Predictive learning via rule ensembles
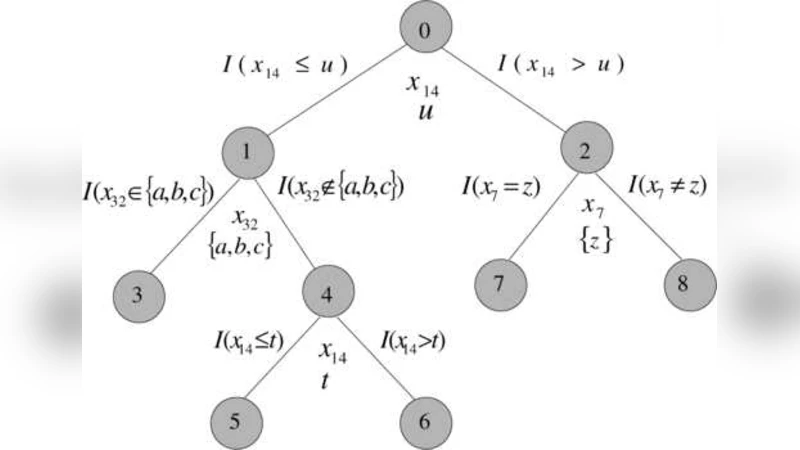
General regression and classification models are constructed as linear combinations of simple rules derived from the data. Each rule consists of a conjunction of a small number of simple statements concerning the values of individual input variables. These rule ensembles are shown to produce predictive accuracy comparable to the best methods. However, their principal advantage lies in interpretation. Because of its simple form, each rule is easy to understand, as is its influence on individual predictions, selected subsets of predictions, or globally over the entire space of joint input variable values. Similarly, the degree of relevance of the respective input variables can be assessed globally, locally in different regions of the input space, or at individual prediction points. Techniques are presented for automatically identifying those variables that are involved in interactions with other variables, the strength and degree of those interactions, as well as the identities of the other variables with which they interact. Graphical representations are used to visualize both main and interaction effects.
💡 Research Summary
The paper introduces a predictive modeling framework called “rule ensembles,” which builds regression and classification models as linear combinations of simple logical rules derived from the data. Each rule is a conjunction of a few elementary statements about the values of individual input variables (typically 2–3 conditions, such as “X1 ∈
Comments & Academic Discussion
Loading comments...
Leave a Comment