The Multi-Core Era - Trends and Challenges
Since the very beginning of hardware development, computer processors were invented with ever-increasing clock frequencies and sophisticated in-build optimization strategies. Due to physical limitations, this ‘free lunch’ of speedup has come to an end. The following article gives a summary and bibliography for recent trends and challenges in CMP architectures. It discusses how 40 years of parallel computing research need to be considered in the upcoming multi-core era. We argue that future research must be driven from two sides - a better expression of hardware structures, and a domain-specific understanding of software parallelism.
💡 Research Summary
**
The paper “The Multi‑Core Era – Trends and Challenges” provides a comprehensive overview of why the era of ever‑increasing CPU clock frequencies has ended and how the industry has shifted to chip‑multiprocessor (CMP) designs as the primary path to performance growth. It begins by revisiting Gregory Pfister’s 1995 maxim—“work harder, work smarter, get help”—and maps these three principles onto modern processor development: “work harder” corresponds to clock‑rate scaling, “work smarter” to micro‑architectural optimizations such as superscalar pipelines, and “get help” to the addition of multiple cores on a single die. The authors argue that, because power and thermal limits now cap clock‑rate increases, all major vendors are using the transistor budget that Moore’s law still supplies to integrate ever more execution units.
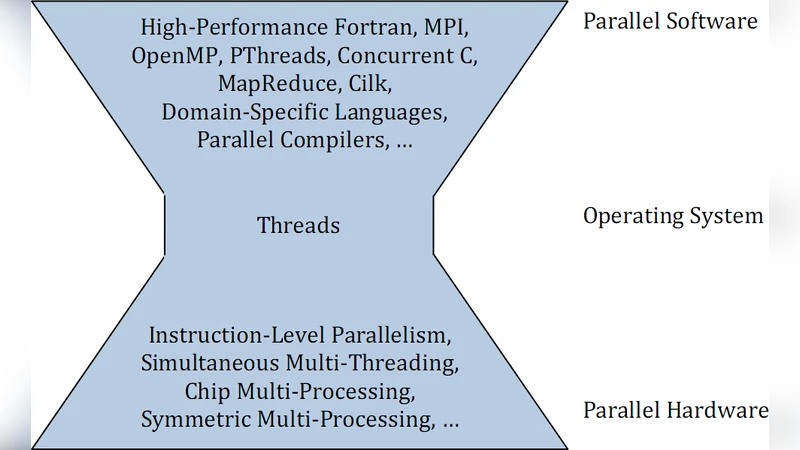
The hardware discussion is organized as a hierarchy of parallelism. At the lowest level, instruction‑level parallelism (ILP) is achieved through superscalar pipelines; above that, simultaneous multithreading (SMT, marketed as Hyper‑Threading) allows a single physical core to host multiple logical processors. A collection of such cores forms a CMP, typically with private L1 caches and a shared L2 (or higher‑level) cache. The paper distinguishes two architectural trends: homogeneous many‑core chips (e.g., Intel Xeon, AMD Opteron, the TILE64 mesh processor) that aim for thousands of relatively simple cores, and heterogeneous many‑core designs (e.g., IBM’s Cell, IBM zSeries) that combine a general‑purpose core with specialized accelerators such as vector units or I/O‑dedicated engines. The authors note that the latter enable task‑level parallelism by allowing an algorithm to select the most appropriate engine for each sub‑task.
Scalability challenges are highlighted. As core counts rise, memory bandwidth, latency, and cache‑coherency become dominant bottlenecks. The paper cites Intel’s proposal of a QoS‑aware memory hierarchy, where the OS can prioritize cache and bandwidth for critical threads, and stresses that any realistic performance model must incorporate these effects. Historical precedents such as the INMOS transputer, vector supercomputers, and massive‑parallel processing (MPP) systems are invoked to argue that the community already possesses a wealth of knowledge that should be revisited for modern many‑core chips.
On the software side, the authors contend that the “hard‑ware scalability problem” has been replaced by a “software parallelization problem.” Most developers lack formal training in parallel concepts, yet they are now expected to write multithreaded code for commodity hardware. The paper reviews classic parallel performance laws: Amdahl’s law (which caps speedup for a fixed problem size) and Gustafson’s law (which shows that larger problem sizes can recover scalability). Both remain relevant in the multi‑core era and must guide algorithm design.
The paper surveys existing parallelization support mechanisms. Automatic parallelizing compilers can extract parallel loops but struggle with side‑effects and coarse‑grained tasks, limiting their practical speedup. Operating systems provide preemptive thread scheduling and act as a “glue” between hardware parallelism and application needs, yet they cannot eliminate the programmer’s responsibility to expose parallelism. At the application level, a spectrum of models exists: traditional thread libraries (POSIX threads), language extensions (OpenMP, Cilk, Concurrent C), data‑parallel frameworks (CUDA, OpenCL), functional and reactive languages, and domain‑specific languages (SQL, MapReduce, Simulink). The authors note that most of these ultimately map to OS threads, and the choice among them remains an open research question, especially when targeting thousands of cores.
Finally, the paper proposes two research directions. First, a more realistic and generic abstraction of many‑core hardware is needed—one that captures cache hierarchies, memory latency, and mutual‑exclusion costs—to serve as a foundation for algorithm analysis, scheduling theory, and performance modeling. Existing models such as LogP, BSP, and PRAM are deemed insufficient because they either assume unlimited resources or focus solely on distributed systems. Second, domain‑specific parallelization strategies must be developed, leveraging the 40‑year legacy of parallel computing research to create tailored compilers, libraries, and runtime systems for fields such as databases, XML processing, scientific simulation, and emerging big‑data workloads.
In summary, the authors argue that the multi‑core era is not merely a hardware trend but a systemic shift that demands coordinated advances in hardware abstraction, operating‑system support, programming models, and domain‑aware parallelization techniques. Only by addressing these intertwined challenges can the full potential of thousands‑of‑core processors be realized.
Comments & Academic Discussion
Loading comments...
Leave a Comment