Coordinate descent algorithms for lasso penalized regression
Imposition of a lasso penalty shrinks parameter estimates toward zero and performs continuous model selection. Lasso penalized regression is capable of handling linear regression problems where the number of predictors far exceeds the number of cases…
Authors: Tong Tong Wu, Kenneth Lange
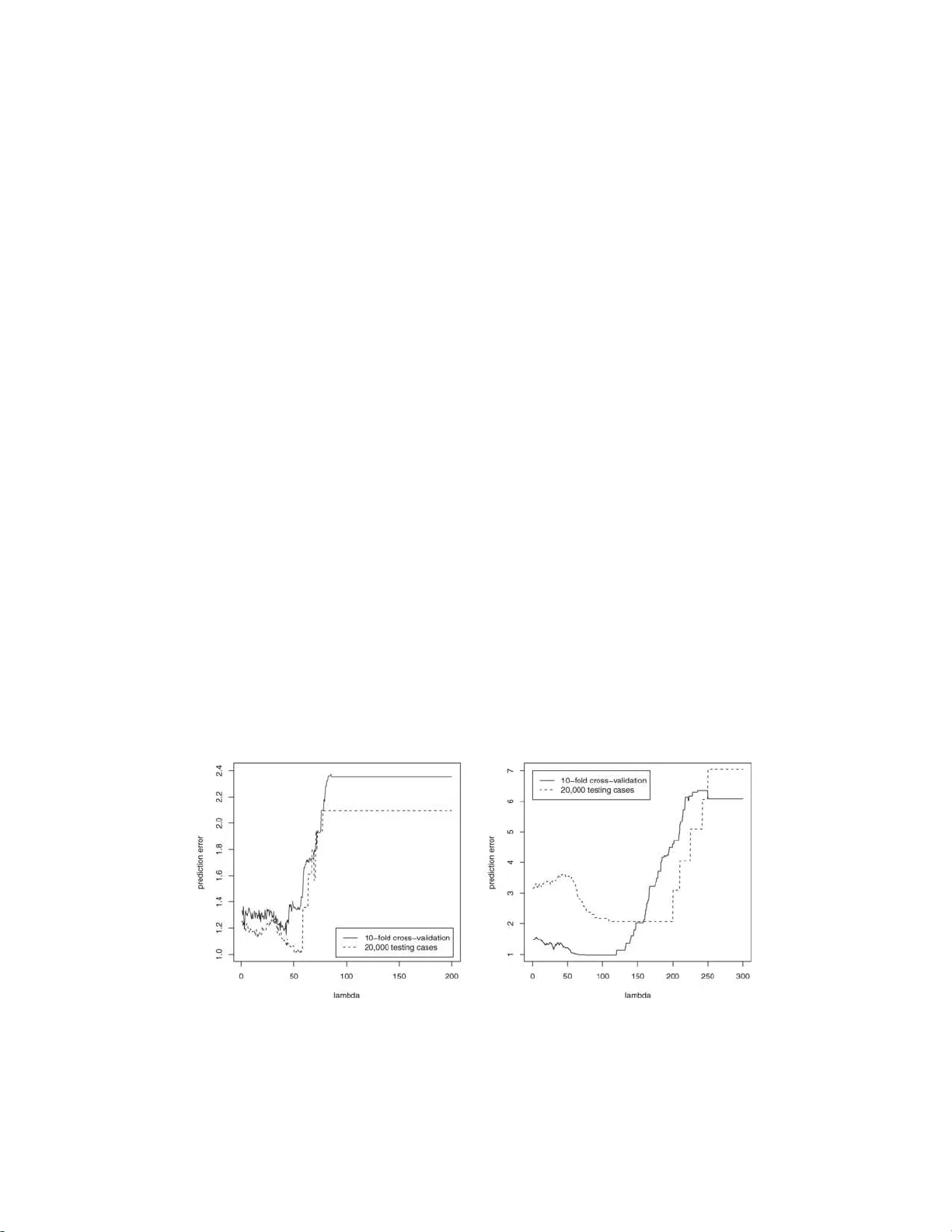
The Annals of Applie d Statistics 2008, V ol. 2, No. 1, 224–24 4 DOI: 10.1214 /07-A OAS147 c Institute of Mathematical Statistics , 2008 COORDINA TE DESCENT ALGORITHMS F OR LASSO PENALIZED RE GRESSION 1 By Tong Tong Wu and Ken n eth Lange University of Maryland , Col le ge Park and University of California , L os Angeles Imp osition of a lasso penalty shrinks parameter estima tes t o w ard zero and p erforms contin uous model selection. Lasso p enalized re- gression is capable of handling linear regressi on p roblems where the num b er of predictors far exceeds the number of cases. This p ap er tests tw o exceptionally fast algorithms for estimating regression co- efficien ts wi th a l asso penalty . T he previously known ℓ 2 algorithm is based on cyclic coordinate d escen t. Our new ℓ 1 algorithm is based on greedy coordinate descent and Edgew orth’s algorithm for ordinary ℓ 1 regressio n. Eac h algorithm reli es on a tuning constant that can be c hosen by cross-v alidation. In some regression problems it is natural to group parameters and p enalize parameters group by group rather than separately . If the group p enalty is proportional to the Euclidean norm of th e parameters of the group, then it is p ossible to ma jorize the norm and reduce p arameter e stimation to ℓ 2 regressio n with a lasso p enalty . Thus, t h e existing algorithm can b e extended to nov el settings. Each of the algorithms discussed is tested via either sim u- lated or real data or b oth. The App end ix pro ves that a greedy form of the ℓ 2 algorithm conv erges to the minim um v alue of the ob jectiv e function. 1. Introduction. This pap er explores fast algorithms for lasso p enalized regression [ Chen et al. ( 1998 ), Claerb out and Muir ( 197 3 ), San tosa and Symes ( 1986 ), T a ylor et al. ( 1979 ) and Tibsh ir ani ( 1996 )]. The lasso p erforms con- tin u ous mo del selecti on and enforces sparse solutions in p roblems wh ere the n um b er of predictors p exceeds the num b er of cases n . In the regression set- ting, let y i b e the resp onse f or case i , x ij b e the v alue of p r edictor j for case i , and β j b e the regression co efficien t corresp onding to p redictor j . The in- tercept µ is ignored in the lasso p enalt y , whose s tren gth is determined by the Received Ma y 2007; revised Octob er 2007. 1 Supp orted in part by NIH Grants GM53275 and MH59490 . Key wor ds and phr ases. Model selection, Edgewo rth’s algorithm, cyclic, greedy, c on- sistency , con verg ence. This is an electronic reprint of the or iginal article published b y the Institute of Mathematical Statistics in The Annals of Appli e d St atistics , 2008, V ol. 2, No. 1 , 22 4–24 4 . This reprint differs from the orig inal in pagination and t ypo graphic detail. 1 2 T. T. WU AND K. LA NGE p ositiv e tuning constan t λ . Giv en the parameter vec tor θ = ( µ, β 1 , . . . , β p ) t and the loss function g ( θ ), lasso p enalized regression can b e p hrased as min- imizing the criterion f ( θ ) = g ( θ ) + λ p X j =1 | β j | , (1) where g ( θ ) equals P n i =1 | y i − µ − P p j =1 x ij β j | for ℓ 1 regression and g ( θ ) equals 1 2 P n i =1 ( y i − µ − P p j =1 x ij β j ) 2 for ℓ 2 regression. The lasso p enalt y λ P p j =1 | β j | s h rinks eac h β j to wa rd the origin and tends to discourage mo dels with large n umbers of m arginally relev an t predictors. The lasso p enalt y is more effectiv e in deleting irr elev ant predictors than a ridge p enalt y λ P p j =1 β 2 j b ecause | b | is m uc h bigger than b 2 for small b . When protection against outliers is a ma jor concern, ℓ 1 regression is preferable to ℓ 2 regression [ W ang et al. ( 2006a )]. Lasso p enaliz ed estimation raises t w o issu es. First, what is the most effec- tiv e metho d of m in imizing the ob jectiv e fu nction ( 1 )? Second, ho w d o es one c ho ose the tuning parameter λ ? Although the natural ans wer to the second question is cross-v alidatio n, the issue of efficien t computation arises here as w ell. W e will discuss a useful approac h in Section 6 . T he answe r to the first question is less ob vious. Standard metho ds of regression in v olve matrix d i- agonaliz ation, matrix in v ers ion, or, at the very least, the solution of large systems of linear equations. Bec ause the n umb er of arithmetic op erations for these pro cesses scales as the cub e of the n u m b er of predictors, problems with thousands of pr edictors app ear in tractable. Recent researc h has sh o wn this assessmen t to b e to o p essimistic [ Candes and T ao ( 2007 ), Pa rk and Hastie ( 2006 a , 2006b ) and W ang et al. ( 2006a )]. In the current pap er we highlight the metho d of co ordinate descent . Our reasons for liking co ordinate descen t b oil d o wn to simplicit y , sp eed and stabilit y . F u ( 1998 ) and Daub echies et al. ( 2004 ) explicitly suggest co ordinate d e- scen t for lasso p enalized ℓ 2 regression. F or inexplicable reasons, they did n ot follo w u p their theoreti cal suggestions with n umerical confirmatio n for highly underdetermined p roblems. Claerb out and Muir ( 1973 ) note that lasso p e- nalized ℓ 1 regression also yields to coordinate descen t. Both methods are incredibly quic k and ha ve the p otent ial to r ev olutionize data mining. The comp eting linear programming algorithm of W ang et al. ( 2006a ) for p enal- ized ℓ 1 regression is motiv ated b y the problem of choosing the tuning pa- rameter λ . Their algorithm follo ws the cen tral path determined by the min- im u m of f ( θ ) as a fu nction of λ . This pro cedur e reve als exactly when eac h estimated β j en ters the linear prediction mo d el. Th e cen tral path metho d is also applicable to p enalized ℓ 2 regression and p enaliz ed estimation with generalize d linear m o dels [ P ark and Hastie ( 2006b )]. COORDINA TE DESCENT ALGORITHMS FOR PENALIZED REGRESSION 3 Besides introducing a mo d ifi cation of the ℓ 1 co ord inate descent algo- rithm, we wa n t to commen t on group selection in ℓ 2 regression. T o set the stage for b oth purp oses, we will review the previous work of F u ( 1998 ) and Daub ec h ies et al. ( 2004 ). W e approac h ℓ 1 regression through the nearly for- gotten algorithm of Edgew orth ( 1887 , 1888 ), whic h for a long time w as con- sidered a comp etito r of least squares. P ortnoy and Ko enk er ( 1997 ) trace the history of the algorithm from Bosc o vic h to L aplace to Edgew orth. It is fair to sa y that the algorithm has managed to cling to life despite decades of obscu- rit y b oth b efore and after its redisco v ery by Edgew orth. Armstrong and Ku ng ( 1978 ) published a computer imp lemen tation of Edgeworth’s algorithm in Applie d Statistics . Unfortun ately , th is v ersion is limited to simple linear re- gression. W e adapt the Claerb out and Muir ( 1973 ) v ersion of Ed gew orth’s algorithm to p erform greedy co ordinate d escen t. The resulting ℓ 1 algorithm is faster than cyclic co ordinate d escen t in ℓ 2 regression. Man y data sets in vo lv e group s of correlated predictors. F or example, in gene microarra y exp erimen ts, genes can sometimes b e group ed in to b io c h em- ical path wa ys sub jec t to ge netic coregulati on. Ex p ression lev els for genes in the same path w a y are exp ected to b e highly correlated. In such situa- tions it is prud en t to group genes and d esign p enalti es that apply to entire groups. Sev eral authors ha v e tak en up the c hallenge of p enalized estimatio n in th is con text [ Zou and Hastie ( 200 5 ), Y uan and Lin ( 2006 ) and Zhao et al. ( 2006 )]. In the current p ap er we will demonstrate that cyclic co ordin ate de- scen t is compatible w ith p en alties constructed f rom the Euclidean norms of parameter group s . W e attac k p enalized estimation by combining cyclic co- ordinate descent with p enalt y ma jorization. This replaces the n onquadratic norm p enalties by ℓ 1 or ℓ 2 p enalties. The r esulting algorithm is r eminiscen t of the generic MM algorithm for p arameter estimation [ Lange ( 2004 )]. In the remainder of the pap er Section 2 reviews cyclic co ordinate descen t for p enalized ℓ 2 regression, and Section 3 dev elops Edgew orth’s algorithm for p enalized ℓ 1 regression. S ection 4 b riefly discusses conv ergence of co ordi- nate descen t in p enaliz ed ℓ 2 regression; the App end ix prov es con ve rgence for greedy co ordinate descen t. S ection 5 amend s th e ℓ 2 algorithm to tak e into accoun t group ed parameters, and Section 6 giv es some guidance on ho w to select tuning constan ts. Sections 7 and 8 test th e algorithms on simula ted and real d ata, and Sectio n 9 summarizes their strengths and su ggests n ew a ven ues of r esearc h. Finally , we w ould like to dra w the reader’s attent ion to the recen t pap er of F riedman et al. ( 2007 ) in this journal on co ordinate descent and the fu sed lasso. Their pap er has substant ial o v erlap and sub stan tial d ifferences with ours. The tw o p ap ers we re wr itten ind ep endently and concurrent ly . 2. Cyclic co ordinate descen t for ℓ 2 regression. Coordinate descen t comes in sev eral v arieties. Th e standard v ers ion cycles through the parameters and 4 T. T. WU AND K. LA NGE up d ates eac h in tur n. An alternativ e v ersion is greedy and u p dates the pa- rameter giving the largest decrease in the ob jectiv e function. Because it is imp ossible to tell in adv ance whic h p arameter is b est to u p date, the greedy v ersion uses the surrogate criterion of steep est descen t. In other words, f or eac h parameter w e compute forward and b ac kward directional deriv ativ es and then up date the parameter with the most n egativ e directio nal d eriv a- tiv e, either forw ard or bac kwa rd. Th e o v erh ead of keeping trac k of these directional deriv ativ es wo rks to the detriment of the greedy metho d. F or ℓ 1 regression, the o v erh ead is relativ ely ligh t, and greedy co ordinate descent is substant ially faster than cyclic co ordinate d escen t. Although the lasso p enalt y is nondifferentia ble, it do es p ossess d irectional deriv ativ es along eac h forw ard or bac kw ard co ordinate direction. F or in- stance, if e k is the co ordinate direction along w hic h β k v aries, then the ob jectiv e fun ction ( 1 ) has directional d eriv ativ es d e k f ( θ ) = lim τ ↓ 0 f ( θ + τ e k ) − f ( θ ) τ = d e k g ( θ ) + λ, β k ≥ 0, − λ, β k < 0, and d − e k f ( θ ) = lim τ ↓ 0 f ( θ − τ e k ) − f ( θ ) τ = d − e k g ( θ ) + − λ, β k > 0, λ, β k ≤ 0. In ℓ 2 regression, the fu n ction g ( θ ) is differen tiable. Therefore, its direc- tional deriv ativ e along e k coincides with its ord in ary partial deriv ativ e ∂ ∂ β k g ( θ ) = − n X i =1 y i − µ − p X j =1 x ij β j ! x ik , and its directional deriv ativ e along − e k coincides with the negativ e of its ordinary p artial deriv ativ e. In ℓ 1 regression, the coord inate direction deriv a- tiv es are d e k g ( θ ) = n X i =1 − x ik , y i − µ − x t i β > 0, x ik , y i − µ − x t i β < 0, | x ik | , y i − µ − x t i β = 0, and d − e k g ( θ ) = n X i =1 x ik , y i − µ − x t i β > 0, − x ik , y i − µ − x t i β < 0, | x ik | , y i − µ − x t i β = 0, where x t i is the row ve ctor ( x i 1 , . . . , x ip ). In cyclic coordin ate descen t w e ev aluate d e k f ( θ ) and d − e k f ( θ ). If both are nonnegativ e, then we skip the up date for β k . This decision is defensi- ble when g ( θ ) is conv ex b ecause the sign of a directional deriv ativ e fully determines whether improv emen t can b e made in that dir ection. If either COORDINA TE DESCENT ALGORITHMS FOR PENALIZED REGRESSION 5 directional deriv ativ e is n egativ e, then w e must solve for the minim um in that direction. Bec ause the ob jectiv e function f ( θ ) is con v ex, it is imp ossible for b oth d irectional deriv ativ es d e k f ( θ ) and d − e k f ( θ ) to b e negativ e. In underd etermined pr oblems with just a few r elev ant predictors, most up d ates are skipp ed, and the corresp onding paramete rs nev er budge from their starting v alues of 0. This simple fact p lus the complete absence of matrix op erations explains the sp eed of cyclic co ordinate descent . It inherits its numerical stabilit y f rom the d escen t prop erty of eac h up d ate. F u ( 1998 ) deriv ed cyclic co ordin ate descen t algorithms for ℓ 2 regression with p enaltie s λ P j | β j | α with α ≥ 1. With a lasso p enalt y ( α = 1), the up d ate of the in tercept parameter can b e wr itten as ˆ µ = 1 n n X i =1 ( y i − x t i β ) = µ − 1 n ∂ ∂ µ g ( θ ) . F or the parameter β k , there are separate solutions to the left and right of 0. These amoun t to ˆ β k , − = min 0 , β k − ∂ ∂ β k g ( θ ) − λ P n i =1 x 2 ik , ˆ β k , + = max 0 , β k − ∂ ∂ β k g ( θ ) + λ P n i =1 x 2 ik . Only one of these t w o solutions can b e non zero. The partial deriv ativ es ∂ ∂ µ g ( θ ) = − n X i =1 r i , ∂ ∂ β k g ( θ ) = − n X i =1 r i x ik of g ( θ ) are easy to compute if w e k eep trac k of the residuals r i = y i − µ − x t i β . The residual r i is reset to r i + µ − ˆ µ when µ is up dated and to r i + x ik ( β k − ˆ β k ) when β k is up d ated. O rganizing all up d ates around residuals p r omotes f ast ev aluatio n of g ( θ ) . 3. Greedy co ordinate descen t for ℓ 1 regression. In greedy coordin ate descen t, we up date the parameter θ k giving th e most negativ e v alue of min { d f e k ( θ ) , d f − e k ( θ ) } . If none of the coordinate directional deriv ativ es is negativ e, then no further progress can b e made. In lasso constrained ℓ 1 re- gression greedy co ordinate descen t is quic k b ecause directional deriv ativ es are trivial to up date. Indeed, if up dating β k do es not alter the sign of the residual r i = y i − µ − x t i β for case i , then the cont ributions of case i to the v arious d irectional deriv ativ es do not change . When the residual r i b ecomes 0 or c h anges sign, these contributions are mo dified by simply adding or sub- tracting entries of the design matrix. Similar considerations apply when µ is up dated. 6 T. T. WU AND K. LA NGE T o illustrate Edgew orth’s algorithm in actio n, consider minimizing the t wo-parame ter model g ( θ ) = P n i =1 | y i − µ − x i β | with a single slop e β . T o up d ate µ , w e reca ll the w ell-kno wn connection b et w een ℓ 1 regression and medians and replace µ f or fixed β by the sample median of the n umbers z i = y i − x i β . Th is action drives g ( θ ) d o wn hill. Up d ating β for µ fixed dep ends on wr iting g ( θ ) = n X i =1 | x i | y i − µ x i − β , sorting the num b ers z i = ( y i − µ ) /x i , and fin d ing the weigh ted median with w eigh t w i = | x i | assigned to z i . W e replace β by the order statistic z [ i ] whose index i satisfies i − 1 X j =1 w [ j ] < 1 2 n X j =1 w [ j ] , i X j =1 w [ j ] ≥ 1 2 n X j =1 w [ j ] . With more than a single p redictor, we up d ate p arameter β k b y writing g ( θ ) = n X i =1 | x ik | y i − µ − P j 6 = k x ij β j x ik − β k , and find ing the w eigh ted median. Tw o criticisms hav e b een lev eled at Ed geworth’s algorithm. First, al- though it driv es the ob jectiv e fu nction steadily downhill, it sometimes con- v erges to an inferior p oint. Li and Arce ( 2004 ) giv e an example inv olv- ing the data v alues ( 0 . 3 , − 1 . 0), ( − 0 . 4 , − 0 . 1), ( − 2 . 0 , − 2 . 9), ( − 0 . 9 , − 2 . 4) and ( − 1 . 1 , 2 . 2) for the pairs ( x i , y i ) and paramete r starting v alues ( µ, β ) = (3 . 5 , − 1 . 0). Unfortunately , Li and Arce’s suggested imp ro v ement to E d gew orth’s alg o- rithm do es not generalize readily to multiv ariate linear r egression. T he sec- ond criticism is that con v ergence often o ccurs in a slo w seesa w pattern. These defects are n ot fatal. In fact, our n u merical examples sh o w that the greedy version of Edge- w orth’s algorit hm p erforms w ell on most practic al pr oblems. It has little difficult y in pic king out relev ant p redictors, and it u s u ally tak es less com- puting time to con verge than ℓ 2 regression by cyclic co ordinate d escen t. In ℓ 1 regression, greedy coordin ate descen t is considerably faster than cyclic co ord inate descen t, pr obab ly b ecause greedy co ordin ate descent attac ks the significan t pr edictors early on b efore it gets tr app ed by an inferior p oin t. Implemen ting Edgew orth’s algorithm w ith a lasso p enalt y requires view- ing th e p enalt y terms as the absolute v alues of p seudo-residuals. Thus, we write λ | β j | = | y − x t θ | b y taking y = 0 and x k = λ 1 { k = j } . Edgewo rth’s algo- rithm no w applies. Because the ℓ 1 ob jectiv e function is nondifferen tiable, it is difficult to un- derstand the theoretical prop erties of ℓ 1 estimators. Our supplementa ry app en d ix COORDINA TE DESCENT ALGORITHMS FOR PENALIZED REGRESSION 7 [W u and Lange ( 2008 )] demonstrates the weak consistency of p enalize d ℓ 1 estimators. The pr o of there builds on the previous w ork of Ob erh ofer ( 1983 ) on nonlinear ℓ 1 regression. S ince w e only consider linear mo d els, it is p ossi- ble to r elax and clarify h is stated regularit y conditions. Zhao and Y u ( 2006 ) summarize and extend previous consistency r esu lts for ℓ 2 p enalized estima- tors. 4. Conv ergence of the algorithms. The count erexample cited for Edge- w orth’s algorithm sho w s that it ma y not con ve rge to a minimum p oint. The question of con v ergence for the ℓ 2 algorithms is more int eresting. T extb o ok treatmen ts of con vergence for cycli c coordinate descen t are predicated on the assumption that the ob jectiv e f unction f ( θ ) is con tin uously differen tiable. F or exa mple, see Prop osition 5.32 of Ruszczy ´ nski ( 2006 ). Co ordinate descen t ma y fail for a n ond ifferen tiable function b ecause all directional deriv ativ es m u st b e nonn egativ e at a minim um p oint. It do es not s u ffice for just the directional deriv ativ es along the co ordinate directions to b e nonnegativ e. Unfortunately , the lasso p enalt y is nond ifferen tiable. Th e more general the- ory of Tseng ( 2001 ) do es cov er cyc lic co ord inate descen t in ℓ 2 regression, but it do es not apply to greedy coordinate d escent. In the App end ix w e demonstrate the follo wing prop ositio n. Pr oposition 1. Every cluster p oint of the ℓ 2 gr e e dy c o or dinate desc ent algorithm is a minimum p oint of the obje ctive fu nction f ( θ ) . If the minimum p oint is uniq ue, then the algorithm c onver ges to it. If the algorith m c onver ges, then its limit is a minimum p oint. Our qualitativ e theory d o es not sp ecify the r ate of con verge nce. Readers ma y wan t to compare ou r treatmen t of con v ergence to the treatmen t of F u ( 1998 ). It w ould also b e helpful to iden tify a s imp le sufficien t condition making the minim um p oint unique. Ordinarily , uniqueness is pr o ved by establishing the strict con v exit y of the ob jectiv e function. If the p roblem is o verdete rmined or the p enalt y is a ridge p enalt y , then this is an easy task. F or und erdetermined problems with lasso p enaltie s, strict con v exit y can fail. Of course, strict con vexi t y is not necessary for a u nique minimum; linear programming is full of examples to the con trary . Based on a con ve rsation with Em an u el Candes, w e conjecture that almost all (with resp ect to Leb esgue measure) d esign matrices lead to a un ique minimum. 5. ℓ 2 regression with group p enalties. The issues of mo deling and fast estimatio n are also in tert wined with group ed effects, wh ere we wan t coor- dinated p enalties that tend to include or exclude all of the parameters in a 8 T. T. WU AND K. LA NGE group. S upp ose that the β parameters o ccur in q disjoint groups and γ j de- notes the parameter v ector for group j . The lasso p enalt y λ k γ j k 1 separates parameters and do es n ot qu alify as a sensible group p enalt y . F or the same reason the scaled s um of squares λ k γ j k 2 2 is disqu alified. Ho wev er, the scaled Euclidean norm λ k γ j k 2 is an ideal group p enalt y . It couples the p arameters, it preserv es con vexit y , and, as w e show in a m oment, it m eshes we ll with cyclic co ordinate descen t in ℓ 2 regression. T o understand its group ing tendency , note that the dir ectional deriv ativ e of k γ j k 2 along e j k , the coordinate vect or corresp ond ing to γ j k , is 1 when γ j = 0 and is 0 wh en γ j 6 = 0 and γ j k = 0 . T h us, if an y parameter γ j l , l 6 = k , is nonzero, it b ecomes easier for γ j k to mo ve a w a y from 0. Recall that for a p a- rameter to mo ve a wa y from 0, the forward or b ac kward directional d eriv ativ e of the ob jectiv e fu nction m ust b e nega tiv e. If a p enalt y cont ribution to these directional deriv ativ es drops from 1 to 0, then the d irectional deriv ativ es are more lik ely to b e negativ e. In ℓ 2 regression with grouping effects, w e recommend minimizing the ob- jectiv e fu nction f ( θ ) = g ( θ ) + λ 2 q X j =1 k γ j k 2 + λ 1 q X j =1 k γ j k 1 , where g ( θ ) is the residu al sum of squ ares. If the tuning parameter λ 2 = 0, then the p enalt y r educes to the lasso. On the one hand wh en λ 1 = 0, only group p enalties en ter the picture. The mixed p enalties with λ 1 > 0 and λ 2 > 0 enforce shrink age in b oth wa ys. All mixed p enalties are norms and therefore con vex fun ctions. Noncon v ex p enaltie s complicate optimization and should b e av oided whenev er p ossible. A t eac h stage of cyclic coord inate d escen t, w e are required to minimize g ( θ ) + λ 2 k γ j k 2 + λ 1 k γ j k 1 with resp ect to a comp onen t γ j k of some γ j . If γ j = 0 , then k γ j k 2 = | γ j k | as a fu nction of γ j k . Thus, minimizatio n with resp ect to γ j k reduces to the standard up date for ℓ 2 regression with a lasso p enalt y . The lasso tuning parameter λ equals λ 1 + λ 2 is this situation. When γ j 6 = 0 , the standard up date do es not apply . Ho wev er, there is an alternativ e up date th at sta ys within the framew ork of p enalize d ℓ 2 regression. Th is alternativ e inv olv es ma jorizing the ob jectiv e function an d is motiv ated b y the MM algorithm for parameter estimation [ Lange ( 2004 )]. In view of the conca vit y of the square ro ot fun ction √ t , w e ha ve the inequalit y k γ j k 2 ≤ k γ m j k 2 + 1 2 k γ m j k 2 ( k γ j k 2 2 − k γ m j k 2 2 ) , (2) where the sup erscript m ind icates iteration num b er. Equalit y pr ev ails when- ev er γ j = γ m j . The right -hand side of inequalit y ( 2 ) is said to ma jorize the COORDINA TE DESCENT ALGORITHMS FOR PENALIZED REGRESSION 9 left-hand side. This simp le ma jorization leads to the additio nal ma jorizatio n g ( θ ) + λ 2 k γ j k 2 + λ 1 k γ j k 1 ≤ g ( θ ) + λ 2 k γ m j k 2 + 1 2 k γ m j k 2 ( k γ j k 2 2 − k γ m j k 2 2 ) + λ 1 k γ j k 1 . As a function of γ j k ignoring γ m j k , the second ma jorization amounts to a quadratic plus a lasso p enalt y . F ortunately , we kn o w ho w to minimize suc h a surrogate function. According to the argum en ts justifying the descen t p rop- ert y of the MM algorithm, minimizing th e su rrogate is guaran teed to dr iv e the ob jectiv e fu n ction d o wn hill. T o su m marize, group ed effects can b e handled by introducing p enalties defined by the Euclidean norms of the group ed p arameters. Up dating a parameter follo w s the standard recip e when the other parameters of its group are fixed at 0. If one of the other parameters from its group is nonzero, then we ma jorize the ob jectiv e function and minimize the surr ogate function with resp ect to the d esignated parameter. Again, the up date r elies on the standard recip e. Although con verge nce may b e slow ed by ma jorization, it is consisten t with cyclic co ordinate d escen t and pr eserv es the stru cture of the up d ates. 6. Selection of the tuning constan t λ . As w e men tioned earlier, sele ction of the tuning constan t λ can b e guided b y cross-v alidation. This is a one- dimensional problem, so insp ection of the graph of the cross-v alidation error curv e c ( λ ) suffi ces in a pr actica l sense. Recall that in k -fold cross-v alidation, one divides the data in to k equal batc hes (subsamples) and estimate s pa- rameters k times, lea ving one batc h out p er time. The testing err or for eac h omitted batc h is computed using the esti mates deriv ed from the r emain- ing batc hes, and c ( λ ) is compu ted by a v eraging te sting error across the k batc hes. In principle, one can subs titute other criterion for a v erage cross- v alidatio n err or. F or in stance, we could define c ( λ ) by AIC or BIC criteria. F or the sake of brevit y , we will rest cont en t w ith cross-v alidati on error. Ev aluating c ( λ ) on a grid of p oin ts can b e computational ly inefficien t, p ar- ticularly if grid p oints o ccur near λ = 0. Although w e recommend grid sam- pling on imp ortan t problems, it is useful to pursu e shortcuts. One sh ortcut com bines brack eting and golden section searc h . Because co or d inate descen t is fastest wh en λ is large and the v ast ma jority of β j are estimated as 0, it mak es sense to start lo oking for a b rac ket ing triple with a ve ry large v alue λ 0 and work down wa rd. One then rep eatedly reduces λ b y a fixed prop or- tion r ∈ (0 , 1) u ntil the condition c ( λ k +1 ) > c ( λ k ) fi rst o ccur s . This qu ickly iden tifies a brac k eting triple λ k − 1 > λ k > λ k +1 with λ k = r k λ 0 giving the smallest v alue of c ( λ ). One can no w apply golden sectio n searc h to minimize c ( λ ) on the in terv al ( λ k +1 , λ k − 1 ). With group ed parameters, finding the b est 10 T. T. WU AND K. LA NGE pair of tu ning parameters ( λ 1 , λ 2 ) is considerably m ore difficult. As a rough guess, we recommend consideration of the thr ee cases: (a) λ 1 = 0 , (b) λ 2 = 0 and (c) λ 1 = λ 2 . These one-dimensional slices yield to brac k eting and golden section searc h. Selection of the tuning constan t λ has implications in setting the initial v alue of θ . F or a single λ , we recommend sett ing θ 0 = 0 and all residu als r i = 0. As λ decreases, we exp ect curren t predictors to b e retained and p ossibly n ew on es to ent er. If we estimate ˆ θ for a giv en λ , th en it makes sense to start with ˆ θ and the corresp ondin g r esiduals for a nearb y but smaller v alue of λ . T h is tactic builds on already goo d estimates, redu ces the num b er of iteratio ns until con verge nce and sav es considerable time o ve rall in ev aluating the c ( λ ) curve. 7. Analysis of simulate d data. In ev aluating the p erformance of th e co- ordinate descen t metho ds, we pu t s p ecial emphasis on the und erdetermined setting p ≫ n h ighlighte d by W ang et al. ( 2006 a ). In the regression mo d el y i = µ + p X j =1 x ij β j + ǫ i , w e assume that the random errors ǫ i are indep end en t and follo w either a standard n ormal distribu tion or a Laplace (double exp onent ial) distribution with scale 1. The predictor v ectors x i represen t a random sample from a m u ltiv ariate normal distribution whose marginals are standard normal and whose pairwise correlations are Co v ( X ij , X ik ) = ρ, j ≤ 10 and k ≤ 10, 0 , otherwise. In every sim ulation the true parameter v alues are β j = 1 f or 1 ≤ j ≤ 5 and β j = 0 for j > 5. The qualit y of the parameter estimates and the optimal v alue of λ are naturally of in terest. T o amelio rate the shrink age of nonzero estimates for a particular λ , we alw a ys re-esti mate the activ e parameters, omitti ng the inactiv e parameters and the lasso p enalt y . T h is yields b etter parameter es- timates for testing p urp oses. The c h oice of λ dep ends on the 10-fold a v erage cross-v alidati on error curv e c ( λ ). W e sample c ( λ ) on a grid and find its minim um by brac k eting and golden section searc h as pr eviously describ ed. Giv en the optimal λ , w e re-estimate parameters from the data as a whole and compute prediction error on a testing data set of 20,000 additional cases. It is ins tru ctiv e to compare this app ro ximate prediction error to th e true prediction error u sing the true regression co efficient s. T able 1 rep orts a v erage prediction errors in ℓ 1 regression based on 50 replicates and pr oblem sizes of ( p, n ) = (5000 , 200), ( p, n ) = (5000 , 500) and COORDINA TE DESCENT ALGORITHMS FOR PENALIZED REGRESSION 11 ( p, n ) = (500 00 , 500) and b oth indep enden t pr edictors ( ρ = 0) and highly correlated predictors ( ρ = 0 . 8). The av erage n umber of predictors s electe d is listed as N nonzero , and th e a v erage n umb er of true p redictors selected is listed as N true . Average compu ting time in seconds at the optimal v alue of λ is recorded in the last column of the table. On our p ersonal compu ters, computing times are remark ably fast ev en f or data sets as large as ( p, n ) = (5000 0 , 500). I t is clear that the co ord in ate descent algorithms k eep almost all true predictors w h ile discarding the v ast ma jorit y of irrelev an t ones. Appro ximate pr ediction errors are ve ry close to true prediction errors. T o b etter understand the impact of the tuning constan t λ in p enalized ℓ 1 regression, we plot prediction error versus λ in the left panel of Figure 1 for one realization of the data. Here w e tak e ( p, n ) = (50 00 , 200), indep enden t predictors, and Laplace err ors. The solid line s ho w s prediction errors based T able 1 Simulation r esults for ℓ 1 r e gr ession with a lasso p enalty. Standar d err ors of estimates app e ar i n p ar entheses. The left err or c olumn is testing err or under the true p ar ameter values; the right err or c olum n is testing err or under the estimate d p ar ameter values β = (1 , 1 , 1 , 1 , 1 , 0 , . . . , 0) Distribution ( p, n ) ρ Error λ Error N nonzero N true Time Laplace (5000 , 200) 0.00 0.99 44.05 1.11 14.06 5.00 0.02 (4 . 43) (0 . 08) (8 . 63) (0 . 00) (0 . 01) Laplace (5000 , 200) 0.80 0.99 72.39 1.04 6.80 5.00 0.04 (13 . 60) (0 . 03) (1 . 57 ) (0 . 00) (0 . 01) Laplace (5000 , 500) 0.00 1.01 101.51 1.01 5.18 5.00 0.09 (10 . 58) (0 . 01) (0 . 65 ) (0 . 00) (0 . 01) Laplace (5000 , 500) 0.80 1.01 132.88 1.01 6.22 5.00 0.09 (34 . 93) (0 . 01) (1 . 27 ) (0 . 00) (0 . 02) Laplace (50000 , 500) 0.00 1.01 109.21 1.01 5.12 5.00 0.36 (9 . 45) (0 . 01) (0 . 32) (0 . 00) (0 . 04) Laplace (50000 , 500) 0.80 1.01 150.44 1.01 6.44 5.00 1.59 (43 . 68) (0 . 01) (1 . 12 ) (0 . 00) (0 . 33) Normal (5000 , 200) 0.00 0.80 48.46 0.84 7.84 5.00 0.03 (3 . 58) (0 . 04) (3 . 31) (0 . 00) (0 . 02) Normal (5000 , 200) 0.80 0.80 76.71 0.82 6.08 4.98 0.04 (14 . 44) (0 . 02) (0 . 93 ) (0 . 14) (0 . 01) Normal (5000 , 500) 0.00 0.80 101.71 0.81 5.48 5.00 0.05 (16 . 98) (0 . 01) (1 . 19 ) (0 . 00) (0 . 01) Normal (5000 , 500) 0.80 0.80 150.83 0.81 6.04 5.00 0.10 (47 . 28) (0 . 01) (1 . 06 ) (0 . 00) (0 . 03) Normal (50000 , 500) 0.00 0.80 112.03 0.81 5.10 5.00 0.75 (12 . 03) (0 . 01) (0 . 46 ) (0 . 00) (0 . 07) Normal (50000 , 500) 0.80 0.80 149.83 0.81 6.36 5.00 2.02 (42 . 17) (0 . 01) (1 . 09 ) (0 . 00) (0 . 45) 12 T. T. WU AND K. LA NGE on 10-fol d cross-v alidation. The dashed line shows prediction errors b ased on the 20,000 testing cases. It is n otew orthy that cross-v alidation un deres- timates the optimal v alue of λ su ggested b y testing error. Th e optimal λ based on 10-fold cross-v alidation is aroun d 45, and th e optimal λ based on 20,000 testing cases is around 50. Man y statisticia ns are comforta ble w ith this conserv ativ e bias of cross-v alidation. T able 2 rep orts the results of ℓ 2 regression under the same conditions except for normal errors. Th e cyclic co ordinate d escent algorithm for ℓ 2 re- gression is sligh tly m ore reliable, sligh tly less parsimonious and considerably slo wer than the greedy co ordinate descent algorithm for ℓ 1 regression. Th e righ t panel of Figure 1 plots cross-v alidatio n error and appro ximate predic- tion error versus λ . T able 3 compares the sp eed and p erformance of three algorithms for lasso p enalized ℓ 2 regression on one r ealization of eac h of the simulat ed data sets with norm ally distributed errors. Because LARS [ Hastie and Efron ( 2007 )] is considered by many to b e the b est comp eting algorithm, it is reasonable to limit our comparison of the t wo ve rsions of co ordinate d escen t to LARS. Three conclusions can b e dr a wn from T able 3 . First, cyclic co ordinate d e- scen t is defi n itely faster than greedy co ordinate d escen t for ℓ 2 regression. Second, b oth m etho ds are considerably faster and more robust than LARS . Third, b oth metho ds are more successful than LARS in mod el select ion. Note that the error estimates in the table for the co ordinate descen t algo- rithms reflect the re-estimat ion step ment ioned earlier. This ma y pu t LARS at a disadv anta ge. T able 4 compares the greedy coord inate descen t and cyclic co ord inate descen t algorithms for ℓ 1 regression. The settings are the same as in T able Fig. 1. L eft p anel: Plot of pr e di ction err or versus λ in ℓ 1 r e gr ession of simulate d data. Right p anel: Plot of pr e diction err or versus λ in ℓ 2 r e gr ession of simulate d data. In b oth figur es, the solid li ne r epr esents the err ors b ase d on 10 -fold cr oss-validation, and the dashe d line r epr esents the err ors b ase d on 20 , 000 testing c ases. COORDINA TE DESCENT ALGORITHMS FOR PENALIZED REGRESSION 13 T able 2 Simulation r esults of ℓ 2 r e gr ession with a lasso p enalty. Standar d err ors of estimates app e ar i n p ar entheses. The left err or c olumn is testing err or under the true p ar ameter values; the right err or c olum n is testing err or under the estimate d p ar ameter values β = (1 , 1 , 1 , 1 , 1 , 0 , . . . , 0) Distribution ( p, n ) ρ Error λ Error N nonzero N true Time Laplace (5000 , 200) 0.00 1.97 112.17 2.13 5.70 5.00 0.0 5 (16 . 37) (0 . 15) (2 . 26) ( 0 . 00) (0 . 00) Laplace (5000 , 200) 0.80 1.97 197.84 2.13 5.98 4.86 0.3 3 (90 . 64) (0 . 15) (1 . 39) ( 0 . 45) (0 . 13) Laplace (5000 , 500) 0.00 2.03 254.62 2.03 5.20 5.00 0.1 1 (97 . 20) (0 . 06) (1 . 13) ( 0 . 00) (0 . 01) Laplace (5000 , 500) 0.80 2.03 611.90 2.03 5.30 5.00 0.8 1 (180 . 68 ) ( 0 . 04) (0 . 54) (0 . 00) (0 . 14) Laplace (50000 , 500) 0.00 2 .02 255 .96 2.03 5.04 5.00 0.91 (71 . 50) (0 . 05) (0 . 28) ( 0 . 00) (0 . 22) Laplace (50000 , 500) 0.80 2 .02 588 .38 2.04 5.64 5.00 12.30 (231 . 48 ) ( 0 . 04) (0 . 87) (0 . 00) (5 . 05) Normal (5000 , 200) 0.00 1.01 107.14 1.03 5.04 5.00 0.0 5 (22 . 11) (0 . 03) (0 . 20) ( 0 . 00) (0 . 01) Normal (5000 , 200) 0.80 1.01 216.30 1.04 5.72 4.98 0.5 2 (90 . 02) (0 . 04) (0 . 94) ( 0 . 14) (0 . 13) Normal (5000 , 500) 0.00 1.01 240.85 1.01 5.02 5.00 0.1 3 (96 . 29) (0 . 01) (0 . 14) ( 0 . 00) (0 . 01) Normal (5000 , 500) 0.80 1.01 555.79 1.01 5.32 5.00 0.7 1 (214 . 27 ) ( 0 . 01) (0 . 55) (0 . 00) (0 . 09) Normal (50000 , 500) 0.00 1. 01 244. 31 1.01 5.00 5.00 0.98 (102 . 34 ) ( 0 . 01) (0 . 00) (0 . 00) (0 . 07) Normal (50000 , 500) 0.80 1. 01 549. 40 1.01 5.50 5.00 6.40 (195 . 81 ) ( 0 . 01) (0 . 70) (0 . 00) (1 . 05) 3 except that the residual errors follo w a Laplace distribution rather than a normal distribution. The last column rep orts the ratio of the ob jectiv e functions und er the t wo algorithms at their con v erged v alues. In sp ection of the table shows that the greedy algo rithm is faster than the cyclic algorithm. Both algorithms ha ve similar accuracy , and their accuracies are roughly comparable to the accuracies seen in T able 3 under the heading k ˆ β − β k 1 . These p ositiv e results reliev e our anxieties ab out p remature con verge nce with co ordinate descen t. Some of the comp eting alg orithms for ℓ 1 regression simply do not w ork on the problem sizes encounte red in the curr ent comparisons. F or in stance, the standard iterati v ely rewe igh ted least squares metho d prop osed b y Sc h lossmac her ( 1973 ) and Merle and Spath ( 1974 ) falters b ecause of the large matrix in ve r- sions required. It is also h amp ered b y infinite weigh ts for those observ ations 14 T. T. WU AND K. LA NGE T able 3 Sp e e d and ac cur acy of differ ent algorithms for lasso p enalize d ℓ 2 r e gr ession Algorithm ( p, n ) ρ N nonzero N true Time k ˆ β − β k 1 Cyclic (5000 , 200) 0 5 5 0.04 0.5159 2 Greedy 5 5 0.11 0.5156 7 LARS 94 5 2.19 3.3340 0 Cyclic (5000 , 200) 0.8 5 5 0.18 1.0154 4 Greedy 5 5 0.36 1.0189 2 LARS 35 5 5.45 1.4830 0 Cyclic (50000 , 500) 0 5 5 0. 99 0.68995 Greedy 7 5 2.90 0.6870 0 LARS not av aila ble Cyclic (50000 , 500) 0.8 5 5 4.11 0.60956 Greedy 5 5 7.94 0.6087 5 LARS not av aila ble Cyclic (500 , 5000) 0 5 5 0.24 0.0633 8 Greedy 5 5 0.36 0.0633 6 LARS 27 5 0.78 0.2537 0 Cyclic (500 , 5000) 0.8 5 5 0.30 0.1108 2 Greedy 5 5 0.71 0.1104 9 LARS 14 5 1.168 0.1888 4 with zero residuals. W e w ere unsuccessful in getting the standard soft w are of Barro dale and Rob erts ( 1980 ) to run pr op erly on these large-scal e problems. 8. Analysis of real data. W e no w turn to real data inv olving gene expres- sion lev els and ob esit y in mice. W ang et al. ( 2006b ) measured ab d ominal fat T able 4 Comp arison of gr e e dy and cyclic c o or dinate desc ent for lasso p enalize d ℓ 1 r e gr ession Algorithm ( p, n ) ρ N nonzero N true Time k ˆ β − β k 1 f greedy f cyclic Greedy (5000 , 200) 0 7 5 0.02 0.8422 8 1. 01063 Cyclic 7 5 0.10 0.9186 1 ( λ = 50) Greedy (5000 , 200) 0.8 5 5 0.04 0.53354 0.99118 Cyclic 6 5 0.39 0.7433 0 ( λ = 57 . 58) Greedy (50000 , 500) 0 5 5 0.34 0.3221 2 1. 00288 Cyclic 5 5 3.99 0.2856 5 ( λ = 124 . 5) Greedy (50000 , 500) 0.8 7 5 1.66 0.97379 1.00018 Cyclic 8 5 8.66 0.8437 2 ( λ = 110) Greedy (500 , 5000) 0 5 5 0.07 0.06680 0.99938 Cyclic 5 5 1.01 0.0660 4 ( λ = 1144 . 14) Greedy (500 , 5000) 0.8 5 5 0.13 0.12882 1.00008 Cyclic 5 5 1.53 0.1294 3 ( λ = 1144 . 14) COORDINA TE DESCENT ALGORITHMS FOR PENALIZED REGRESSION 15 mass on n = 311 F2 mice (155 males and 156 females). The F2 mice w ere created by mating tw o inbred strains an d then mating brother-sister pairs from the resulting offspring. W ang et al. also recorded the expression leve ls in liv er of p = 23 , 388 genes in eac h mouse. Our first mo del p ostulates th at the fat mass y i of mouse i satisfies y i = 1 { i male } µ 1 + 1 { i female } µ 2 + p X j =1 x ij β j + ǫ i , where x ij is the expression lev el of gene j of mouse i and ǫ i is rand om error. Since male and female mice exhibit across the b oard d ifferences in size and physi ology , it is prud en t to estimate a d ifferen t in tercept for eac h sex. The left panel of Figure 2 p lots as a function of λ the a v erage num b er of nonzero predictors and the a v erage prediction error. Here w e use ℓ 1 regression and 10-fold cross-v alidation. The righ t panel of Fig ure 2 plots the same quan tities under ℓ 2 regression. The 10-fold cross-v alidati on cur v e c ( λ ) is ragged u nder b oth ℓ 1 and ℓ 2 re- gression. F or ℓ 1 regression, exa mination of c ( λ ) o ver a fairly dense grid sho ws an optimal λ of ab out 3.5. Here the a verage num b er of nonzero predictors is 88.5, and the a v erage testing error is 0.653 3. F or the en tire data set, the n um b er of n onzero predictors is 77, and the training err or is 0.4248. F or ℓ 2 regression, the optimal λ is 7.8. Here the a v erage num b ers of pr ed ictors is 36.8, and the a v erage testing error is 0. 7704. F or the entire data set, the Fig. 2. L eft p anel: Plot of 10-fold cr oss-validation err or and numb er of pr e dictors versus λ in ℓ 1 r e gr ession of the mic e micr o arr ay data. Right p anel: Plot of 10 -fold cr oss-validation err or and numb er of pr e dictors versus λ in ℓ 2 r e gr ession of the mic e m icr o arr ay data. The lower x-axis plots the values of λ , and the upp er x-ax is plots the numb er of pr e di ctors. The y-axis is pr e diction err or b ase d on 10 -fold cr oss-validation versus λ . 16 T. T. WU AND K. LA NGE n um b er of nonzero predictors is 41, and the training error is 0.3714. The preferred ℓ 1 and ℓ 2 mo dels share 27 p redictors in common. Giv en the inherent differences b et w een the sexes, it is enligh tening to assign sex-sp ecific effect s to eac h gene and to group p arameters accordingly . These decisions translate in to the mo del y i = 1 { i male } µ 1 + p X j =1 x ij β 1 j ! + 1 { i female } µ 2 + p X j =1 x ij β 2 j ! + ǫ i = p X j =0 z t ij γ j + ǫ i , where the b iv ariate v ectors z ij and γ j group predictors and parameters, resp ectiv ely . T h us, z t ij = (1 , 0) , i is male and j = 0, (0 , 1) , i is female and j = 0, ( x ij , 0) , i is male and j > 0, (0 , x ij ) , i is female and j > 0, and γ t 0 = ( µ 1 , µ 2 ) and γ t j = ( β 1 j , β 2 j ) for j > 0. In this notation, the ob jectiv e function b ecomes f ( θ ) = 1 2 n X i =1 y i − p X j =0 z t ij γ j ! 2 + λ 2 q X j =1 k γ j k 2 + λ 1 q X j =1 k γ j k 1 . Under 10- fold cross-v alidation, the optimal pair ( λ 1 , λ 2 ) o ccurs at appro x- imately (5 , 1). This c hoice leads to an a v erage of 40.1 nonzero predictors and an av erage prediction err or of 0.81 67. F or the entire data set, the n umb er of nonzero predictors is 44, and the training error is 0.3128. Among the 44 predictors, th r ee are paired female–male slop es. Thus, the preferr ed mo del retains 41 genes in all. Among these 41 genes, 25 app ear in the ℓ 1 mo del, and 26 app ear in the ℓ 2 mo del without the group p enalties. F or all three mo dels, there are 20 genes in common. In carrying out these calcula tions, w e departed from the tac k tak en by W ang et al. ( 2006b ), who used mark er genot yp es r ather than expression lev- els as pr ed ictors. Our serendipitous choice identified some genes kno wn to b e in volv ed in fat metab olism and turned up some in teresting candidate genes. One of the kno wn genes from the short list of 20 j ust men tioned is p yru- v ate deh ydr ogenase kinase isozyme 4 (Pdk4). This mito c hond rial enzyme, whic h h as b een stud ied for its role in insulin resistance and diab etes, is a negativ e regulat or of the p yruv ate deh ydr ogenase complex. T h e upregula- tion of Pdk4 promotes gluconeoge nesis. In the co expression net work studies of Ghazalp our et al. ( 2005 , 2006 ), Pdk4 wa s one of the genes found in the mo dule asso ciated with mouse b od y w eigh t. Here we fin d that expression COORDINA TE DESCENT ALGORITHMS FOR PENALIZED REGRESSION 17 of Pdk4 is a goo d predictor of fat pad mass. It has b een su ggeste d that enhanced PDK4 expression is a co mp ensatory mec hanism coun tering the excessiv e formation of intrac ellular lipid and the exace rbation of imp aired insulin sensitivit y [ Huang et al. ( 2002 ) and Sugden ( 2003 )]. A s econd gene on our list is leuk otriene a4 hydrola se. This enzyme con- v erts leuko triene A4 to leuk otriene B4 as part of the 5-lip o o xy genase in- flammatory path wa y , whic h Mehrabian et al. ( 2005 ) rep ort in fluences adi- p osit y in ro dents. Other genes on our list includ e thr ee in v olv ed in energy metab olism: Ckm, wh ic h p lays a cen tral r ole in energy transduction; 3- h ydro xyisobut yr ate dehydroge nase, which is part of the v aline, leucine and isoleucine degradat ion pathw a y previously rep orted to b e associated with sub cutaneous fat pad mass in a differen t mouse cross [ Ghazalp our et al. ( 2005 )]; and the thiamine metab olism pathw a y gene Nsf1, whic h uses an endpro d uct of the steroid meta b olism path wa y . I n addition, we iden tified sev eral genes with n o ob vious ties to fat pad m ass, energy m etab olism, or ob esit y in general, includin g three rike n cDNAs, Plekha8, Glo xd1, the sig- naling molecule Rras, and the transcription fact or F o xj3. All of these are also present in our larger list of 27 genes ignoring sex d ep endent slop es. This larger list includes another transcription factor, an olfactory receptor gene, and an adhesion molecule. The olfactory r eceptor gene is particularly in tr iguing b eca use it could affect feeding b eha vior in mice. 9. Discussion. Lasso p enalized regression p erforms con tinuous mo del se- lectio n b y estimatio n rather than b y hyp othesis testing. Sev eral factors con- v erge to mak e p enalized regression an ideal exploratory data analysis to ol. One is the a v oidance of the knott y issues of m ultiple testing. Another is the s h eer sp eed of the co ordinate descen t algorithms. Th ese algorithms of- fer d ecisiv e adv an tages in dealing with mo d ern d ata sets where predictors wildly outn u m b er cases. If F u ( 1998 ) had w r itten his p ap er a few y ears later, this trend wo uld ha v e b een clearer, and d oubtless he w ould not ha v e concen trated on s mall problems with cases outn um b ering predictors. W e w ould n ot h a ve predicted b eforehand that the n ormally plo dding co- ordinate d escen t metho ds w ould b e so fast. In retrosp ect, it is clear that their a v oidance of matrix op erations and quic k dismissal of p o or predictors mak e all the difference. Our initial co ncern ab out the adequacy of Edge- w orth’s algorithm ha v e b een largely laid to rest by the empirical evidence. On data sets with an adequate num b er of cases, th e p o or b eha vior rep orted in the p ast d o es not pr edominate for either version of co ordinate descen t. Although the supplementa ry app en d ix [W u and Lange ( 20 08 )] pro v es that lasso constrained ℓ 1 regression is consistent , parameter estimates are biased to wa rd zero in small samples. F or this reason, on ce w e ha ve identified the activ e parameters for a giv en v alue of the tuning constan t λ , we re-estimate them ignoring the lasso p enalt y . F ailure to mak e this adj u stmen t tends to 18 T. T. WU AND K. LA NGE fa vor smaller v alues of λ in cross-v alidati on and the inclusion of irrelev an t predictors in the p referred mo del. Better un derstanding of the con vergence pr op erties of the algorithms is sorely needed. Tseng ( 2001 ) prov es con vergence of cyclic coord inate descen t for ℓ 2 p enalized regression. Our treat men t of greedy coordinate descen t in the App end ix is differen t and simp ler. Neither p ro of determines the rate of con verge nce. E ven more pressing is the chal lenge of o verco ming the theoret- ical d efects of Ed gew orth’s algorithm without compromising its sp eed. On a practical lev el, the reparameterization of Li and Arce ( 20 04 ), whic h op erates on pairs of parameters, ma y allo w Edgewo rth’s algorithm to escap e man y trap p oints. If this tactic is limite d to the activ e parameters, then sp eed m a y not degrade u nacceptably . Our algorithm for group ed parameters exploits a ma jorizatio n used in constructing other MM algorithms. Th e tec h niques and theory b ehind MM algorithms deserve to b e b etter kno wn [ Hun ter and Lange ( 2004 )]. Ma joriza- tion appro ximately doubles the n um b er of iterations un til con v ergence in th e ℓ 2 cyclic co ordin ate descen t algorithm. Although b oth the original and th e group ed ℓ 2 algorithms take hundreds of itera tions to co n v erge, eac h iterati on is so c heap that o veral l sp eed is still impressive . Lasso p enalized estimation extends far b ey ond regression. The pap ers of F u ( 1998 ) and Park and Hastie ( 2006 a , 2006b ) discuss some of th e p ossibil- ities in generalize d linear mo d els. W e hav e b egun exp erimen ting with cyclic co ord inate descent in logistic regression. Although explicit maxima for the one-dimensional subproblems are n ot a v ailable, Newton’s metho d con v erges reliably in a handful of steps. Th e results are very promising and will b e dealt with in another pap er. APPENDIX: CONVERG ENCE THEOR Y Our pro of of Pr op osition 1 splits int o a sequen ce of steps. W e first show that a minim um exists. T h is is a consequence of the con tin u it y of f ( θ ) and the co erciv eness prop ert y that lim k θ k 2 →∞ f ( θ ) = ∞ . I f an y | β j | tend s to ∞ , then the claimed limit is obvious. If all β j remain b ounded b u t | µ | tends to ∞ , then eac h squared r esidual ( y i − µ − x t i β ) 2 tends to ∞ . Selection of which comp onent of f ( θ ) to up d ate is gov erned by h ( θ ) = min i min { d e i f ( θ ) , d − e i f ( θ ) } . Although the function h ( θ ) is n ot con tin uous, it is upp er semico n tin u ous. This w eak er p rop erty will b e enough for our pu rp oses. Upp er semico n tin u it y means that lim sup m →∞ h ( θ m ) ≤ h ( θ ) whenev er θ m con verge s to θ [ Rudin ( 1987 )]. The collection of upp er semicont in uous functions includes all cont in- uous f unctions and is closed under the formation of fin ite su ms and minima. COORDINA TE DESCENT ALGORITHMS FOR PENALIZED REGRESSION 19 Ev ery directional d eriv ativ e of the r esidu al sum of squares is conti n uous. Th us, to v erify that h ( θ ) is upp er semicon tinuous, it su ffi ces to show that the co ordinate directional deriv ativ es of the p enalt y terms λ | β j | are upp er semicon tinuous. In a small enough neigh b orho od of β j 6 = 0, all coordinate directional deriv ativ es of λ | β j | are constant and therefore con tinuous. A t β j = 0 the directional d eriv ativ es along e j and − e j are b oth λ , the maxim um v alue p ossible. Hence, th e limiting inequalit y of up p er semicon tin u it y holds. An y discus s ion of con vergence m ust tak e into accoun t the stationary p oint s of the algorithm. Suc h a p oin t θ satisfies the conditions d e j f ( θ ) ≥ 0 and d − e j f ( θ ) ≥ 0 for all j . If we let µ v ary along the co ordinate d irection e 0 , then straightfo rw ard calculations pr o duce the general directional deriv ativ e d v f ( θ ) = X j ∂ ∂ θ j g ( θ ) v j + λ X j > 0 v j , θ j > 0, − v j , θ j < 0, | v j | , θ j = 0. It follo w s that d v f ( θ ) = X v j > 0 d e j f ( θ ) v j + X v j < 0 d − e j f ( θ ) | v j | and that eve ry d irectional deriv ativ e is nonn egativ e at a stationary p oint . Because f ( θ ) is con v ex, the difference quotien t s − 1 [ f ( θ + sv ) − f ( θ )] is increasing in s > 0 . Therefore, f ( θ + v ) − f ( θ ) ≥ d v f ( θ ), and if θ is a sta- tionary p oin t, then f ( θ + v ) ≥ f ( θ ) for all v . I n other w ords, θ is a minimum p oint . Con v ersely , it is trivial to c hec k that d v f ( θ ) ≥ 0 f or eve ry v when θ is a minimum p oin t. Hence, stationary p oints and min im u m p oin ts coincide. With th ese preliminaries in min d, supp ose the sequence θ m generated by greedy coordinate descent h as a subsequence θ m k con vergi ng to a nonsta- tionary p oint θ ∗ . By virtue of semicon tinuit y , w e hav e h ( θ m k ) ≤ 1 2 h ( θ ∗ ) < 0 (A.1) for infinitely many k . W e w ill demonstrate that this inequalit y f orces the decreasing sequence f ( θ m ) to con verge to −∞ , con tradicting the fact that f ( θ ) is b ou n ded b elo w. In fact, we will demonstrate that there exists a constan t c > 0 with f ( θ m k +1 ) ≤ f ( θ m k ) − c for all θ m k satisfying inequalit y ( A.1 ). The existence of the constan t c is tied to the second d eriv ativ es ∂ 2 ∂ θ 2 j f ( θ ) = n X i =1 x 2 ij of f ( θ ) along eac h co ordinate d irection. Let b = max j P n i =1 x 2 ij . No w supp ose that θ m k satisfies inequalit y ( A.1 ). F or notational simplicit y , let y = θ j b e the comp onen t b eing u p d ated, x = θ m k j , and s ( y ) = f ( θ ) as a function of θ j . Pro vided w e restrict y to the side of 0 sh o win g the most 20 T. T. WU AND K. LA NGE negativ e directional deriv ativ e, s ( y ) is t wice differentia ble and satisfies the ma jorizatio n s ( y ) = s ( x ) + s ′ ( x )( y − x ) + 1 2 s ′′ ( z )( y − x ) 2 ≤ s ( x ) + s ′ ( x )( y − x ) + 1 2 b ( y − x ) 2 . If w = x − s ′ ( x ) b denotes the minimum of the ma jorizing quadratic, then s ( w ) ≤ s ( x ) + s ′ ( x )( w − x ) + 1 2 b ( w − x ) 2 = s ( x ) − 1 2 s ′ ( x ) 2 b . A t the minimum z of s ( y ) we hav e s ( z ) ≤ s ( w ) ≤ s ( x ) − 1 2 s ′ ( x ) 2 b . This id en tifies the constan t c as c = 1 2 b [ 1 2 h ( θ ∗ )] 2 and completes the pro of of the prop osition. Ac kn o wledgments. W e thank the Departmen t of Statistic s at Stanford Univ ersity for hosting our extended visit during the 2006 –200 7 academic y ear. Jak e Lusis of UCLA kindly p ermitted u s to use the W ang et al. ( 2006b ) mouse data. An atole Ghazalp our help ed in terpret the statistical analysis of these data. Eman uel Cand es p oin ted out references p ertinen t to the h istory of the lasso and clarified our thinking ab out con ve rgence of the ℓ 2 greedy algorithm. SUPPLEMENT AR Y MA TERIAL Pro of of w eak consistency of Lasso p enalized ℓ 1 regression (doi: 10.121 4/07- A OAS147SUPP ; .p d f ). Our su pplemen tary app endix d emon- strates the wea k consistency of p enalized ℓ 1 estimators. The pro of is a straigh tforward adaptation of the arguments of Ob erh ofer ( 1983 ) on non- linear ℓ 1 regression. Since we only consider linear mo dels, the regularit y conditions in Ob erhofer ( 1983 ) are relaxed and clarified. REFERENCES Armstro ng, R. D. and Kung, M . T. (1978). A lgorithm AS 132: Least absolute v alue estimates for a simple linear regressio n problem. Appl. Statist. 27 363–3 66. Barrod ale, I. and Ro ber ts, F. D. (1980). Algorithm 552: Solution of the constrained ℓ 1 linear approximati on problem. ACM T r ans. Math. Softwar e 6 231–235. Candes, E. and T a o, T . (2007). The Dantzig selector: Statistical estimation when p is muc h larger than n (with d iscussion). An n. Statist. 35 2313–2 404. Chen, S. S., Donoho, D. L. and S aunders, M. A. (1998). Atomic decomp osition by basis pursuit. SI AM J. Sci. Comput. 20 33–61. MR163909 4 Claerbout, J. F. and Muir, F. (1973). Robust mo deling with erratic data. Ge ophysics 38 826–844. COORDINA TE DESCENT ALGORITHMS FOR PENALIZED REGRESSION 21 Da ubechies, I., Defrise, M. and De Mol, C. (2004). An iterativ e thresholding algo- rithm for linear inv erse problems with a sparsity constraint. Comm. Pur e Appl. Math. 57 1413–1457 . MR207770 4 Edgew or th, F. Y. ( 1887). On observ ations relating to sev eral quantities. Hermathena 6 279–28 5. Edgew or th, F. Y. (1888). O n a new metho d of reducing observ ations relating to several quantities . Philosophic al Magazine 25 184–1 91. Friedman, J., Hastie, T., Hofling, H. and Tibshirani, R. (2007). P athwise co ordinate optimization. Ann. Appl. Statist . 1 302–332. Fu, W. J. (1998). P enalized regressions: The bridge vers us the lasso. J. Comput. Gr aph. Statist. 7 397–416. MR164671 0 Ghazalpour, A., Doss, S., Sheth, S. S., Ingram-Drake, L. A., Schad t, E. E., Lusis, A. J. and Drake, T. A. (2005). Genomic analysis of metab olic pathw a y gene expression in mice. Nat. Genet. 37 1224–1233. Ghazalpour, A., Doss, S., Zhan g , B., W an g, S., Plaisier, C., Ca stellanos, R., Bro zell, A., Schadt, E. E., Drake, T. A., Lu si s, A. J. and Hor v a th, S . (2006). Integra ting genetic and net w ork analysis to c haracterize genes related to mouse weig ht. PL oS Genet. 2 e130. Hastie, T. and Efr on, B. (2007). The LARS P ac k age. Huang, B., Wu, P., Bowk er-Kinley, M. M. and Harris, R. A. (200 2). Regula- tion of pyruv ate dehydrogenase kinase expression by p eroxisome proliferator-activ ated receptor-alpha ligands. Di ab etes 51 276–283. Hunter, D. R . and Lange, K. (2004). A tutorial on MM algorithms. A mer. Statist. 58 30–37. MR205550 9 Lange, K. ( 2004). Optimization . Springer, New Y ork. MR2072 899 Li, Y . and Arce, G. R. ( 2004). A maximum likeli ho od approac h to least absolute d evi- ation regression. EURASI P J. Applie d Signal Pr o c. 2004 1762–1769. MR213198 7 Mehrabian, M., Alla yee, H., Stockton, J., Lum, P. Y., Drake, T. A., Castellani, L. W., Suh, M., Armour, C., Edw ards, S., Lamb, J., Lusis, A. J. and Schad t, E. E. (2005). Integrating genot y pic and expression data in a segregating mouse p op- ulation to identif y 5-lip oxygenase as a susceptibility gene for ob esit y and b one traits. Nat. Genet. 37 1224–1233. Merle, G. and Sp a th, H. (1974). Computational exp eriences with discrete L p appro xi- mation. Computing 12 315–3 21. MR041112 5 Oberhofer, W. (1983 ). The consistency of nonlinear regression minimizing the ℓ 1 -norm. An n. Statist. 10 316–31 9. MR064274 5 P ark, M. Y. and Hastie, T. (2006a). L 1 regularizatio n path algorithm for generalized linear mo dels. T echnical Report 2006-14, Dept. S tatistics, Stanford Univ. P ark, M. Y. and Hastie, T. (2006b). Penalized logistic regressio n for detecting gene intera ctions. T ec hnical Rep ort 2006-15, Dept. Statistics, S tanford Univ. Por tnoy, S . and Ko enker, R. (1997). The Gaussian hare and the Laplacian tortoise: Computabilit y of sq uared-error versus absolute-error estimators. Statist. Sci. 12 279– 300. MR1619189 Rudin, W. (19 87). R e al and Complex A nalysis , 3rd ed. McGra w-Hill, New Y ork. MR092415 7 Ruszczy ´ nski, A. (2006). Nonli ne ar Optimization . Princeton U niv. Press. MR2199043 Santosa, F. and Symes, W. W. (1986). Linear in versi on of band-limited reflection seimo- grams. SIAM J. Sci. Statist. Comput. 7 1307–1 330. MR085779 6 Schlossma cher, E. J. (1973). An iterative technique for absol ute d ev iations curve fitting. J. A mer. Statist. Asso c. 68 857–85 9. 22 T. T. WU AND K. LA NGE Sugden, M. C . (2003). PDK4: A factor in fatness? Ob esity R es. 11 167–1 69. T a ylor, H. L., Banks, S . C. and McCoy, J. F. (1979 ). Decon volutio n with the ℓ 1 norm. Ge ophysics 44 39–52. Tibshirani, R. ( 1996). Regression shrink age and selection via the lasso. J. R oy. Statist. So c. Ser. B 58 267–288. MR137924 2 Tseng, P. (2001). Con vergence of blo ck coordinate descent method for nondifferentiable maximization. J. Optim. The ory Appl. 109 473–492. MR183506 9 W ang, L., Gordon, M. D. and Zhu, J. (2006a). Regularized least absolute deviations regressio n and an efficient algorithm for parameter tun ing. I n Pr o c e e dings of the Sixth International Confer enc e on D ata Mi ning (ICDM’06) 690–700. IEEE Computer So ci- ety . W ang, S., Yehy a, N., Schadt, E. E., W ang, H., Drake, T. A. and Lusis, A. J. (2006b). Genetic and genomic analysis of a fat mass trait with complex inheritance revea ls marked sex sp ecificit y . PL oS Genet. 2 148–159. Wu, T. T. and Lange, K. (2008). S upplement to “Cordinate descent algo rithms for lasso p enalized regression.” DOI: 10.1214/ 07-AO AS174SUPP . Yuan, M. and Lin, Y. ( 2006). Mo del selectio n and estimation in regression with grouped v ariables. J. R oy. Statist. So c. Ser. B 68 49–67. MR221257 4 Zhao , P., R ocha, G. and Yu, B. (2006). Grouped and hierarchical model selection through composite abso lute penalties. T ec hnical rep ort, Dept. Statistics, Univ. Califor- nia, Berkeley . Zhao , P. and Yu, B. (2006 ). On mo d el selection consistency of lasso. J. Machine L e arning R ese ar ch 7 2541–256 3. MR227444 9 Zou, H . and Hastie, T. (2005). Regularizatio n and v ariable selection via the elastic n et. J. R oy. Statist. So c. Ser. B 67 301–320. MR213732 7 Dep ar tmen t of Epidemiology and Biost a tistics University of Mar y land College P ark, Mar yland 20707 USA E-mail: tt wu@umd.edu Dep ar tmen t of Bioma thema tics, Human Genetics and St a tistics University of California Los Angeles, California 90095 USA E-mail: klange@ucla.edu
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment