w ork pat h tak en b et wee n th e UKI-S COTGRID- GLASGO W and ScotGRID-Edin b urgh s ites used in the RFIO testing. Right: Ip erf w as used to test the net work b et w een the t w o sites. reads again. This access was used to simulat e the fi le access as used in physics co de as the job jumps to different parts of the fi le when scann ing for in teresting p hysics ev en ts. Imp ortan tly , the clien t could b e configured to us e one of the RFIO mo des describ ed in Section 2.2. W e did not u se S TREAM mo de wh en skipping through the file as th ere app ears to b e a problem with the p oin ter returned by the rf io seek m etho d such that it do es not r ep ort th e correct p osition in the file. 5.3. Sour c e data and client initialisation As, in general, one exp ects that eac h analysis job is un corr elated with the others, and so will b e reading d ifferen t d ata, 100 source data files of 1GiB size w ere seeded onto the DPM. Each clien t then read a sin gle un ique file. If this assumption were not v alid, and seve ral clien ts w ere reading the same d ata, then the disk serv er wo uld ha v e the opp ortunity to cac he data from the file in question, p ossibly resulting in faster reads. W e also choose to stress th e DPM server itself d u ring our testing scenario by starting eac h of the clien ts within 1s. This should b e considered a w ors t case scenario for the storage system, as in practice it is v ery un lik ely that jobs will requ est op ens in suc h close succession. Therefore, our testing s cenario is delib erately setup in order to stress the storage system and the net w ork. T his is essential in ord er to establish whether or not RFIO access across the W AN can meet the h ighly demanding data p r o cessing rates of LHC physic s analysis jobs . 6. Results 6.1. Client r esults The resu lts present ed b elo w sho w clien t d ata transf er rates, defined as BYTES READ /( Open Time + Read Time ). It should b e noted that theoretical netw ork band width m us t also include IP and TCP o verheads. 6.1.1. Complete file r e ads Figure 4 sho ws the results f or reading 1GiB files. After only t w o or three simultaneous clients, th e file op en time b egins to increase app ro ximately linearly with th e n um b er of clien ts, fr om ∼ 2s up to > 12s for 64 clien ts. Reading r ate is 4-12MiB/s for a single clien t, and rises rapid ly for small num b ers of clien ts, increasing up to 62MiB/s for 32 clien ts using the S TREAMING and READAH EAD mo des. These buffered mo des p erform b etter than READBUF as b oth aggressiv ely read data from the serv er . F or larger client num b ers the transfer rates b egin to tail off.This effect is caused by the disk server b ecoming I/O b ound when servin g d ata to so m an y clien ts at once, with the b ottlenec k of many head mo vemen ts on the d isk to jump b et ween the man y op en files. 6.1.2. Partial file r e ads Results for partial fi le reads are sho wn in Figure 5 . In this case eac h clien t reads 1MiB f r om the sour ce file, then skips 9MiB (sim ulating reading 10% of the even ts in, sa y , an A OD file). As exp ected the results for openin g files are v ery similar to Figure 4 – the rfio open() call is exactly same as the previous case. Read rates, as exp ected, for READBUF and READ AHEAD mo des are considerably low er than for complete reads, as the disk server has to skip large p ortions of th e fi le, rep ositioning the reading heads. Maxim um rates in this case are only 2MiB/s. In stark con trast the case when complete files are read, NORMAL mo de p erforms b etter than the bu ffer r eading m o des, particularly at small clien t n umber. In p articular, the total transfer rate for b et w een 11 and 18 clien ts is larger than the maximum r ate seen in Section 6.1.1. It is n ot clear w h y this rate is not sustained b ey ond 18 clien ts; further in vestig ation is r equired. T he adv antage of NORMAL mo de when skipping th rough the file can b e understo o d as the bu ffered m o des read data whic h is not needed by the clien t. This data is thus discarded, but has loaded b oth the disk server and the net work, redu cing p erformance. 6.1.3. RFIO IO BUFSIZE The v alue of the in ternal API buffer used by clien ts in th e default READBUF mo de is set b y the site admin istrator in /etc /shift.co nf , rather than by clien ts. Figure 6 sh o ws the r esults of the v ariation of the total transfer rate with IOBUFSIZE w hen using RE ADBUF mo de to read 10% of the file. F or partial file reads increasing the v alue of IOBUFSIZE clearly h urts the o verall rate considerably . This is caused b y the in ternal bu ffer Figure 4. C omplete sequentia l reading of 1GiB files stored in the DPM from the compute cluster, f or v arying r ead m o des and client num b er. The blo c k size was 1MiB. Err or bars are smaller than the p lotted sym b ols. b eing filled b efore the clien t actually requests data. In th e case of skip p ing th r ough a fi le the clien t in fact do es not require this d ata and so netw ork and I/O bandwidth has b een consumed needlessly . F or the case where the client application blo c k size is altered so as to matc h that of the IOBUFSIZE, th ere is essen tially no change in the total transfer rate as the IOBUFSIZE matc hes. This mak es sense as the clien t is requesting the same amount of data as is b eing filled in the RFIO bu ffer, meaning band width is not w asted. This study has shown that the v alue of RFIO IOBUFSIZE should b e left at its default setting of 128kB. In particular setting to o high a v alue will p enalise clien ts using the default READBUF mo de to make partial reads of a file. 6.1.4. TCP tuning Since w e are mo vin g d ata across the W AN, we decided to study the effect of T CP window sizes on the throu gh p ut of our tests. W e mo dified the / etc/sysco nt.conf settings on the client side in the follo wing w a y , Figure 5. Resu lts for partial (10%) r eading of 1GiB files stored in the DPM from the Glasgo w compute cluster for the different read mo des and v arying num b er of simultaneous clien ts. Th e blo c k s ize was 1MiB. The blac k lines sho w the R MS errors. net.ip v4.tcp rmem = 4096 $TCPVA LUE $TCPVAL UE net.co re.wme m defau lt = 104857 6 net.ip v4.tcp wmem = 4096 $TCPVA LUE $ TCPVAL UE net.co re.rme m max = $TCPVAL UE net.ip v4.tcp mem = 131072 1048576 $TCPVAL UE net.co re.wme m max = $TCPVA LUE net.co re.rme m defaul t = 104857 6 Where $ TCPVALUE ∈ (0 . 5 , 1 , 2 , 4 , 8 , 16 )MiB. s ysctl -p was executed after setting the w indo w sizes. Th e d efault v alue used in all other tests p resen ted here wa s 1MiB. Figure 7 sh o ws h ow the total transf er rate v aries with clien t num b er as we alter the TCP tuning parameters. In this case, we we re skipping though 10% of the file and setting the tuning to the same v alue as the clien t applicat ion b lo c k size and the RFIO bu ffer size. Different colours corresp ond to different TCP w in do w sizes in the range sp ecified ab o ve . It is clear that there is v ery little v ariation in the total observed rate as a fun ction of wind o w size. T his is to b e exp ected when such a large n u m b er of clien ts are simultaneo usly r eading as they eac h hav e only a s mall part of th e total bandw idth a v ailable to them. A small improv emen t is seen at small client n um b ers with a larger wind ow (the turquoise p oin ts). It is lik ely that additional improv emen ts in the transfer rate will only come after optimisatio ns hav e b een made in the client ap p lication. RFIO buffer size (B) 0 2000 4000 6000 8000 10000 3 10 × Transfer rate (MiB/s) 0 5 10 15 20 25 Total transfer rate READBUF, with RFIO IOBUFSIZE = block size READBUF Figure 6. Rea ding 1GB fi les stored in the DPM using RFIO READBUF mo de from 30 client no des. T rans fer rate is p lotted versus the RFIO IOBUFSIZ E. Blue circles sh o w the case for partial file reads with a b lo c k s ize of 1MB while read pluses sho w wh ole file reads with the blo c k size set equal to the RFIO IOBUFSIZE . Number of clients 0 10 20 30 40 50 60 70 Read time (s) 0 1 2 3 4 5 6 7 8 9 10 Average transfer rate/client Average transfer rate/client Figure 7. Read time and transfer rate as a fu n ction of clien t n um b er for different v alues of the TCP “tuning” usin g the NORMAL RFIO mo de wh en s kipping through th e files. In all cases here, the v alue of the TCP “tunin g” was set to the same v alue as the clien t application blo c k size and the RFIO buffer. Th e results are essential ly the same for all cases of the TCP tunin g. 6.2. Comp arison with LAN ac c ess Figure 8 shows a comparison of the total data rate as a fun ction of clien t num b er when r eading files sequentia lly from a single DPM disk server across the LAN and across the W AN. The LAN in this case is the lo cal net w ork of the UKI-SCOT GRID-GLASGOW site whic h consists of a Nortel 5510 sw itc h stac k with eac h cluster no de connecte d through a 1GiB ethernet connection. This limits the rate for eac h clien t to 1GiB, but more imp ortan tly limits the r ate p er-disk serve r to 1GiB. Comparab le h ardw are for the d isk serv ers wa s us ed in eac h case. Unsurp r isingly , the total trans fer rate across the ded icated LAN is larger than that across the W AN, where w e would exp ect a maxim um th r oughput of around 100MiB/ s (Fig ure 3) as we are in con tentio n for netw ork resour ces with other users. Ho we v er , w e sho w that it is r elativ ely simple to ac h iev e reasonable data rates in r elation to LAN access. It will b e in teresting to study what throughpu t can b e ac hiev ed across the W AN as the num b er of disk servers is increased. Number of clients 0 10 20 30 40 50 60 70 80 Transfer rate (MiB/s) 0 20 40 60 80 100 120 Total transfer rate STREAMING READAHEAD READBUF NORMAL Total transfer rate Number of clients 0 10 20 30 40 50 60 70 Transfer rate (MiB/s) 0 20 40 60 80 100 120 Total transfer rate STREAMING READAHEAD READBUF NORMAL Total transfer rate Figure 8. Left : Sho ws the total r ate when reading data sequenti ally from the lo cal Glasgo w DPM to clien ts on the cluster, across the LAN. Righ t: Shows th e equiv alen t data access when reading data from the Edinburgh DPM across the W AN (rep eated from Figure 4 for clarit y). Open time (s) 0 2 4 6 8 10 12 14 0 5 10 15 20 25 30 35 40 Average open time/client Number of clients 0 10 20 30 40 50 60 Number of errors 0 0.5 1 1.5 2 2.5 3 Errors for NORMAL mode (no skipping) Figure 9. Left: Distribution of the op en times for the different RFIO mo d es (not NORMAL). The red histogram is for < 20 simulta neous clien ts, while the black histograms is for ≥ 20. Righ t: File op en er r ors, when m ultiple client s attempt to op en files. 6.3. Server r esults 6.3.1. RFIO op en times and err ors Figure 9 (Left) sho ws ho w the a v erage op en time increases from 2 seconds for a small n umb er of clien ts ( < 20) up to around 8 seconds for a larger num b er of clien ts ( ≥ 20). Clearly , this results is dep en d en t on the hardw are used d uring the testing. W e collect ed few er statistics for clien t num b ers ≥ 23 due to the long run time of the tests. While server p erformance clearly degrades wh en man y clien ts sim ultaneously att empt to op en files, most files are op ened s uccessfully , as can b e seen in Figure 9 (Righ t). This is a substan tial impro v ement o ver earlier versions of DPM, wh ic h could only sup p ort abou t 40 op ens/s [11]. 7. F uture work 7.1. Networking As sh o wn in Section 6.2, us e of the pr o duction netw ork for the data transfer limited the data throughput relativ e to that of th e LAN. W e plan to con tinue this w ork b y making u se of a newly pro visioned light path b et w een the t w o Glasgo w and Edinburgh. This will p r o vide dedicated bandwidth with an R TT of around 2ms. 7.2. Alter native tests W e wo uld lik e to study more realistic u se cases in v olving real physics analysis co d e. In particular, w e would lik e to make use of the R OOT [12] TT reeCac he ob ject wh ich has b een shown [13] to giv e efficien t access to ROOT ob jects across the W AN. As ROOT is the prim ary to ol for analysing physic s data, it is essen tial that the p erformance b enefits of this access method are understo o d. The tests p erformed so far ha ve b een designed to simulat e access to the DPM by clien ts that op erate in an exp ected manner (i.e., op en file, read some data, close file). It wo uld b e an in teresting exercise to p erform a quanti tativ e stu dy of the storage element and net w ork wh en present ed unexp ected non-ideal use cases of the proto col. 7.3. Distribute d DPM The DPM arc hitecture allo ws for the core services and d isk servers (Section 2.1) to b e spread across d ifferen t netw ork domains. Therefore, rather than havi ng separate DPM ins tances at eac h site, we could create a single instance that spans all co llab orating institutes. How ev er, ther e are disadv an tages to this th is approac h, as an inter-site net work outage could tak e down th e en tire system. Finally , DPM do es not currently ha ve th e concept of how “expen s iv e” a particular data mo vemen t op eration would b e, whic h could impact the b ehaviour and p erformance of this setup. 7.4. Alter native pr oto c ols In add ition to RFIO, xro otd h as r ecen tly b een added as an access p roto col. This implementa tion currentl y lac ks GSI s ecur it y [6], making it unsu itable for us e across the W AN. O n ce security is enabled, it wo uld b e int eresting to p erform a similar set of tests to those p r esen ted ab o ve . Similar tests should b e p erformed wh en DPM implemen ts v4.1 of the NFS p r otocol [14 ]. 8. Conclusions Through this w ork we ha v e sho w n that it is p ossible to use RFIO to pr o vide b yte lev el acce ss to files s tored in an instance of DPM across the wid e area n et work. This h as sh o wn the p ossibilit y of unifying storage r esources across distribu ted Gr id computing and data centres, whic h is of particular relev ance to the mo del of d istributed Tier-2 sites found with in the UK GridPP pro ject. F urthermore, this sh ould b e of in terest to the data managemen t op erations of virtual organisations using Grid infrastructure as it could lead to optimised acc ess to compute and data resources, p ossibly leading to a simp ler data managemen t mo d el. Using a cu s tom clien t application, we ha ve studied th e b eha viour of RFIO access across the W AN as a fu n ction of num b er of s im ultaneous clients accessing the DPM; the different RFIO mo des; the application blo ck size and th e RFIO buffer size on th e clie n t side. W e lo oke d at the effect of v aryin g the TCP wind o w size on the data throughp ut rates and found that it had little effect, particularly wh en a large n umber of clients were sim u ltaneously reading data. F urth er w ork should b e d one to explore application op timisations b efore lo oking at the netw orking stac k. Our testing has sho wn that RFIO STREAMING mo de leads to the h ighest o v erall data transfer rates when sequen tially reading data. Th e rates achiev ed w ere of order 62MiB/s on the pro du ction JANET-UK net wo rk b etw een the UKI-SCOTGRID-GLASGOW and ScotGRID- Edinburgh s ites. F or the case where the clien t only accesses 10% of the file, RFIO mo de in NORMAL mo d e w as shown to lead to the b est o verall throughpu t as it do es not transfer data that is not r equested b y the client. F or all RFIO mo des, file op en times increase linearly with the num b er of sim u ltaneous clien ts, from ∼ 2s with small num b er of clien ts u p to ∼ 12s with 64 client s. This increase is to b e exp ected, bu t it is unclear at this time ho w it will impact on actual V O analysis co de. Finally , we hav e sho wn th at it is p ossible to access remote data using a p r otocol that is t ypically only u sed for access to lo cal grid storage. T h is could lead to a new w a y of lo oking at storage resources on the Grid and could u ltimately impact on h o w data is efficien tly and optimally managed on the Grid. Ac kno wledgmen ts The authors would like to thank all those who h elp ed in the preparation of this w ork. Pa rticular men tion should go to DPM deve lop ers for v ery helpfu l discussions an d B Garrett at the Univ ers it y of Edinburgh. This work was fund ed b y ST F C/PP AR C via the GridPP pro ject. G Stew art is fu nded b y the EU EGEE pro ject. References [1] http://www.gridpp.ac.uk [2] http://www.sc otgrid.ac.uk/ [3] Greig Co wan, Graeme Stew art, Jamie F erguson. Optimisation of Grid Enable d Stor age at Smal l Si tes. Proceedings of 6th UK eScience All H ands Meeting, P ap er Number 664, 200 6. [4] http://twiki.c ern.ch/twiki/bin/view/LCG/DpmA dminGuide [5] http://www.eu-e ge e.or g [6] http://www.globus.or g/to olkit/do cs/4.0/se curity/ [7] http://standar ds.ie e e.or g/r e gauth/p osix/index. html [8] http://twiki.c ern.ch/twiki/bin/view/EGEE/Y AIM [9] http://vdt.cs.wisc.e du/ [10] http://www.ja.net/ [11] Graeme Stew art and Greig Co w an. rfio te sts of DPM at Glasgow WLCG W ork sh op, CERN January 2007. http://indico. cern.ch/co ntributionDispla y .py?con trib I d=101&sessionId=13&confId=3738. [12] http://r o ot.c ern.ch [13] Rene Brun, Leand ro F ranco, F ons Rademakers. Efficient A c c ess to R emote Data in Hi gh Ener gy Physics CHEP07, Victoria, 2007 . http://indico. cern.ch/co ntributionDispla y .py?con trib I d=284&sessionId=31&confId=3580. [14] http://op ensolaris.or g/os/pr oje ct/nfsv41/
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment