We study how to detect groups in a complex network each of which consists of component nodes sharing a similar connection pattern. Based on the mixture models and the exploratory analysis set up by Newman and Leicht (Newman and Leicht 2007 {\it Proc. Natl. Acad. Sci. USA} {\bf 104} 9564), we develop an algorithm that is applicable to a network with any degree distribution. The partition of a network suggested by this algorithm also applies to its complementary network. In general, groups of similar components are not necessarily identical with the communities in a community network; thus partitioning a network into groups of similar components provides additional information of the network structure. The proposed algorithm can also be used for community detection when the groups and the communities overlap. By introducing a tunable parameter that controls the involved effects of the heterogeneity, we can also investigate conveniently how the group structure can be coupled with the heterogeneity characteristics. In particular, an interesting example shows a group partition can evolve into a community partition in some situations when the involved heterogeneity effects are tuned. The extension of this algorithm to weighted networks is discussed as well.
Deep Dive into Detecting groups of similar components in complex networks.
We study how to detect groups in a complex network each of which consists of component nodes sharing a similar connection pattern. Based on the mixture models and the exploratory analysis set up by Newman and Leicht (Newman and Leicht 2007 {\it Proc. Natl. Acad. Sci. USA} {\bf 104} 9564), we develop an algorithm that is applicable to a network with any degree distribution. The partition of a network suggested by this algorithm also applies to its complementary network. In general, groups of similar components are not necessarily identical with the communities in a community network; thus partitioning a network into groups of similar components provides additional information of the network structure. The proposed algorithm can also be used for community detection when the groups and the communities overlap. By introducing a tunable parameter that controls the involved effects of the heterogeneity, we can also investigate conveniently how the group structure can be coupled with the hete
As a concise abstract model, the concept of network captures the most essential ingredients of a complex system, namely, its basic component units and their interaction configuration. This advantage -simple in form but powerful in modelling -has attracted intensive studies of complex networks in a wide spectrum of contexts, ranging from natural sciences to engineering problems and human societies [1,2,3]. Roughly speaking, the investigations mainly fall into two categories: seeking the topological characteristics and their origins in one and understanding how they interact with the dynamical processes supported by the networks in the other. It has been found that topological characteristics, such as small-world [4] and scale-free [5] properties, are quite general; they are common features in a large set of networks from various fields. Moreover, they are closely related to the dynamical processes on the networks. Illuminating examples among many others include epidemic spreading, to which the surprising implications of the scale-free property have been well illustrated [6,7]; and network synchronization, where the role played by the topology can be marvellously separated and appreciated by analyzing the master stability function [8]. Such progress has greatly enhanced our belief in the significance of identification and detection of these important topological characteristics [1,2,3].
Community is another common topological feature that exists in many complex networks. Intuitively, a community refers to a set of nodes whose connections between themselves are denser than their connections to the nodes outside the set [9,10,11,12]. Community detection is very important in network studies, because communities usually govern certain functions as seen in many biochemical networks [13] and social networks [14]. Communities also have important implications to the dynamical processes based on the networks, such as synchronization [15,16,17,18], percolation and diffusion [19,20,21,22]. In addition, in networks of large size, community structure may serve as a crucial guide for reducing the network, which is believed to be helpful in shedding light on the most essential properties of a complex system [23,24]. In view of the importance of the community structure, there have been a lot of studies devoted to the issue of community detection. (See Ref. [25] for a recent and comprehensive review.) Recently, attempts have also been made to extend the community detection methods developed in these studies to weighted networks [26,27] and directed networks [28,29]. However, community is not the only perspective for partitioning a network. For example, in a bipartite network, the best justified partition is to separate all the nodes into two groups such that nodes in one group only link to the nodes in the other. Indeed, partition perspectives other than that of community is necessary in order to have a better understanding of both the structures of complex networks and the dynamical processes they support, as shown in [30] by the study of synchronous motions on bipartite networks.
An insightful idea is to partition a network into groups where nodes in each group share a similar connection pattern. As the connection patterns are various and can vary from group to group, this group model is very general and powerful in representing many different types of structures in a network. This idea has a long history. It was first introduced in social science by Lorrain and White [31], where the nodes of similar connection pat-tern are referred to as being structurally equivalent. This idea has fruitfully led to the analysis of networks in social [32] and computer science based on block modelling. A recent review can be found in Ref. [33].
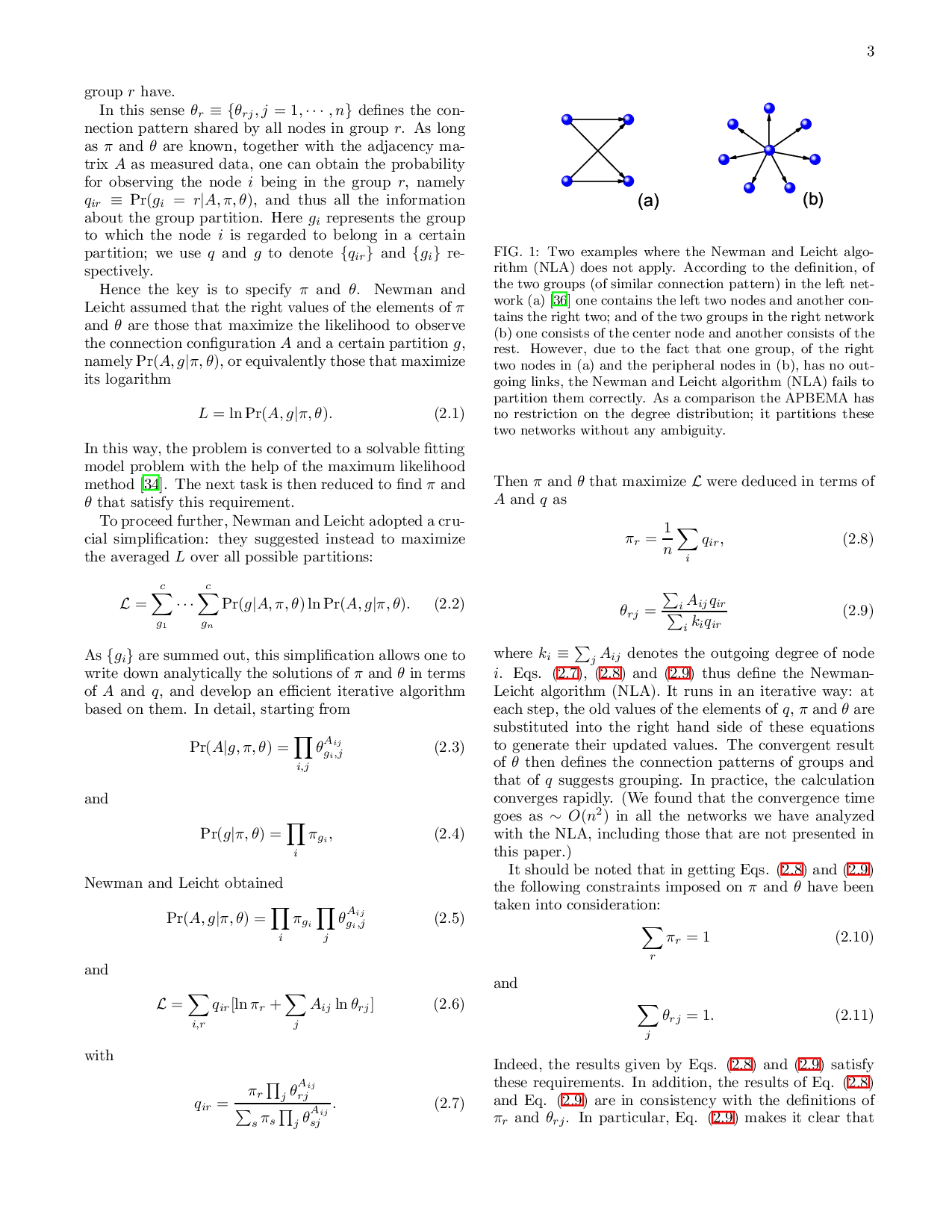
In a recent study [34], Newman and Leicht came up with a novel and general partition scheme based on this idea. It divides a network into groups of similar connection pattern. The most striking advantage of their scheme lies in that it can be applied for seeking a very broad range of types of structures in networks without any prior knowledge of the structures to be detected. In addition, the algorithm thus developed is ready to be used for both the directed and undirected networks, and it is straightforward to generalize it to analyze weighted networks [35]. The efficiency of the algorithm is also high in terms of computation complexity. Recently, Ramasco and Mungan [36] have analyzed this method in detail and devised a generalized Newman and Leicht algorithm based on their study. Other than the Newman and Leicht algorithm and its variant [36], another intriguing and insightful scheme for partitioning a network into groups of similar connection pattern has also been developed based on the information theory [37].
The Newman and Leicht theory assumes that in a group the total outgoing degree must be larger than zero [36]. This assumption limits the application of their theory. In order to overcom
…(Full text truncated)…
This content is AI-processed based on ArXiv data.