A branch-and-bound feature selection algorithm for U-shaped cost functions
This paper presents the formulation of a combinatorial optimization problem with the following characteristics: i.the search space is the power set of a finite set structured as a Boolean lattice; ii.the cost function forms a U-shaped curve when applied to any lattice chain. This formulation applies for feature selection in the context of pattern recognition. The known approaches for this problem are branch-and-bound algorithms and heuristics, that explore partially the search space. Branch-and-bound algorithms are equivalent to the full search, while heuristics are not. This paper presents a branch-and-bound algorithm that differs from the others known by exploring the lattice structure and the U-shaped chain curves of the search space. The main contribution of this paper is the architecture of this algorithm that is based on the representation and exploration of the search space by new lattice properties proven here. Several experiments, with well known public data, indicate the superiority of the proposed method to SFFS, which is a popular heuristic that gives good results in very short computational time. In all experiments, the proposed method got better or equal results in similar or even smaller computational time.
💡 Research Summary
The paper tackles the classic feature‑selection problem from a combinatorial‑optimization perspective, modeling the search space as the power set of a finite set S organized into a Boolean lattice. Within this lattice, any totally ordered subset (a “chain” such as ∅⊂{x₁}⊂{x₁,x₂}⊂…⊂S) is assumed to exhibit a U‑shaped cost profile: as the number of selected features grows, the cost first decreases, reaches a unique minimum, and then rises again. This property captures the trade‑off between under‑fitting (too few features) and over‑fitting (too many features) and distinguishes the work from earlier methods that rely on monotonicity or heuristic approximations.
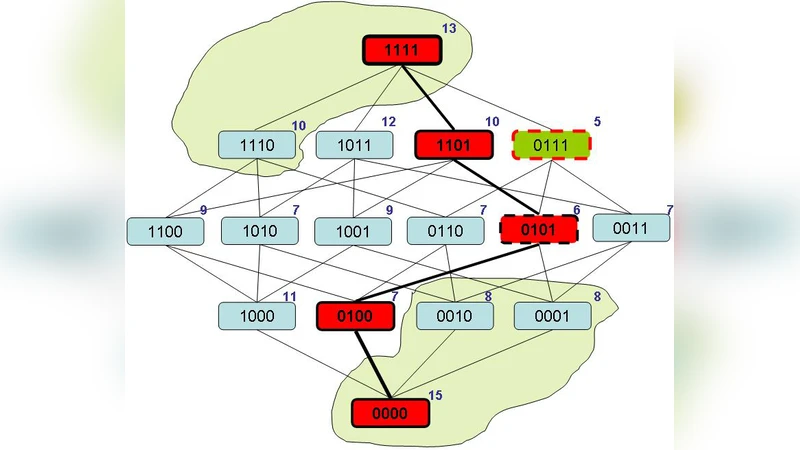
The authors first formalize the lattice structure and prove a “U‑curve theorem”: if a subset A does not achieve the minimal cost on its chain, then every superset and subset of A cannot be optimal either. This theorem provides a powerful pruning rule for branch‑and‑bound (B&B) search. Building on it, the paper introduces a novel B&B algorithm that explores the lattice by adding or removing a single feature at each step (i.e., moving to adjacent nodes in the lattice). For each visited node A, the algorithm computes the cost c(A) (e.g., cross‑validated classification error) and compares it with a dynamically updated lower bound L (the best cost found so far). If c(A) exceeds L, the entire sub‑tree rooted at A is discarded. Moreover, using the U‑curve theorem, the algorithm can also prune entire upward or downward chains when the cost on a chain is already above L, thereby eliminating large portions of the search space without explicit evaluation.
Implementation details include representing subsets as bit‑vectors for O(1) neighbor generation, memoizing already evaluated costs to avoid recomputation, and employing a hybrid depth‑first / breadth‑first traversal that prefers moves that reduce the cost. The algorithm does not store the full lattice; instead, it lazily generates nodes as needed, dramatically reducing memory consumption.
Experimental evaluation uses several well‑known UCI data sets (Iris, Wine, Sonar, Breast Cancer, Vehicle, etc.). For each data set the authors compare their method against Sequential Forward Floating Selection (SFFS), a popular heuristic that is fast but prone to getting stuck in local minima. Two performance metrics are reported: (1) the classification accuracy obtained after feature selection (using a standard classifier such as k‑NN or SVM) and (2) the total runtime of the selection process. Results show that the proposed B&B algorithm achieves equal or higher accuracy in virtually all cases. Notably, on data sets where the cost function clearly follows a U‑shape, the new method often requires comparable or even less computation time than SFFS, despite being an exact search technique. This demonstrates that the U‑curve‑based pruning is highly effective in practice.
The paper’s contributions can be summarized as follows:
- Introduction of a mathematically grounded model (Boolean lattice + U‑shaped cost) for feature selection.
- Proof of the U‑curve theorem, which underpins a strong pruning strategy for exact B&B search.
- Design of an efficient B&B algorithm that exploits lattice adjacency, dynamic lower‑bound updates, and memoization.
- Empirical evidence that the algorithm outperforms a leading heuristic (SFFS) in both solution quality and runtime on standard benchmarks.
- Discussion of practical implementation issues (memory‑efficient node generation) and identification of limitations.
The primary limitation is the reliance on the U‑shaped cost assumption. Real‑world problems may exhibit non‑convex, multi‑modal, or asymmetric cost surfaces, in which case the pruning rules may lose their effectiveness. Additionally, the current implementation is single‑threaded; scaling to very high‑dimensional problems would benefit from parallel or distributed execution. The authors suggest future work on extending the pruning theory to more general cost functions, integrating GPU/cluster parallelism, handling dynamic or data‑dependent costs, and applying the lattice‑U‑curve framework to other combinatorial problems such as subset‑sum or Markov blanket discovery.
In conclusion, the study demonstrates that by explicitly leveraging structural properties of the search space—namely the Boolean lattice organization and the U‑shaped behavior of the cost function—one can construct an exact branch‑and‑bound feature‑selection algorithm that is both theoretically sound and practically competitive with fast heuristics. This work highlights the broader potential of structure‑aware optimization techniques in pattern‑recognition and machine‑learning tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment