Ensuring Query Compatibility with Evolving XML Schemas
During the life cycle of an XML application, both schemas and queries may change from one version to another. Schema evolutions may affect query results and potentially the validity of produced data. Nowadays, a challenge is to assess and accommodate…
Authors: Pierre Genev`es, Nabil Laya"ida, Vincent Quint
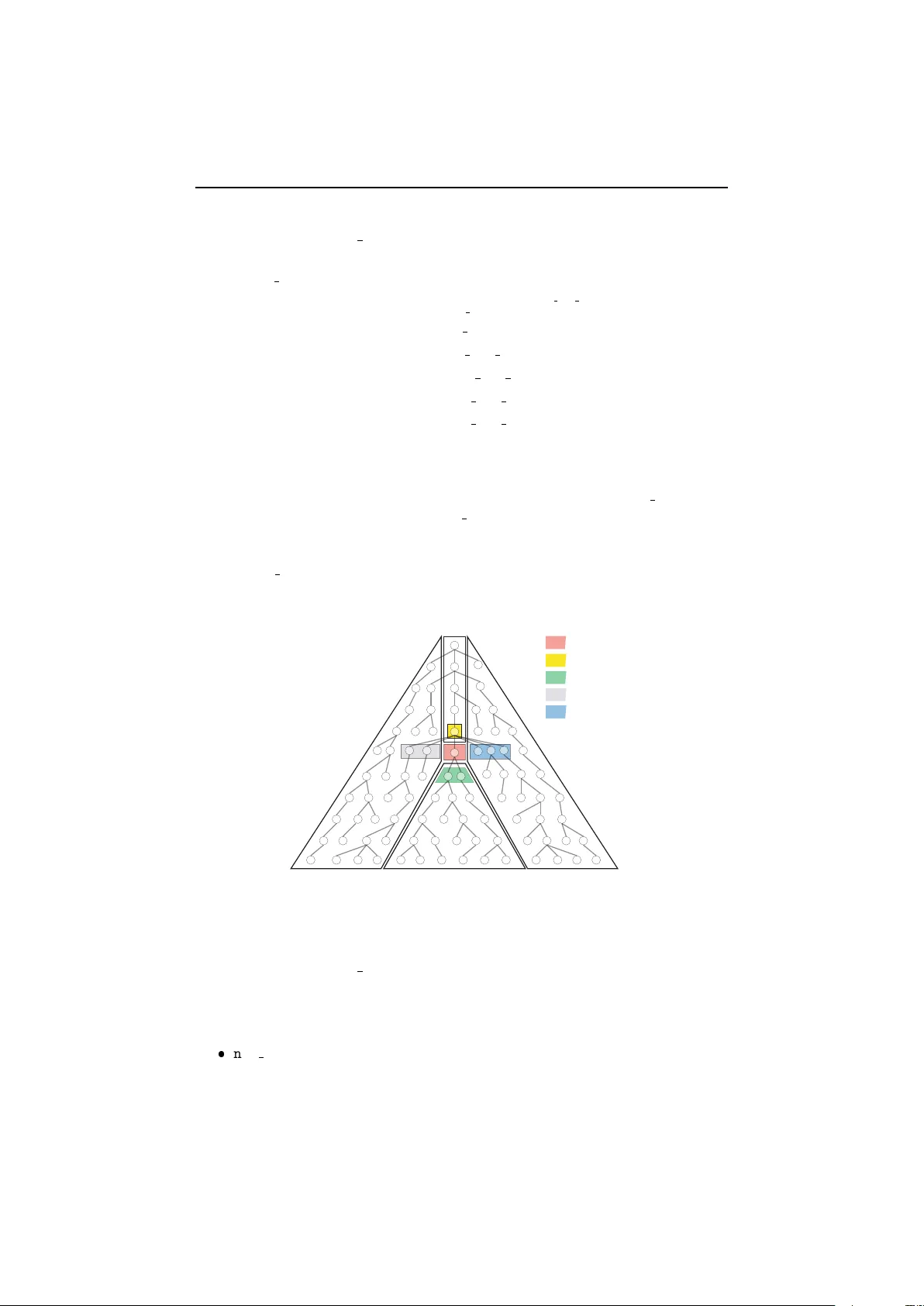
apport de recherche ISSN 0249-6399 ISRN INRIA/RR--6711--FR+ENG Thème SYM INSTITUT N A TION AL DE RECHERCHE EN INFORMA TIQUE ET EN A UTOMA TIQ UE Ensuring Query Compatibility with Ev olving XML Schemas Pierre Gene vès — Nabil Layaïda — V incent Quint N° 6711 Nov embre 2008 Centre de recherche INRIA Grenoble – Rhône-Alpes 655, av enue de l’Europe, 38334 Montbonnot Saint Ismier Téléphone : +33 4 76 61 52 00 — Télécopie +33 4 76 61 52 52 Ensuring Query Compatibilit y with Evolving XML Schemas Pierre Genev` es ∗ , Nabil La y a ¨ ıda , Vincen t Quint Th ` eme SYM — Syst ` emes symboliques ´ Equip es-Pro jets W am Rapp ort de rec herche n ° 6711 — No vem bre 2008 — 24 pages Abstract: During the life cycle of an XML application, both schemas and queries may c hange from one v ersion to another. Schema ev olutions may af- fect query results and p otentially the v alidity of pro duced data. Now adays, a c hallenge is to assess and accommo date the impact of theses changes in rapidly ev olving XML applications. This article prop oses a logical framew ork and to ol for verifying forw ard/backw ard compatibilit y issues inv olving schemas and queries. First, it allows analyzing relations b etw een schemas. Second, it allows XML designers to identify queries that must b e reformulated in order to pro duce the exp ected results across suc- cessiv e sc hema v ersions. Third, it allows examining more precisely the impact of schema changes ov er queries, therefore facilitating their reformulation. Key-w ords: XML, Sc hema, Queries, XPath, Evolution, Compatibility , Anal- ysis ∗ CNRS Ensuring Query Compatibilit y with Evolving XML Schemas R´ esum ´ e : Durant le cycle de vie d’une application XML, ` a la fois les sc h´ emas et les requˆ etes sont amen ´ es ` a ´ evoluer d’une version ` a une autre. Les ´ evolutions de sc h´ emas p euven t affecter les r´ esultats des requˆ etes et p otentiellemen t la v alidit´ e des donn´ ees pro duites. De nos jours, un vrai d´ efi consiste ` a ´ ev aluer et ` a prendre en compte l’impact de ces c hangements dans des applications XML qui ´ ev oluent rapidemen t. Cet article propose un cadre logique et un outil p our la v ´ erification des compatibilit ´ es ascendan te et descendante des sch ´ emas et des requˆ etes. T out d’ab ord, il p ermet d’analyser les relations en tre les sch ´ emas. Ensuite, il p ermet au concepteur XML d’identifier les requˆ etes qui doiven t ˆ etre reform ul ´ ees afin de pro duire les r´ esultats attendus ` a trav ers les versions successiv es des sch ´ emas. Enfin, il p ermet d’examiner de mani ` ere plus pr ´ ecise l’impact des c hangemen ts des sch ´ emas sur les requˆ etes, facitilitant de ce fait leur form ulation. Mots-cl´ es : XML, Sc hema, Requˆ etes, XP ath, Evolution, Compatibilit´ e, Ana- lyse Ensuring Query Comp atibility with Evolving XML Schemas 3 1 Introduction XML is no w commonplace on the web and in man y information systems where it is used for representing all kinds of information resources, ranging from simple text do cuments such as RSS or Atom feeds to highly structured databases. In these dynamic environmen ts, not only data are c hanging steadily but their sc hemas also get mo dified to cop e with the ev olution of the real world en tities they describ e. Sc hema c hanges raise the issue of data consistency . Existing do cuments and data that were v alid with a certain version of a schema may b ecome inv alid on a new version of the schema (forw ard incompatibility). Con versely , new do cumen ts created with the latest version of a schema may b e in v alid on some previous versions (backw ard incompatibility). In addition, schemas ma y b e written in different languages, such as DTD, XML Schema, or Relax-NG, to name only the most p opular ones. And it is common practice to describ e the same structure, or new v ersions of a structure, in different schema languages. Do cument formats developed by W3C provide a v ariety of examples: XHTML 1.0 has b oth DTDs and XML Schemas, while XHTML 2.0 has a Relax-NG definition; the sc hema for SVG Tin y 1.1 is a DTD, while v ersion 1.2 is written in Relax-NG; MathML 1.01 has a DTD, MathML 2.0 has b oth a DTD and an XML Schema, and MathML 3.0 is developed with a Relax-NG sc hema and is exp ected to hav e also a DTD and an XML Schema. An issue then is to make sure that schemas written in different languages are equiv alent, i.e. they describ e the same structure, p ossibly with some differences due to the expressivit y of the language [14]. Another issue is to clearly identify the differences b etw een t wo versions of the same sc hema expressed in differ- en t languages. Moreov er, the issues of forward and backw ard compatibilit y of instances ob viously remain when schema languages change from a version to another. V alidation, and then compatibility , is not the only purp ose of a schema. V alidation is usually the first step for safe pro cessing of do cumen ts and data. It mak es sure that do cuments and data are structured as exp ected and can then b e pro cessed safely . The next step is to actually access and select the v arious parts to b e handled in each phase of an application. F or this, query languages pla y a key role. As an example, when transforming a do cument with XSL, XP ath queries are paramount to lo cate in the original do cumen t the data to b e pro duced in the transformed do cumen t. Queries are affected by sc hema evolutions. The structures they return ma y c hange dep ending on the version of the sc hema used by a do cument. When c hanging sc hema, a query ma y return nothing, or something different from what w as exp ected, and obviously further pro cessing based on this query is at risk. These observ ations highlight the need for ev aluating precisely and safely the impact of schema ev olutions on existing and future instances of do cuments and data. They also sho w that it is imp ortant for soft ware engineers to pre- cisely kno w what parts of a pro cessing chain ha ve to b e up dated when schemas c hange. In this pap er we fo cus on the XPath query language whic h is used in man y situations while pro cessing XML do cuments and data. The XSL trans- formation language w as already mentioned, but XPath is also present in XLink and XQuery for instance. RR n ° 6711 4 Genev ` es, L aya ¨ ıda, & Quint Related W ork Sc hema evolution is an imp ortant topic and has b een extensiv ely explored in the con text of relational, ob ject-oriented, and XML databases. Most of the previous w ork for XML query reformulation is approac hed through reductions to relational problems [4]. This is b ecause schema ev olution was considered as a storage problem where the priority consists in ensuring data consistency across m ultiple relational sc hema v ersions. In such settings, tw o distinct schemas and an explicit description of the mapping b etw een them are assumed as input. The problem then consists in reform ulating a query expressed in terms of one sc hema in to a semantically equiv alen t query in terms of the other schema: see [6, 18] and more recently [12] with references thereof. In addition to the fundamental differences b etw een XML and the relational data model, in the more general case of XML pro cessing, sc hemas constan tly ev olve in a distributed, indep endent, and unpredictable en vironment. The re- lations b etw een differen t schemas are not only unknown but hard to track. In this context, one priority is to help maintaining query consistency during these ev olutions, whic h is still considered as a c hallenging problem [16]. The work found in [13] discusses the impact of evolving XML sc hemas on query reform ulation. Based on a taxonom y of XML schema changes during their ev olution, the authors pro vide informal – not exact nor systematic – guidelines for writing queries whic h are less sensitive to schema evolution. In fact, study- ing query reformulation requires at least the abilit y to analyze the relationship b et ween queries. F or this reason, a closely related w ork is the problem of deter- mining query con tainment and satisfiability under t yp e constraints [1, 9]. The w ork found in [1] studies the complexity of XPath emptiness and containmen t for v arious fragments (see [2] and references thereof for a surv ey). The main distinctive idea pursued in this pap er is to dev elop a logical ap- proac h for guiding sc hema and query ev olution. In con trast to the classical use of logics for pro ving prop erties such as query emptiness or equiv alence [1, 9], the goal here is differen t in that we seek to provide the necessary to ols to pro duce relev ant knowledge when such relations do not hold. Outline The rest of this pap er is organized as follo ws: the next section introduces our framew ork, Section 3 presents its underlying logic, and Section 4 presen ts predi- cates for characterizing the impact of sc hema c hanges. W e report on exp eriments on realistic scenarios in Section 5 b efore we conclude in Section 6. 2 Analysis F ramew ork Our framework allows the automatic verification of properties related to XML sc hema and query evolution. In particular, it offers the possibility of chec king fine-grained prop erties on the b ehavior of queries with respect to successiv e ver- sions of a given sc hema. The system can be used for chec king whether sc hema ev olutions require a particular query to b e up dated. Whenever schema ev olu- tions may induce query malfunctions, the system is able to generate annotated XML do cumen ts that exemplify bugs, with the goal of helping the programmer to understand and prop erly o vercome undesired effects of schema evolutions. INRIA Ensuring Query Comp atibility with Evolving XML Schemas 5 select("a//b[ancestor::e]", type("XHTML1-strict.dtd", "html")) XML Problem Description (T ext File) Parsing and Compilation let $ X=e & <1> $ X... Logical form ula ov er binary trees with attributes Satisfiability T est Unsatisfiable (property proved) Satisfiable Synthesis Satisfying binary tree with attributes binary to n -ary Sample XML document inducing a bug Figure 1: F ramew ork Overview. . F or these purp oses, our framew ork relies on the com bination and joint use of several contributions: an extension of the logic introduced in [9] to deal with XML attributes (Sections 2 and 3); a set of logical features and high-level predicates sp ecifically designed for studying and c haracterizing schema and query compatibility issues when sc hemas ev olve (Section 4); a range of applications and pro cedures to cop e with schema and query ev olution (Section 5); a full implementation of the whole system, including: – a parser for reading the problem description (text file), which in turn use sp ecific parsers for schemas (Section 2.2), queries (Section 2.3), logical formulas (Section 3.2), and predicates (Section 4); – compilers for translating sc hemas and queries into their logical rep- resen tations (Sections 3.3 and 3.4); – an optimized solver first described in [9, 10] for chec king satisfiabilit y of logical formulas in time 2 O ( n ) where n is the formula size; – and a coun ter example XML tree generator (describ ed in [10]). Figure 1 illustrates how the previous softw are comp onents are combined and used together, in a simplified ov erview of the global framework. W e next intro- duce the data mo del w e consider for XML do cuments, schemas and queries. 2.1 XML T rees with Attributes An XML do cument is considered as a finite tree of unbounded depth and arity , with tw o kinds of no des resp ectively named elemen ts and attributes. In such a tree, an elemen t ma y ha ve any num b er of c hildren elemen ts, and ma y carry zero, one or more attributes. A ttributes are lea ves. Elemen ts are ordered whereas attributes are not, as illustrated on Figure 4. In this pap er, we focus on the nested structure of elements and attributes, and ignore XML data v alues. 2.2 T yp e Constraints As an in ternal representation for tree grammars, we consider regular tree t yp e expressions (in the manner of [11]), extended with constrain ts o ver attributes. RR n ° 6711 6 Genev ` es, L aya ¨ ıda, & Quint Assuming a set of v ariables ranged o v er by x , w e define a tree t yp e expression as follows: τ ::= tree type expression ∅ empt y set () empt y sequence τ | τ disjunction τ , τ concatenation l ( a )[ τ ] elemen t definition x v ariable let x.τ in τ binder W e imp ose a usual restriction on the recursive use of v ariables: w e allo w un- guarded ( i.e. not enclosed by a lab el) recursive uses of v ariables, but restrict them to tail p ositions 1 . With that restriction, tree types expressions define regular tree languages. In addition, an element definition ma y in volv e simple attribute expressions that describ e whic h attributes the defined element ma y (or may not) carry: a ::= attribute expression () empt y list list | a disjunction list ::= attribute list list , list comm utative concatenation l ? optional attribute l required attribute ¬ l prohibited attribute Our tree type expressions capture most of the sc hemas in use to da y [14, 3]. In practice, our system provides parsers that con vert DTDs, XML Schemas, and Relax NGs to this internal tree t yp e representation. Users may th us define constrain ts o v er XML do cuments with the language of their choice, and, more imp ortan tly , they may refer to most existing sc hemas for use with the system. 2.3 Queries The set of XPath expressions we consider is given by the syn tax shown on Figure 2. The semantics of XP ath expressions is describ ed in [5], and more formally in [17]. W e observed that, in practice, man y XP ath expressions con tain syn tactic sugars that can also fit into this fragmen t. Figure 3 presents how our XP ath parser rewrites some commonly found XPath patterns in to the fragment of Figure 2, where the notation ( axis :: nt ) k stands for the comp osition of k successiv e path steps of the same form: axis :: nt /.../ axis :: nt | {z } k steps . 3 Logical Setting 3.1 Logical Data Mo del It is well-kno wn that there exist bijective enco dings b etw een unranked trees (trees of unbounded arity) and binary trees. Owing to these enco dings binary 1 F or instance, “ let x.l ( a )[ τ ] , x | () in x ” is allo wed. INRIA Ensuring Query Comp atibility with Evolving XML Schemas 7 query ::= / p ath absolute path p ath relativ e path query | query union query ∩ query in tersection p ath ::= p ath / p ath path comp osition p ath [ qualifier ] qualified path axis :: nt step qualifier ::= qualifier and qualifier conjunction qualifier or qualifier disjunction not( qualifier ) negation p ath path p ath / @ nt attribute path @ nt attribute step nt ::= no de test σ no de lab el ∗ an y no de lab el axis ::= tree navigation axis self | c hild | parent descendan t | ancestor descendan t-or-self ancestor-or-self follo wing-sibling preceding-sibling follo wing | preceding Figure 2: XPath Expressions. nt [p osition() = 1] nt [not(preceding-sibling:: nt )] nt [p osition() = last()] nt [not(following-sibling:: nt )] nt [p osition() = k |{z} k> 1 ] nt [(preceding-sibling:: nt ) k − 1 ] coun t( p ath ) = 0 not( p ath ) coun t( p ath ) > 0 p ath coun t( nt ) > k |{z} k> 0 nt / (follo wing-sibling:: nt ) k preceding-sibling:: ∗ [p osition() = last() and qualifier ] preceding-sibling:: ∗ [not(preceding-sibling:: ∗ ) and qualifier ] Figure 3: Syntactic Sugars and their Rewritings. RR n ° 6711 8 Genev ` es, L aya ¨ ıda, & Quint trees ma y b e used instead of unrank ed trees without loss of generalit y . In the sequel, we rely on a simple “first-child & next-sibling” enco ding of unranked trees. In this encoding, the first child of an element no de is preserved in the binary tree representation, whereas siblings of this no de are app ended as righ t successors in the binary representation. Attributes are left unchanged b y this enco ding. F or instance, Figure 5 presents how the sample tree of Figure 4 is mapp ed. XML Notation a b c d e r s t u v w x Figure 4: Sample XML T ree with Attributes. a b c d e r s t u v w x Figure 5: Binary Enco ding of T ree of Figure 4. The logic w e in tro duce below, used as the core of our framework, op erates on such binary trees with attributes. 3.2 Logical F ormulas The concrete syntax of logical form ulas is shown on Figure 6, where the meta- syn tax h X i means one or more o ccurences of X separated b y commas. The reader can directly use this syntax for enco ding form ulas as text files to b e used with the system describ ed in Section 2 [8]. This concrete syntax is used as a single unifying notation throughout all the pap er. The semantics of logical form ulas corresp onds to the classical seman tics of a µ -calculus interpreted o ver finite tree structures. A formula is satisfiable iff there exists a finite binary tree with attributes for which the formula holds at some no de. This is formally defined in [9], and we review it informally b elow through a series of examples. INRIA Ensuring Query Comp atibility with Evolving XML Schemas 9 ϕ ::= form ula T true F false l elemen t name p atomic prop osition # start con text ϕ | ϕ disjunction ϕ & ϕ conjunction ϕ => ϕ implication ϕ <=> ϕ equiv alence ( ϕ ) paren thesized form ula ˜ ϕ negation < p > ϕ existen tial mo dalit y < l >T attribute named l $ X v ariable let h $ X = ϕ i in ϕ binder for recursion pr e dic ate predicate (See Section 4) p ::= program inside mo dalities 1 first c hild 2 next sibling -1 parent -2 previous sibling Figure 6: Syntax of Logical F orm ulas. There is a difference b etw een an element name and an atomic prop osition 2 : an element has one and only one elemen t name, whereas it can satisfy multiple atomic prop ositions. W e use atomic prop ositions to attach sp ecific information to tree no des, not related to their XML labeling. F or example, the start context (a reserved atomic prop osition) is used to mark the starting context no des for ev aluating XPath expressions. The logic uses programs for na vigating in binary trees: the program 1 allo ws to navigate from a no de down to its first successor and the program 2 for na vigating from a no de do wn to its s econd successor. The logic also features con verse programs -1 and -2 for na vigating up ward in binary trees, respectively from the first successor to its parent and from the second successor to its previous sibling. T able 1 gives some simple form ulas using mo dalities for na vigating in binary trees, together with sample satisfying trees, in binary and unrank ed tree represen tations. The logic allo ws expressing recursion in trees through the recursive binder. F or example the recursive formula: let $ X = b | <2> $ X in $ X means that either the current no de is named b or there is a sibling of the curren t no de which is named b . F or this purp ose, the v ariable $ X is b ound to the subform ula b | <2> $ X which contains an o ccurence of $ X (therefore defining 2 In practice, an atomic prop osition must start with a “ ”. RR n ° 6711 10 Genev ` es, L aya ¨ ıda, & Quint Sample F ormula T ree XML a & <1>b a b a & <1>(b & <2>c) a b c T | <2> $ Y | {z } ψ Figure 7: XPath T ranslation Example. This example illustrates the need for conv erse programs inside mo dalities. The translated XP ath expression only uses forw ard axes (c hild and attribute), nev ertheless b oth forw ard and bac kward mo dalities are required for its logical translation. Without con v erse programs we would ha ve b een unable to differen- tiate selected no des from nodes whose existence is simply tested. More generally , prop erties must often be stated on both the ancestors and the descendan ts of the selected no de. Equipping the logic with b oth forward and conv erse programs is therefore crucial. Logics without con verse programs may only b e used for solv- ing XPath emptiness but cannot b e used for solving other decision problems suc h as containmen t efficien tly . A systematic translation of XPath expressions into the logic is giv en in [9]. In this pap er, we extended it to deal with attributes. W e implemented a compiler that takes any expression of the fragmen t of Figure 2 and computes its logical translation. With the help of this compiler, we extend the syntax of logical form ulas with a logical predicate select ( " query " , ϕ ). This predicate compiles the XP ath expression query given as parameter into the logic, starting from a con text that satisfies ϕ . The XP ath expression to b e giv en as parameter must matc h the syn tax of the XPath fragment shown on Figure 2 (or Figure 3). In a similar manner, w e introduce the predicate exists ( " query " , ϕ ) which tests RR n ° 6711 12 Genev ` es, L aya ¨ ıda, & Quint the existence of query from a con text satisfying ϕ , in a qualifier-like manner (without mo ving to its result). Additionally , the predicate select ( " query " ) is introduced as a shortcut for select ( " query " , # ), where # simply marks the initial con text node of the XPath expression 3 . The predicate exists ( " query " ) is a shortcut for exists ( " query " , T ). These syntactic extensions of the logic allow the user to easily em b ed XP ath expressions and formulate decision problems out of them (like e.g. con tainmen t or any other b o olean combination). In the next sections we explain how the framew ork allows com bining queries with sc hema information for formulating problems. 3.4 Compilation of T ree Types T ree t yp e expressions are compiled into the logic in tw o steps: the first stage translates them into binary tree type expressions, and the second step actually compiles this intermediate representation in to the logic. The translation pro ce- dure from tree t yp e expressions to binary tree type expressions is well-kno wn and detailed in [7]. The syntax of output expressions follows: τ ::= binary tree type expression ∅ empt y set () empt y tree τ | τ disjunction l ( a )[ x, x ] elemen t definition let x.τ in τ binder A ttribute expressions are not concerned by this transformation to binary form: they are simply attached, unchanged, to new (binary) element definitions. Fi- nally , binary tree type expressions are compiled in to the logic. The logical translation of an expression τ is given by the function tr( τ ) F T defined b elow: tr( τ ) ψ ϕ def = F for τ = ∅ , () tr( τ 1 | τ 2 ) ψ ϕ def = tr( τ 1 ) ψ ϕ | tr( τ 2 ) ψ ϕ tr( l ( a )[ x 1 , x 1 ] ) ψ ϕ def = ( l & ϕ & tra( a ) & s 1 ( x 1 ) & s 2 ( x 2 )) | ψ tr( let x i .τ i in τ ) ψ ϕ def = let $ X i = tr( τ i ) ψ ϕ in tr( τ ) ψ ϕ where the function s · ( · ) sets the type front ier: s p ( x ) = ˜ < p >T if x is b ound to () ˜ < p >T | < p > $ X if nul lable ( x ) < p > $ X if not nul lable ( x ) according to the predicate nul lable ( x ) which indicates whether the type T 6 = () b ound to x contains the empt y tree. 3 This mark is especially useful for comparing tw o or more XPath expressions from the same context. INRIA Ensuring Query Comp atibility with Evolving XML Schemas 13 The function tra( a ) compiles attribute expressions asso ciated with element definitions as follows: tra( () ) def = notothers( () ) tra( list | a ) def = tra( list ) & notothers( list ) tra( list , list 0 ) def = tra( list ) & tra( list 0 ) tra( l ? ) def = l | ˜ l tra( l ) def = l tra( ¬ l ) def = ˜ l In usual schemas ( e.g. DTDs, XML Schemas) when no attribute is sp ecified for a given element, it simply means no attribute is allow ed for the defined elemen t. This conv ention m ust b e explicitly stated into the logic. This is the role of the function “notothers( list )” which returns the negated disjunction of all attributes not present in list . As a result, taking attributes into account comes at an extra-cost. The abov e translation app ends a (p otentially very large) form ula in whic h all attributes o ccur, for each element definition. In practice, a placeholder atomic prop osition is inserted un til the full set of attributes inv olved in the problem form ulation is known. When the whole form ula has been parsed, placeholders are replaced b y the conjunction of negated attributes they denote. This extra-cost can b e observed in practice, and the system allows tw o mo des of op erations: with or without attributes 4 . Nevertheless the system is still capable of handling real world DTDs (such as the DTD of XHTML 1.0 Strict) with attributes. This is due to (1) the limited expressive p ow er of languages suc h as DTD that do not allow for disjunction ov er attribute expressions (like “ list | a ” ); and, more importantly , (2) the satisfiability-testing algorithm whic h is implemented using symbolic techniques [10]. T ree t yp e expressions form the common in ternal representation for a v ariety of XML sc hema definition languages. In practice, the logical translation of a tree t yp e expression τ are obtained directly from a v ariety of formalisms for defining sc hemas, including DTD, XML Sc hema, and Relax NG. F or this purp ose, the syn tax of logical formulas is extended with a predicate type ( " · " , · ). The logical translation of an existing sc hema is returned by type ( " f " , l ) where f is a file path to the schema file and l is the element name to b e considered as the en try p oin t (root) of the given schema. Any o ccurence of this predicate will parse the giv en sc hema, extract its in ternal tree type represen tation τ , compile it into the logic and return the logical formula tr( τ ) F T . 3.5 T yp e T agging A tag (or “color”) is introduced in the compilation of schemas with the purpose of marking all node types of a specific schema. A tag is simply a fresh atomic prop osition passed as a parameter to the translation of a tree t yp e expression. F or example: tr( τ ) F xhtml is the logical translation of τ where eac h element defini- tion is annotated with the atomic prop osition “xh tml”. With the help of tags, it b ecomes possible to refer to the element types in an y context. F or instance, 4 The optional argument “-attributes” m ust b e supplied for attributes to be considered. RR n ° 6711 14 Genev ` es, L aya ¨ ıda, & Quint one may formulate tr( τ ) F xhtml | tr( τ 0 ) F smil for denoting the union of all τ and τ 0 do cumen ts, while keeping a wa y to distinguish elemen t types; even if some elemen t names are shared by the t wo t yp e expressions. T agging b ecomes ev en more useful for characterizing ev olutions betw een suc- cessiv e versions of a single schema. In this setting, we need a wa y to distinguish no des allo wed by a newer schema version from no des allow ed by an older ver- sion. This distinction must not be based only on element names, but also on con tent mo dels. Assume for instance that τ 0 is a newer version of schema τ . If w e are in terested in the set of trees allow ed by τ 0 but not allow ed by τ then we ma y form ulate: tr( τ 0 ) F T & ˜ tr( τ ) F T If we no w wan t to c heck more fine-grained prop erties, w e may rather b e in ter- ested in the following (tagged) form ulation: tr( τ 0 ) F all & ˜ tr( τ ) ˜ old complement T In this manner, w e can distinguish elements that were added in τ 0 and whose names did not o ccur in τ , from elements whose names already o ccured in τ but whose conten t mo del c hanged in τ 0 , for instance. In practice, a type is tagged using the predicate type ( " f " , l, ϕ, ϕ 0 ) which parses the specified schema, con verts it in to its logical represen tation τ and returns the formula tr( τ ) ϕ 0 ϕ . Such kind of type tagging is useful for studying the consequences of sc hema up dates o ver queries, as presented in the next sections. 4 Analysis Predicates This section in tro duces the basic analysis tasks offered to XML application de- signers for assessing the impact of sc hema ev olutions. In particular, w e prop ose a mean for identifying the precise reasons for type mismatches or changes in query results under type constrain ts. F or this purp ose, we build on our query and type expression compilers, and define additional predicates that facilitate the formulation of decision problems at a higher level of abstraction. Sp ecifically , these predicates are introduced as logical macros with the goal of allowing system usage while focusing (only) on the XML-side prop erties, and k eeping underlying logical issues transparen t for the user. Ultimately , we regard the set of basic logical formulas (suc h as mo dalities and recursive binders) as an assembly language, to which predicates are translated. W e illustrate this principle with t wo simple predicates designed for c hecking bac kward-compatibilit y of schemas, and query satisfiability in the presence of a sc hema. The predicate backward incompatible ( τ , τ 0 ) takes tw o t yp e expressions as parameters, and assumes τ 0 is an altered version of τ . This predicate is unsatisfiable iff all instances of τ 0 are also v alid against τ . Any occurrence of this predicate in the input formula will automatically b e compiled as tr( τ 0 ) F T & ˜ tr( τ ) F T . The predicate non empty ( " query " , τ ) tak es an XP ath expression (with the syn tax defined on Figure 2) and a type expression as parameters, and is INRIA Ensuring Query Comp atibility with Evolving XML Schemas 15 unsatisfiable iff the query alwa ys returns an empty set of no des when ev aluated on an XML do cument v alid against τ . This predicate compiles in to select ( " query " , tr( τ ) F T & # ) where the predicate select ( " query " , ϕ ) compiles the XP ath expression query in to the logic, starting from a context that satisfies ϕ , as explained in Section 3.3. This can b e used to c heck whether the mo dification of the schema do es not contradict any part of the query . Notice that the predicate non empty ( " query " , τ ) can b e used for chec king whether a query that is v alid 5 against a schema remains v alid with an up dated v ersion of a sc hema. In other terms, this predicate allo ws determining whether a query that m ust alw ays return a non-empt y result (whatev er the tree on whic h it is ev aluated) keeps verifying the same property with a new version of a schema. A second, more-elab orated, class of predicates allows formulating problems that combine b oth a query query and tw o type expressions τ , τ 0 (where τ 0 is assumed to b e a ev olved version of τ ): new element name ( " query " , τ , τ 0 ) is satisfied iff the query query selects elemen ts whose names did not o ccur at all in τ . This is esp ecially useful for queries whose last na vigation step contains a “ * ” no de test and may th us select unexp ected elements. This predicate is compiled in to: ˜ element ( τ ) & select ( " query " , tr( τ 0 ) F T ) where element ( τ ) is another predicate that builds the disjunction of all el- emen t names o ccuring in τ . In a similar manner, the predicate attribute ( ϕ ) builds the logical disjunction of all attribute names used in ϕ . new region ( " query " , τ , τ 0 ) is satisfied iff the query query selects elements whose names already o ccurred in τ , but such that these no des no w o ccur in a new context in τ 0 . In this setting, the path from the ro ot of the do cumen t to a no de selected by the XPath expression query contains a no de whose type is defined in τ 0 but not in τ as illustrated b elow: node selected by query path from root to selected node contains no de in τ 0 \ τ XML document v alid against τ 0 but not against τ 5 W e say that a query is valid iff its negation is unsatisfiable. RR n ° 6711 16 Genev ` es, L aya ¨ ıda, & Quint The predicate new region ( " query " , τ , τ 0 ) is logically defined as follo ws: new region ( " query " , τ , τ 0 ) def = select ( " query " , tr( τ ) F all & ˜ tr( τ 0 ) ˜ old complement T ) & ˜ added element ( τ , τ 0 ) & ancestor ( old complement ) & ˜ descendant ( old complement ) & ˜ following ( old complement ) & ˜ preceding ( old complement ) The previous definition hea vily relies on the partition of tree no des defined b y XPath axes, as illustrated b y Figure 8. The definition of new region ( " query " , τ , τ 0 ) uses an auxiliary predicate added element ( τ , τ 0 ) that builds the disjunc- tion of all elemen t names defined in τ 0 but not in τ (or in other terms, elemen ts that w ere added in τ 0 ). In a similar manner, the predicate added attribute ( ϕ, ϕ 0 ) builds the disjunction of all attribute names de- fined in τ 0 but not in τ . self ancestor descendant preceding following following-sibling preceding-sibling child parent Figure 8: XPath axes: partition of tree no des. The predicate new region ( " query " , τ , τ 0 ) is useful for c hecking whether a query selects a different set of no des with τ 0 than with τ b ecause selected elemen ts may occur in new regions of the do cument due to changes brough t b y τ 0 . new content ( " query " , τ , τ 0 ) is satisfied iff the query query selects elements whose names were already defined in τ , but whose conten t mo del has c hanged due to evolutions brought by τ 0 , as illustrated b elow: INRIA Ensuring Query Comp atibility with Evolving XML Schemas 17 node selected by query subtree for selected node has changed (new conten t model) XML document v alid against τ 0 but not against τ The definition of new content ( " query " , τ , τ 0 ) follows: new content ( " query " , τ , τ 0 ) def = select ( " query " , tr( τ ) F all & ˜ tr( τ 0 ) ˜ old complement T ) & ˜ added element ( τ , τ 0 ) & ˜ ancestor ( added element ( τ , τ 0 )) & descendant ( old complement ) & ˜ following ( old complement ) & ˜ preceding ( old complement ) The predicate new content ( " query " , τ , τ 0 ) can b e used for ensuring that XP ath expressions will not return no des with a p ossibly new conten t mo del that ma y cause problems. F or instance, this allows chec king whether an XP ath expression whose resulting no de set is con v erted to a string v alue (as in, e.g. XPath expressions used in XSL T “v alue-of ” instructions) is affected by the changes from τ to τ 0 . The previously defined predicates can b e used to help the programmer iden- tify precisely how t yp e constraint evolutions affect queries. They can even be com bined with usual logical connectives to form ulate ev en more sophisticated problems. F or example, let us define the predicate exclude ( ϕ ) which is satisfi- able iff there is no no de that satisfies ϕ in the whole tree. This predicate can b e used for excluding sp ecific elemen t names or even no des selected by a given XP ath expression. It is defined as follows: exclude ( ϕ ) def = ˜ ancestor-or-self ( descendant-or-self ( ϕ )) This predicate can also b e used for c hecking prop erties in an iterative manner, refining the prop ert y to b e tested at each step. It can also b e used for verifying fine-grained prop erties. F or instance, one may chec k whether τ 0 defines the same set of trees as τ mo dulo new element names that w ere added in τ 0 with the following formulation: ˜ ( τ <=> τ 0 ) & exclude ( added element ( τ , τ 0 )) This allows iden tifying that, during the t yp e evolution from τ to τ 0 , the query results change has not b een caused by the t yp e extension but b y new comp osi- tions of no des from the older type. RR n ° 6711 18 Genev ` es, L aya ¨ ıda, & Quint In practice, instead of taking in ternal tree type representation s (as defined in Section 2.2) as parameters, most predicates do actually take any logical form ula as parameter, or even sc hema paths as parameters. W e b elieve this facilitates predicates usage and, most notably , how they can b e comp osed to- gether. Figure 9 gives the syntax of built-in predicates as they are implemen ted in the system, where f is a file path to a DTD (.dtd), XML Schema (.xsd), or Relax NG (.rng). In addition of aforementioned predicates, the predicate pr e dic ate ::= select ( " query " ) select ( " query " , ϕ ) exists ( " query " ) exists ( " query " , ϕ ) type ( " f " , l ) type ( " f " , l, ϕ, ϕ 0 ) forward incompatible ( ϕ, ϕ 0 ) backward incompatible ( ϕ, ϕ 0 ) element ( ϕ ) attribute ( ϕ ) descendant ( ϕ ) exclude ( ϕ ) added element ( ϕ, ϕ 0 ) added attribute ( ϕ, ϕ 0 ) non empty ( " query " , ϕ ) new element name ( " query " , " f " , " f 0 " , l ) new region ( " query " , " f " , " f 0 " , l ) new content ( " query " , " f " , " f 0 " , l ) pr e dic ate-name ( h ϕ i ) Figure 9: Syntax of Predicates for XML Reasoning. descendant ( ϕ ) forces the existence of a no de satisfying ϕ in the subtree, and pr e dic ate-name ( h ϕ i ) is a call to a custom predicate, as explained in the next section. 4.1 Custom Predicates F ollo wing the spirit of predicates presen ted in the previous section, users may also define their own custom predicates. The full syntax of XML logical spec- ifications to b e used with the system is defined on Figure 10, where the meta- syn tax h X i means one or more o ccurrence of X separated by commas. A global problem sp ecification can b e any form ula (as defined on Figure 6), or a list of custom predicate definitions separated b y semicolons and follow ed by a form ula. A custom predicate ma y hav e parameters that are instanciated with actual formulas when the custom predicate is called (as shown on Figure 9). A form ula b ound to a custom predicate ma y include calls to other predicates, INRIA Ensuring Query Comp atibility with Evolving XML Schemas 19 Sc hema V ariables Elemen ts A ttributes XHTML 1.0 basic DTD 71 52 57 XHTML 1.1 basic DTD 89 67 83 MathML 1.01 DTD 137 127 72 MathML 2.0 DTD 194 181 97 T able 2: Sizes of (Some) Considered Schemas. but not to the currently defined predicate (recursive definitions m ust b e made through the let binder sho wn on Figure 6). sp e c ::= ϕ form ula (see Fig. 6) def ; ϕ def ::= pr e dic ate-name ( h l i ) = ϕ 0 custom definition def ; def list of definitions Figure 10: Global Syn tax for Sp ecifying Problems. 5 F ramework in Action W e ha ve implemen ted the whole softw are architecture describ ed in Section 2 and illustrated on Figure 1 [8]. W e ha v e carried out extensive experiments of the system with real w orld schemas such as XHTML, MathML, SV G, SMIL (T able 2 gives details related to their resp ective sizes) and queries found in transformations such MathML conten t to presentation [15]. W e present t wo of them that show how the to ol can b e used to analyze different situations where sc hemas and queries evolv e. Ev olution of XHTML Basic The first test consists in analyzing the relationship (forw ard and bac kw ard com- patibilit y) b etw een XHTML basic 1.0 and XHTML basic 1.1 sc hemas. In par- ticular, backw ard compatibility can b e chec ked by the follo wing command: backward_incompatible("xhtml-basic10.dtd", "xhtml-basic11.dtd", "html") The test immediately yields a counter example as the new schema contains new element names. The counter example (shown b elow) contains a style elemen t o ccurring as a child of head , which is not p ermitted in XHTML basic 1.0: The next step consists in fo cusing on the relationship b et ween both sc hemas excluding these new elemen ts. This can b e form ulated b y the following com- mand: backward_incompatible("xhtml-basic10.dtd", "xhtml-basic11.dtd", "html") & exclude(added_element( type("xhtml-basic10.dtd","html"), type("xhtml-basic11.dtd", "html"))) The result of the test sho ws a counter example do cumen t that prov es that XHTML basic 1.1 is not bac kw ard compatible with XHTML basic 1.0 even if new elemen ts are not considered. In particular, the conten t mo del of the label elemen t cannot hav e an a elemen t in XHTML basic 1.0 while it can in XHTML basic 1.1. The coun ter example pro duced by the solv er is sho wn b elo w:
XTML basic 1.0 validity error: element "a" is not declared in "label" list of possible children Notice that w e observed similar forw ard and bac kward compatibilit y issues with sev eral other W3C normativ e schemas (in particular for the different v ersions of SMIL and SVG). Such backw ard incompatibilities suggests that applications cannot simply ignore new elements from newer schemas, as the combination of older elements may evolv e significantly from one v ersion to another. MathML Conten t to Presen tation Conv ersion MathML is an XML format for describing mathematical notations and capturing b oth its structure and graphical structure, also known as Conten t MathML and Presen tation MathML resp ectively . The structure of a given equation is kept separate from the presen tation and the rendering part can be generated from the structure description. This op eration is usually carried out using an XSL T transformation that ac hieves the conv ersion. In this test series, w e fo cus on the analysis of the queries con tained in suc h a transformation sheet and ev aluate the impact of the schema change from MathML 1.0 to MathML 2.0 on these queries. INRIA Ensuring Query Comp atibility with Evolving XML Schemas 21 Most of the queries con tained in the transformation represent only a few patterns very similar up to elemen t names. The following three patterns are the most frequently used: Q1: //apply[*[1][self::eq]] Q2: //apply[*[1][self::apply]/inverse] Q3: //sin[preceding-sibling::*[position()=last() and (self::compose or self::inverse)]] The first test is formulated b y the following command: new_region("Q1","mathml.dtd","mathml2.dtd","math") The result of the test shows a counter example document that prov es that the query may select no des in new con texts in MathML 2.0 compared to MathML 1.0. In particular, the query Q1 selects apply elements whose ancestors can b e declare elements, as indicated on the do cument pro duced by the solver: Notice that the solver automatically annotates a pair of no des related by the query: when the query is ev aluated from a no de marked with the attribute solver:context , the node mark ed with solver:target is selected. T o ev aluate the effect of this c hange, the counter example is filled with conten t and passed as an input parameter to the transformation. This shows immediately a bug in the transformation as the resulting document is not a MathML 2.0 presentation do cumen t. Based on this analysis, we know that the XSL T template asso ciated with the match pattern Q1 m ust be up dated to cop e with MathML evolution from version 1.0 to version 2.0. The next test consists in ev aluating the impact of the MathML t yp e evolution for the query Q2 while excluding all new elemen ts added in MathML 2.0 from the test. This identifies whether old elements of MathML 1.0 can b e comp osed in MathML 2.0 in a differen t manner. This can b e p erformed with the following command: new_content("Q2","mathml.dtd","mathml2.dtd","math") & exclude(added_element(type("mathml.dtd","math"), type("mathml2.dtd", "math"))) The test result sho ws an example do cument that effectiv ely combines MathML 1.0 elemen ts in a w ay that was not allow ed in MathML 1.0 but p ermitted in MathML 2.0. Similarly , the last test consists in ev aluating the impact of the MathML type ev olution for the query Q3 , excluding all new elements added in MathML 2.0 and counter example do cuments con taining declare elements (to av oid trivial coun ter examples): new_regions("Q3","mathml.dtd","mathml2.dtd","math") & exclude(added_element(type("mathml.dtd","math"), type("mathml2.dtd","math"))) & exclude(declare) The counter example do cument sho wn below illustrates a case where the sin elemen t o ccurs in a new context. Applying the transformation on previous examples yields do cuments which are neither MathML 1.0 nor MathML 2.0 v alid. As a result, the stylesheet cannot b e used safely ov er do cuments of the new type without mo difications. In addition, the required c hanges to the st ylesheet are not limited to the addition of new templates for MathML 2.0 elemen ts. The templates that deal with the comp osition of MathML 1.0 elemen ts should be revised as well. All the previous tests were pro cessed in less than 30 seconds on an ordinary laptop computer running Jav a under Mac OS X. 6 Conclusion In this article, w e present a logical framew ork and a to ol for verifying for- w ard/backw ard compatibility issues caused by sc hemas and queries ev olution. The to ol allows XML designers to identify queries that must b e reformulated in order to pro duce the exp ected results across successive schema v ersions. With this to ol designers can examine precisely the impact of sc hema changes ov er queries, therefore facilitating their reform ulation. W e gav e illustrations of how to use the to ol for b oth schema and query evolution on realistic examples. In particular, we considered t ypical situations in applications inv olving W3C sc hemas evolution such as XHTML and MathML. The to ol can b e v ery useful for standard sc hema writers and main tainers in order to assist them enforce some level of quality assurance on compatibility b etw een versions. INRIA Ensuring Query Comp atibility with Evolving XML Schemas 23 There are a num b er of interesting extensions to the prop osed system. First, the set of predicates can b e easily enriched to detect more precisely the impact on queries. F or example, one can extend the tagging to iden tify separately ev ery na vigation step and qualifier in a query expression. This will help greatly in the iden tification and reformulation of the na vigation steps or qualifiers affected by sc hemas ev olution. References [1] M. Benedikt, W. F an, and F. Geerts. XPath satisfiabilit y in the presence of DTDs. In PODS ’05 , pages 25–36. ACM Press, 2005. [2] M. Benedikt and C. Ko ch. XPath leashed. submitted, 2006. [3] G. J. Bex, W. Martens, F. Nev en, and T. Sc h wen tick. Expressiveness of XSDs: from practice to theory , there and back again. In WWW ’05 , pages 712–721, 2005. [4] K. Beyer, F. ¨ Ozcan, S. Saiprasad, and B. V. der Linden. DB2/XML: designing for evolution. In SIGMOD ’05 , pages 948–952. ACM, 2005. [5] J. Clark and S. DeRose. XML path language (XPath) version 1.0, W3C recommendation, No vem b er 1999. h ttp://www.w3.org/TR/ 1999/REC- xpath-19991116. [6] A. Deutsc h and V. T annen. XML queries and constrain ts, containmen t and reform ulation. The or. Comput. Sci. , 336(1):57–87, 2005. [7] P . Genev` es. L o gics for XML . PhD thesis, Insti- tut National P olytechnique de Grenoble, Decem b er 2006. h ttp://www.pierresoft.com/pierre.geneves/phd.h tm. [8] P . Genev ` es and N. Lay a ¨ ıda. A satis fiabilit y solver for XML and XPath, June 2006. http://w am.inrialp es.fr/xml. [9] P . Genev` es, N. Lay a ¨ ıda, and A. Sc hmitt. Efficient static analysis of XML paths and types. In PLDI ’07 , pages 342–351. ACM Press, 2007. [10] P . Genev` es, N. Lay a ¨ ıda, and A. Sc hmitt. Efficient static analysis of XML paths and types. Long v ersion of [9], Research Rep ort 6590, INRIA, July 2008. [11] H. Hoso ya, J. V ouillon, and B. C. Pierce. Regular expression types for XML. ACM TOPLAS , 27(1):46–90, 2005. [12] H. J. Mo on, C. A. Curino, A. Deutsch, and C.-Y. Hou. Managing and querying transaction-time databases under schema evolution. In VLDB ’08 , pages 882–895. VLDB Endowmen t, 2008. [13] M. M. Moro, S. Malaik a, and L. Lim. Preserving xml queries during sc hema ev olution. In WWW ’07 , pages 1341–1342. A CM, 2007. RR n ° 6711 24 Genev ` es, L aya ¨ ıda, & Quint [14] M. Murata, D. Lee, M. Mani, and K. Kaw aguchi. T axonom y of XML sc hema languages using formal language theory . ACM TOIT , 5(4):660– 704, 2005. [15] E. Pietriga. MathML conten t2presentation transformation, Ma y 2005. h ttp://www.lri.fr/˜pietriga/mathmlc2p/mathmlc2p.html. [16] E. Sedlar. Managing structure in bits & pieces: the killer use case for XML. In SIGMOD ’05 , pages 818–821. ACM, 2005. [17] P . W adler. Tw o semantics for XP ath. Inter- nal T ec hnical Note of the W3C XSL W orking Group, h ttp://homepages.inf.ed.ac.uk/wadler/papers/xpath-semantics/xpath- seman tics.p df, Jan uary 2000. [18] C. Y u and L. P opa. Semantic adaptation of schema mappings when schemas ev olve. In VLDB ’05 , pages 1006–1017. VLDB Endowmen t, 2005. INRIA Centre de recherche INRIA Grenoble – Rhône-Alpes 655, av enue de l’Europe - 38334 Montbonnot Saint-Ismier (France) Centre de recherche INRIA Bordeaux – Sud Ouest : Domaine Univ ersitaire - 351, cours de la Libération - 33405 T alence Cedex Centre de recherche INRIA Lille – Nord Europe : Parc Scientifique de la Haute Borne - 40, a venue Halley - 59650 V illeneuve d’Ascq Centre de recherche INRIA Nancy – Grand Est : LORIA, T echnopôle de Nancy-Brabois - Campus scientifique 615, rue du Jardin Botanique - BP 101 - 54602 V illers-lès-Nancy Cedex Centre de recherche INRIA Paris – Rocquencourt : Domaine de V oluceau - Rocquencourt - BP 105 - 78153 Le Chesnay Cedex Centre de recherche INRIA Rennes – Bretagne Atlantique : IRISA, Campus univ ersitaire de Beaulieu - 35042 Rennes Cedex Centre de recherche INRIA Saclay – Île-de-France : Parc Orsay Uni versité - ZA C des Vignes : 4, rue Jacques Monod - 91893 Orsay Cedex Centre de recherche INRIA Sophia Antipolis – Méditerranée : 2004, route des Lucioles - BP 93 - 06902 Sophia Antipolis Cedex Éditeur INRIA - Domaine de V oluceau - Rocquencourt, BP 105 - 78153 Le Chesnay Cedex (France) http://www.inria.fr ISSN 0249-6399
Comments & Academic Discussion
Loading comments...
Leave a Comment