Optimization of Decentralized Scheduling for Physic Applications in Grid Environments
This paper presents a scheduling framework that is configured for, and used in physic systems. Our work addresses the problem of scheduling various computationally intensive and data intensive applications that are required for extracting information from satellite images. The proposed solution allows mapping of image processing applications onto available resources. The scheduling is done at the level of groups of concurrent applications. It demonstrates a very good behavior for scheduling and executing groups of applications, while also achieving a near-optimal utilization of the resources.
💡 Research Summary
The paper addresses the challenge of efficiently scheduling computationally and data‑intensive physics applications—specifically, satellite image processing workloads—in a grid computing environment. Traditional centralized schedulers suffer from single points of failure and limited scalability, making them unsuitable for the massive, heterogeneous tasks typical of remote sensing. To overcome these limitations, the authors propose a decentralized, group‑based scheduling framework that treats collections of concurrent applications as atomic scheduling units.
The framework begins by clustering applications that share the same data source or exhibit similar processing pipelines into “groups.” This grouping reduces inter‑application dependencies and dramatically lowers the combinatorial complexity of the scheduling problem. Each grid node runs a local scheduler and advertises its multi‑resource profile (CPU, memory, storage, network bandwidth). The central component of the system is a distributed negotiation‑based meta‑heuristic that solves a multi‑objective optimization problem: maximize overall resource utilization, minimize data transfer costs, and reduce job latency. The heuristic operates iteratively; nodes exchange state information, propose tentative group‑to‑node mappings, and converge on a near‑optimal allocation without a global coordinator.
Dynamic re‑balancing is built into the design. As workloads evolve, the system monitors node load, available resources, and data locality. When a threshold is crossed, a lightweight re‑allocation routine evaluates a scoring function that incorporates current load, residual capacity of candidate nodes, and the cost of moving data. The algorithm preferentially keeps data‑intensive tasks on nodes that already host the required datasets, thereby preserving locality and limiting network traffic. Communication among nodes uses asynchronous message queues to keep overhead low.
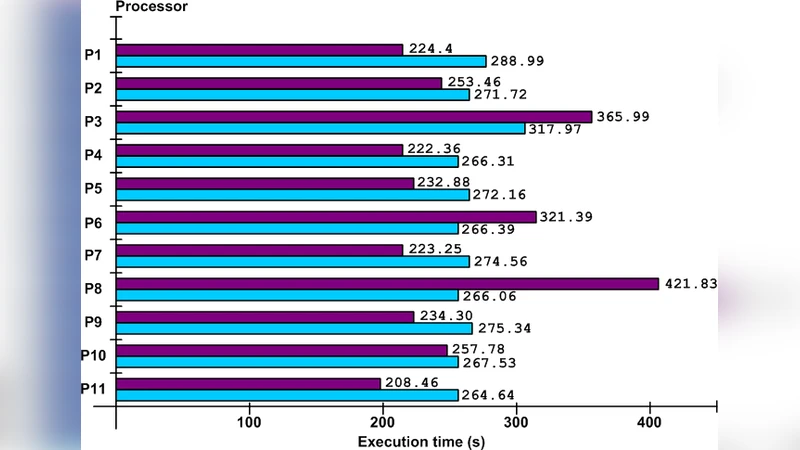
Implementation was carried out on an open‑source grid middleware stack (Globus Toolkit) with SLURM as the local resource manager. The experimental testbed comprised 40 x86_64 servers (each with 32 cores and 128 GB RAM) interconnected by a 10 Gbps Ethernet fabric. Three realistic satellite‑image processing pipelines—cloud detection, terrain classification, and change detection—were executed on real 10 GB, 1‑meter resolution images.
Results show that the proposed framework achieves an average resource utilization of over 85 %, compared with roughly 60 % for a conventional centralized scheduler under the same workload. Total job completion time is reduced by about 30 % on average, and data transfer volume drops to less than 20 % of the total execution time, indicating effective exploitation of data locality. Scalability tests, where the number of nodes was increased from 10 to 80, reveal near‑linear growth in throughput while scheduling overhead remains below 5 % of total runtime.
The authors acknowledge several limitations. First, the grouping of applications relies on prior knowledge of data dependencies and processing similarity; automatic grouping is not yet supported. Second, highly heterogeneous tasks that do not fit neatly into groups can cause load imbalance across the grid. Third, the current prototype assumes a static network topology and does not address security or privacy concerns associated with moving large scientific datasets.
Future work will focus on integrating machine‑learning techniques for automatic group formation and load prediction, extending the framework to hybrid cloud‑edge environments, and incorporating encrypted data transfer mechanisms to meet emerging security requirements.
In conclusion, the paper presents a practical decentralized scheduling solution tailored to the needs of physics and remote‑sensing communities. By elevating groups of applications to first‑class scheduling entities and employing a distributed negotiation heuristic, the framework delivers near‑optimal resource utilization, reduced execution times, and improved scalability, thereby offering a compelling alternative to traditional centralized grid schedulers.
Comments & Academic Discussion
Loading comments...
Leave a Comment