Face Detection Using Adaboosted SVM-Based Component Classifier
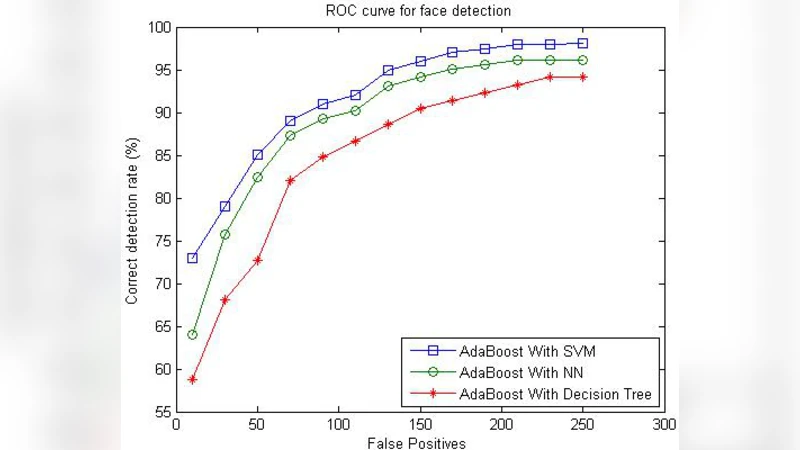
Recently, Adaboost has been widely used to improve the accuracy of any given learning algorithm. In this paper we focus on designing an algorithm to employ combination of Adaboost with Support Vector Machine as weak component classifiers to be used in Face Detection Task. To obtain a set of effective SVM-weaklearner Classifier, this algorithm adaptively adjusts the kernel parameter in SVM instead of using a fixed one. Proposed combination outperforms in generalization in comparison with SVM on imbalanced classification problem. The proposed here method is compared, in terms of classification accuracy, to other commonly used Adaboost methods, such as Decision Trees and Neural Networks, on CMU+MIT face database. Results indicate that the performance of the proposed method is overall superior to previous Adaboost approaches.
💡 Research Summary
The paper proposes a novel face‑detection framework that integrates AdaBoost with Support Vector Machines (SVMs) used as weak learners. Traditional AdaBoost typically employs extremely simple classifiers such as decision stumps or shallow trees, which are fast to train but lack the expressive power needed for complex visual patterns. Conversely, SVMs provide strong discriminative ability through margin maximization, yet their performance heavily depends on the choice of kernel and hyper‑parameters (γ for the RBF kernel width and C for regularization). Moreover, SVMs can be prone to over‑fitting on imbalanced data where one class dominates.
To combine the strengths of both methods while mitigating their weaknesses, the authors design an adaptive scheme in which each boosting round trains an SVM on a weighted subset of the training data. The subset consists of the top 30 % of samples with the highest AdaBoost weights, i.e., those that were mis‑classified in previous rounds. For this subset, the SVM’s RBF kernel parameters are adjusted dynamically: a smaller γ (wider kernel) is chosen when the weighted subset contains many difficult examples, producing smoother decision boundaries, while a larger C is used to penalize mis‑classifications more heavily. This adaptive parameter selection allows the weak SVM to remain “weak” enough to avoid over‑fitting yet sufficiently expressive to capture the nuanced facial features that cause errors in earlier rounds.
The overall algorithm proceeds as follows: (1) initialize uniform sample weights; (2) at each AdaBoost iteration, select the weighted top‑30 % subset; (3) train an RBF‑SVM on this subset with γ and C computed from the current weight distribution; (4) evaluate the weak classifier’s error ε, compute its weight α = ½ ln
Comments & Academic Discussion
Loading comments...
Leave a Comment