Social Learning Methods in Board Games
This paper discusses the effects of social learning in training of game playing agents. The training of agents in a social context instead of a self-play environment is investigated. Agents that use the reinforcement learning algorithms are trained i…
Authors: Vukosi N. Marivate, Tshilidzi Marwala
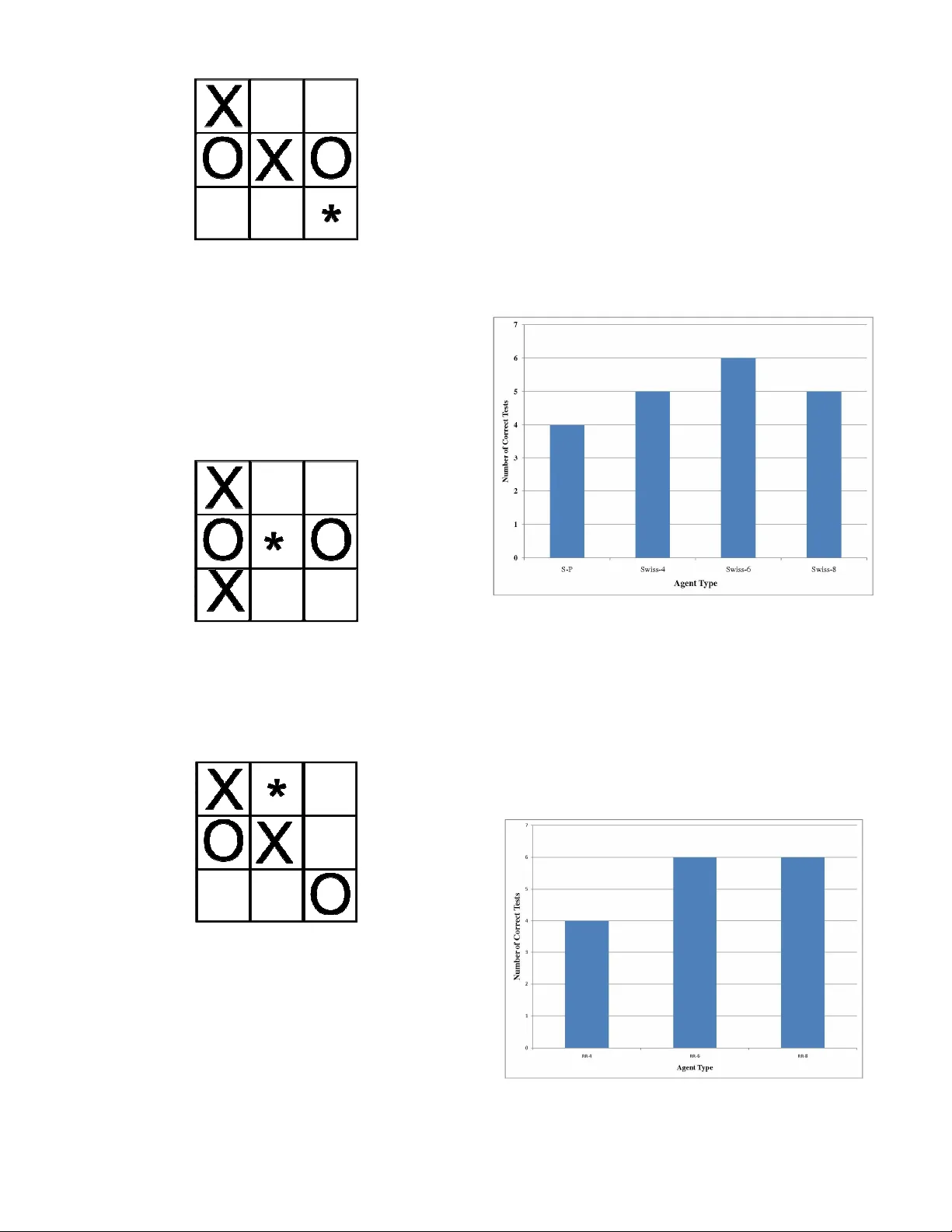
Abstract —This paper discusses the effec ts of social le arning in training o f gam e play ing agents. The traini ng of agents i n a social con text inst ead o f a self -play env ironm ent is i nvestigated. Agents that use the rei nforcement learning algorithms are trained in social sett ings. This mimics the way in which pl ayers of board games such as scrabble and chess mento r each other in their cl ubs. A Ro und Ro bin tournam ent and a mo difi ed Swiss tournam ent set ting are used f or t he trai ning. The agents trai ned using social sett ings ar e comp ared to sel f pl ay agents and result s indicat e that mo re robust agents emerge f rom the social t raining setti ng. H igher s tate s pace games can benefit from such s etti ngs as diverse se t of agents wil l have multi ple strat egies t hat increase t he chances of obtaining mo re experie nced players at the e nd of trai ning. The Social Learning trai ned age nts exhibit better playing experience than s elf play agents. The mo dified Swiss playing style spawns a larger number of better pl aying agents as the population siz e increas es. Index Term s —Social Learning, Reinforcement Learning, Board Games I. I NTRO DUCTION NTELLIG ENT agent s [1] th at play bo ar d gam es h ave bee n a fo c us in Machin e Le arn in g a nd Ar ti fic ial Int elligence (AI). Th ese a gents ar e t augh t h ow to pl ay ga mes an d lear n from either sav ed games o r b y play in g again st th emse lve s [2]. T h e pr ob l em th at ar i ses w i th a gents t h at lear n from play i n g aga in st th emse lve s is th at th ey ha ve a probab il ity of not b ein g able to captur e a ll th e dy na mics of a game or v a r iat ions i n o pponent’s str ategy . Th us self -pla y agents h a ve a ten dency to perfo r m poo rl y aga in st o pponen ts th at t hey h ave not co me across th eir stra tegy b ef ore. To fix th is, r ese ar ch ers h a ve in tr oduce d th e abilit y t o save a lar ge database of pr evio usly pl ay ed games [2, 3]. Th i s means t h at agents h ave dat abase s of saved games tha t th ey can acce ss. Th is results in lar ge memo ry co n sidera tions as gam es in crease th eir sta te sizes. Th is a lso in creases computationa l co mpl exity as search es w ith in th e database s are nee ded t o find the bes t mov es. Reinfo r cement lear n in g [4] h as be en used extensively in mult iple domain s. On e such domain ha s be en in deve lopin g ga me pla y in g agen ts. A pr ob l em th a t V. N. Marivate is with the Comp u tational Inte lligen ce Res earch Group of t he Sch ool of Elect rical a nd Inf ormation Engin eerin g, Private Bag 3 , Uni ve rsity of the Witw a ters rand, Johann esburg, Wits , 205 0. (phone : + 27 72 329 21 26 ; f a x: +27 86 51 49 542 ; e- mail: vukos i.marivate @ie ee.o rg). T. Marw ala is with the Com putation a l Intellig ence Res earch Group of the Sch ool of Elect rical a nd Inf ormation Engin eerin g, Private Bag 3 , Uni ve rsity of the Witw a ters rand, Johann esb u rg, Wits , 2 05 0. (e -mail: t.m arwala@ee .wits .ac.za). ar ises with self -pl ay an d r ein fo r cement lear n in g is the in ability to m ode l l ar ge state bo ar d gam es such a s Go [2]. To deal with th is prob l em th i s pa per in ve sti gates t he tr ain i n g o f agents in so cial settings as o ppos ed to self play and mo ni tors th e ef fe cts t h is h as on th e ov erall performan ce of th e diff er ent agents created. T hi s paper fo cuses on impr ov i n g th e perfo r ma n ce of agen ts usin g a soc i al settin g. Th is is diffe r ent from So cial search /optimiz ation m ethods suc h as Par ticle Sw ar m Opti miz ation [5] or Memetic Algorith ms [6]. T he game playing agen ts a r e co mpetit ive , t h ey ar e only tr y in g t o maxim ize th eir ow n perfo r man ce an d h ave n o glob a l go al. Meanin g t h ey ar e h ave n o explicit kn ow ledge of h ow we ll th e w h ole so cial gr oup is perfo rm in g. Th e paper f i r st pr ese nt s th e background in Section II. Th en th e meth odo logy i s co ve r ed in Sec t ion III. Mo delin g of the game an d t esting is co vered i n Sec tion IV an d V r espe ctively . Sec ti on VI pr ese n t s th e r esults an d th en the pa per is co n cluded in Sectio n VII. II. B A CKGROUND A. Artif ici al Int ell igenc e i n Games Makin g co mputers t h at h a ve t h e ability t o play games [2] again st hum an o pponent s h as be en a ch all enge sin ce th e be gin n in g of r ese ar ch in to Ar ti fic i al In telligen ce in machi n es. Th r ough th e y ear s th ere h ave be en ma chin es th a t h a ve b ee n taugh t to l earn an d pla y a mult itude of games. Gam es tha t a r e curr entl y master ed by ma chin es, such th at th ey cann ot b e be at en by h uma ns, th is in cludes; chess , backgammon, Oth ello an d ch ec kers [2] . Chal lenges, an d th eir so lut ions, th at ar ise in mode llin g o f gam es can b e exten ded t o th e real w o rl d. Prob l ems asso ciated w i th games ar e easie r t o mo del sin ce th ey h ave rules th at are bo un d an d h ave eve n t c onstr ai n ts. Th is is in co n tr ast to r eal w orld prob l ems where r ules can chan ge and th er e is a h igh lev el of uncert ain ty . Th e f a ct th at games ar e simpl er to model, do es n ot imply tha t th ey can n ot be usef ul in so lving r eal w orl d pr ob lems. Th e skills lear n t by research ers in th e fie ld of AI in gam es, a r e helpin g th em find new or im pr ov ed solutions in m ultit udes of prob lems in other real ms. In Re in fo r cement Learn in g [4][7] mos t agen ts lear n to pla y games b y play in g ga mes aga in st th emselv es, termed self -pla y [2][8], fo r a l ar ge amount of i tera tions. T h us the agents lear n from th e experiences they cr eate. B. Rei nforcement Learning An in telli gent agent i s def i n ed [1] as a c omputer sy stem/progra m th at r eside s in some en vironmen t an d is Social L earning Methods in Board Ga mes V ukosi N. Ma rivate and T shi lid zi Marwala I allow ed to perfo r m a ctions in tha t e n vir onment . H uma ns lear n by i nt eractin g w ith each other . Le ssons ar e lear n ed from be in g r ew ar ded or puni shed afte r perfo r m in g an action. Th is is diffe r ent f r om supe rvised lear ni n g [3]. In supervise d lear ni n g, a learn i ng al gorith m is give n test cases t ha t ha ve in puts an d th e co r r espo n di ng co r r ec t outputs. Th is fo r example, c a n be in th e fo rm o f function appr oximation as show n i n equation (1). ) ( x f y = (1) Where x can b e a ve ctor of multipl e in puts an d y is a ve ctor th at i s compo sed of mul tipl e o utput s. Th us th e learn in g algorit h m tr ies to appr oximate th e function f(.). Re in fo r cement learn in g can be categoriz ed as un supervise d lear ni n g. An a gent i s placed in an environmen t. It perfo r ms actions i n t ha t envir onment a n d perce ive s th e ef fe cts of th e actions in th at environmen t t h rough it s senso r s/r ece ptors. T h e agent also r ece ive s a r ew a r d/pun ish ment given th e ch an ge th e action h as made i n th e envir onment . Th is r ew ar d can b e extrin sic (from th e environm ent) o r in tr in sic (from within th e agent) [9]. Th is is il lustr ated i n Figur e 1. Figure 1 . Rei nf orce me nt Learn ing Framew ork In a gen eral r ein fo r ce ment lear n in g pr ob lem one deals with a Mar kov Decisio n Pr ob lem [4] (MDP). An MDP is made up of a n umber of enti ties. • S - set of states of t h e environmen t • s - curr ent stat e of t he en vironmen t • s’ - Th e n ext stat e • A - set of actions t h at can be taken by th e agen t • a - curr en t a ction ch os en by th e agen t • R – Rew ar d given (R(s ) , (R(s,a) , R(s,a,s’)) • ) , | ' ( a s s P -Tr an siti onal Prob a bility Th e tra n sitiona l pr ob abilit y is th e prob a bility o f mov in g in to anoth er stat e ( s’ ) giv en an action ( a ) an d a s t ate ( s ). Give n th e abo ve in fo r m ati on, a n agent can ma ke a decisio n on w h ich actions a re bes t to take in a spe cif i c state. Th is i s termed t he policy ( π ) of th e agent. It is a m appin g of a stat e to a specif ic a ction ( a= π (s ) ). Th e tr an siti onal prob a bilities of a n environmen t ar e n ot norma lly pr ov i ded o r kn ow n . Th us a chall enge in r einfo rcement lear n in g is mode l lin g a n environmen ts dy n ami cs with in th e a gent. T o do th i s th e co n cept of the v a lue o f a sta te is i nt r oduc ed. T h is is done th r ough th e in tr oduc t ion of Value Function an d Action Value functions. Th r ough t h ese functions one can evaluate t h e policy th at th e agent i s t akin g. The value function is defined in (2) as: ∑ ∞ = + + = = 0 0 1 ] | [ ) ( k k t k s s r E s V γ π π (2) Th is is th e expe cted v a lue ( E ) o f th e s ummat ion o f the disco un ted ( γ ) rew ar d ( r ) of all possib le f ut ur e states gi ve n th at th e a gent is exec uti n g a policy π given t h at we a re star tin g a t th e curr en t sta te. T he policy ( π ) i s th e mappin gs of state to actions. Th e action-value function i s ∑ ∞ = + + = = = 0 0 0 1 ] , | [ ) , ( k k t k a a s s r E a s Q γ π π (3) Where Q(s,a) takes in to acco un t not onl y be gin n i ng at th e th e curr en t state b ut al so th e c urr en t action. T h e maxim iza tion o f (2) a n d (3) by car r y in g out a n optimal policy π * w i ll r esult i n h igh er r ew ar ds in t h e en d. To fin d th e policy th at maxim ises t he value function or a ction-value f un ction we use t he Be ll man Optima lit y equations [4]. T o l earn in rein fo r cement l earn i ng from a sy stem without th e co m plete mode l (Mo del free) of th e sy stem then th e agent needs to lear n t hr ough experien ce . Th e agent th us h as to go t hr ough in tera ctions an d find an optimal policy t ha t o pt imi zes (2) or (3). C. Learning Al gorithm and A cti on Sel ect ion Th e learn in g a lgorith m used i n t hi s paper i s th e T D- Lambda Algori th m [4]. The algorit hm is a pplied to action value functions as in (3). T he a lgorit hm al low s th e agen ts in iti all y t o explore a nd as th ey pl ay more ga mes star t explo i tin g more an d explorin g less. In th is paper, a ction value functions a re use d w i th a t able str ucture. Fun ction appr oximation is n ot used an d th e too lbo x used fo r mode lin g an d implement in g th e experimen ts i s th e Re in fo r cement Le a r n in g toolb ox built by Gerh ar d Neuman n [10]. Th e gen eral ised form o f a termin al dif ference al gorith m co mbin es bo otstrappi n g like dy na mic pr ogramm in g methods [4] an d sampli ng l ike Monte-Car lo meth ods. The algorit h m i s show n in Figur e 2. Figure 2 . TD-Lamb da Algo rithm e(s) ab ov e is t he e l igibilit y trace [11] of a cert ain state. Th us i f a certai n sta te repeats i tself i ts update is t aken i nt o acco un t with a h igh er importa n ce dependin g on h ow r ece n t th e pr ev ious oc curr en ce was. Fo r choo sin g t h e actions a n d a llow in g explorati on a n d explo i tat ion actions we r e chos en usin g an d epsilon gr ee dy distr ibution which can be writt en a s: = + − = ∈ else A a s Q a if A a s P A a i i , ) ' , ( m ax a rg , 1 ) , ( ' ε ε ε (4) Th e agent ch oo ses a r an dom action with pr ob abilit y ε an d takes a greedy a ction w it h prob a bility 1 – ε . Th is ma kes sur e th at th e agents in itia lly ar e more li kely to explo r e but as m ore an d more ga mes a r e play ed ε decreases an d t hus t h e agents star t to t h en exploit m ore by using th e kn ow ledge t h at t h ey ha ve gain ed th r ough play in g th e ga mes. D. Soc ial Learning As r einfo r ce m ent lear n in g deve lops f r om mode l in g h ow hum an s deve lop in th eir earl y stages of l ife an oth er co mpl imen tar y th eo r y can b e used in co n junction w it h rein fo r cement lear ni n g. Humans seldo m lear n only by th emse lve s. T h ey li ve in a soc i ety a n d th us ob ser ve what others do. T h is is termed so cial learn i ng. In gamin g circles th is i s ev en m ore distin ct. Play ers o f suc h bo ar d games such as chess, Scrabb l e an d checke r s mentor each oth er in th eir club s [ 14]. In soc i al l earn in g t h ere ar e a n umber of import an t fac t ors th a t a b ein g must ha ve in order to be a ble t o lear n . Th e be in g or i n th is case agen t m ust be able to [12]: • Pay att enti on to th e what is being ob serve d • R emembe r th e ob servations • B e able to replicate t h e b eh avior • B e motivated to demo n str at e w h a t t h ey h ave lear n t Th us lear n in g by ob serving in vo lve s fo ur pr oc esse s: atten tion, retent ion, pr oduc t ion an d mo t ivation. In rein fo r cement lear n in g thi s can be exte n ded t o b ein g able to play a game and o bse r ve stat e t r an siti o ns, rememb er w h a t actions h ave be en ta ken, t rying a diff eren t action after previo us one failed an d th en being r ew a rded if it leads t o a termi n al stat e. Fur th er an agen t th en ob serves what a n oppo n ent do es. Vy go tsky [13] discus ses t h e conce pt o f t h e more kn ow ledge able oth er. Th is co n cept ta kes in to acco un t th at in a soc ial settin g an agent w ould l earn more from an other a gent who has mo re e xper ience or is at the s ame lev el. Th i s can a lso be obs er ve d in chess club s where membe r s ar e pa ir ed to tr ain w ith str onger pla y ers or peers. By in tr oduc i n g other agen ts as o pponen ts in th e l earn i ng stage o n e in tr oduce s a n on-stat ionar y pl ay in g en vironmen t [14]. If f or example t h e oppo n en t i s a l ogic base d in telligen ce co mput er pr ogram , a rein fo r ceme nt l earn i ng agent w ould lear n a stra tegy or po licy th at wo uld optimall y b eat the logic oppo n ent [15]. Th us sti mula tin g a soc ia l settin g is n eeded. Th is wo uld th en i ncr ease th e pr ob ability o f cr eatin g agents th at n ot onl y just kn ow h ow to b eat a specif ic oppo n ent s stra tegy but h a s a broader kn ow ledge of a state space . Th i s is discuss ed furt her i n th e pr oc eeding sec t ions. III. M ETHODO LOGY H um an s pl ay an d lear n bo ar d gam es in gr oups . Th is co mm un ity o f pla y ers im par ts kn ow l edge o n eac h o t h er. If one loo ks at co mm uni ties of chess or Sc r a bb le [16] pl ay er s one can see t h at ve ry expe r i enced play er s m entor we a ker play er s. T o sim ulate a soc ial lear n in g environmen t such a s th is, multi ple agent s n ee d be cr eated. In t h is paper each agent is gi ve n its ow n i dentit y in th at t hey h ave di ff erent in iti ali zat ion pa r ameters. Th e agen ts h ave th e same l earn i n g algorit h m but h ave diff er ent in i tial iza tion options. Th is is show n i n Ta ble 1. Two tr ai n in g co n figur ati ons ar e used in tr ain i n g th e agen ts in t h e so cial settin g. The t w o meth ods a r e derived from tourn amen t sty les. A modifie d Sw i ss [17] a n d a Ro un d Ro bin sy stem ar e used an d c ompar ed. In t he modif i ed Sw iss co n figura tion, agen ts ar e pai r ed up to play o n e round o f a game which is a full episode . When th e ga me is fini shed th er e is eith er a winn er or a l os er or th ere is a dr a w . A t ourn amen t like str uctur e was utili sed fo r t h e agent s to pl ay in . T h e structur e is sh ow n i n Figur e 3. TABLE I A G E NT I DENT ITI ES Paramet er Range Learni ng Rate 0.2 – 0 .3 Disc ount Fact or 0.95 - 0.99 Lamda 0.9-1.0 Figure 3 Tournamen t Learnin g F ramew ork Th e agen ts ar e first i ni tia liz ed an d pla ce d i n a n in it ial population. In th e first i tera tion t h ey ar e ar bitr ar ily put in two sub -classes (Win n in g Agents an d Lo sin g A gents). In th e sec ond itera tion an d fo r th e r est of th e game t he agents play games again st eac h other. A winn in g agent is pit ted agai nst a losing a gent. Afte r a ga me/episo de th e winn er is pla ce d in th e w i n ner agen t li st an d t he l os i n g agen t i n th e losing a gent list, th us a dir ect simulat ion of a m entor an d a lear ner . At th e end of a pl ay i ng round th e agent s will be in two groups. A num be r of r ounds ar e play ed a n d th e pr oc ess of pai r in g losers an d winn er s r epeats un t il th e maximum num be r of rounds is reach ed. In th i s co n figura tion th ere is a la rge fo cus on getti n g agents to b e pair ed with play er s th at h ave b etter experien ce . In a r ound r ob in settin g each agent play s a gain st th e oth er. Th ere is n o split tin g o f th e gr oup t o winn ers a n d lose r s. Afte r a r ound of play i n g th e pla y ers a re t hen pit ted agai n st th e n ext play er . Th is i s done un til t he m axim um number of games is play ed. Th is h as l ess of a fo cus on h avin g a m ore know l edge a ble other or a peer as a n oppo n ent . Another agen t w a s created w h ich is th e self -pla y agen t. Th is agen t l earn s by only play i n g again st itself. It play s a mov e a s o n e play er an d th en play s a n other mov e as th e other play er . Th is a gent was created so as t o be able to benchma r k h ow we ll t h e soc ia l agents fair agai n st co nventiona l self -pla y l earn in g. IV. M ODELLING T HE G A ME AND L EARNING A. Tic Tac Toe Tic-Tac-Toe [18] is a 3 x 3 b oard ga me. Two play er s place piece s on th e bo a r d tr ying t o c o nn ect th r ee o f th eir ow n piece s in a r ow . Figur e 4 ill ustra tes the playe r with t he noughts def eatin g th e playe r with th e cr os ses. Figure 4 . Tic Tac Toe Bo a rd If two great pl ay er s play a game of Tic-Tac-Toe it should alway s end with a dra w [2]. T h e game h as bee n mode led w i th rein fo r cement lear n in g in th e past [5]. It h as be en reco r ded th at agen ts t ake 50000 learn i n g episode s [19] to be able t o play a t a beginn er l ev el. In th is experi ment th is is th e a mount of it erat ions used fo r t h e tr ain in g of t h e agent s. B. The Game M odel To mode l the game fo r r ein fo r ce m ent lear n in g th e game w a s r epresented b y 10 state v ar iables. Nin e of th e var iables can h ave 3 diff erent values which r epr ese n t t h e pl aces o n t h e bo ar d. E ach pla ce on th e bo a r d can be empty or h ave a nought or cr os s. Th e ten th sta te is th e curr ent play er who is suppo sed to play . T h e mode l al so keeps tr ack of which actions ar e availa ble to an agent i n a ce r t ain stat e. Th us a n illegal mov e such a s placin g a piece on a b oard a r ea th at alr eady h a s a piece is not po ssible . W h en an agent w in s a ga me it is rewarded with a r ew ar d of 1. 0. When th e agen t lose s it th en gets a r ew ar d of -1.0. When th ere is a dra w , th e agent gets a reward of 0.0. For all other game sta tes t h at a r e n ot term in al th e r ew ar d i s 0.0. C. Learning Th e games ar e m an aged by a game contr oller. Th e co n tr oller a llocates w h o h a s to pla y n ext an d al so kee ps t r ack of gam e statisti cs suc h as w i n s, test r esults an d how man y times each agen t h as pl ay ed games. It a lso matches winn ers an d l os er s a nd t h us im plements t h e so cial fra mew orks desc r ibed in sec ti on I II. Th e a gents ar e i ni tia liz ed with diff eren t l earn i ng param eters. Th us t h e agents play agai n st non-sta tiona r y oppo n en ts. T h is sti mula tes th e emergen ce of more rob ust agents. Th e opponents policies ar e al so cha ngi n g an d th us a lear n er will h ave to adjust i ts policy t o be a policy th at can pla y a gain st more th an one stationa r y oppo n en t. V. T ESTING A. Board Test Two tests we r e se tup fo r th e agen ts. T he first test f or th e agents w a s a n asse ssment o n h ow w ell th e agents perfo r m at tr y in g to pick corr ec t a ctions in given test stat es. Th e Tic-Tac-Toe b oar d is setup w i th pi ec es alr eady o n it. Th er e i s only one corr ec t mov e t ha t can be m ade. T her e w er e a t otal of 10 test bo a r ds w it h di ff erent lev els of diff iculty. T he agent s ar e gi ve n one t r y at e ach bo a r d. Some bo a rds h a ve to r each a termi n al stat e (end of game) w h i le i n o t h ers the agent h as to choo se an a ction th at w i ll result in f orcin g a dra w in the game. T her e ar e 5 easy b oards, 2 in ter mediate bo ar ds an d 3 ha r d bo a r ds. T he easy bo ar ds test if th e agen t can notice states th at will ma ke th em win (Figur e 5). Figure 5 . Cros s to Play (Easy ) Th ese ar e 1 m ov e to win b oar ds. Th ey ar e r elatively easy an d test h ow th e a gents tr y t o choo se actions th at w ill maxim um r ew ar d in th eir n ext a ction c hoice. Th e in term ediate bo ar ds ar e def ensive bo a r ds wher e t hey test h ow w ell an agen t can b l oc k a win by th e other oppo n ent , w h ich means a loss fo r th e agen t, or fo r ce a dr aw. Th ese t ests sh ow th at th e a gent is tr y in g to avo id los i n g o r ge t tin g a low er retur n . An example i s ill ustra ted in Figur e 6. Figure 6 . Cros s to Play (Inte rmed iate) Th e diff icult bo ar ds test h ow an agent can force a win h is future mov e an d not th e n ext mov e. Th ese ar e t r ickier but t est how th e agent is tr y i n g to maxi miz e i ts f ut ur e r etur n s. Th e bo ar d i s show n in Figur e 7. Figure 7 . Cros s to move (Hard) B. Play Test Th e sec ond test th e agen ts t ake is takin g par t in a league. All of th e agent s ar e all ow ed t o pla y with all th e other agen ts. Th e wins, losse s an d dr a w s ar e r eco r ded. Th is is used t o find w h i ch of th e agen ts ar e t h e str ongest. 5000 gam es a re pla y ed by th e agent s again st each other. Th is was a pplied to t h e bes t modif i ed Sw iss agen ts a nd Self -Pla y a gents. C. Testi ng Me thod Th e agent s we r e built w i th di ff erent populati on siz es. Th e first siz e is 4, t h en 6 an d th en 8. E ach of t h ese w a s t este d 5 diff eren t tim es with the bo a rd test (meani n g th ey h ave be en tr ain ed diffe r ent ly 5 times) a n d t hen 5 ti mes w ith th e pla y test. Th e r esults ar e pr ese nt ed in t h e f ollow in g sec t ion. VI. R ESU LT S A. Board Test Result s Th e tests we r e carr ied th r ough w it h diff eren t agent populations. Th e r esults of th e tests fo r th e modifie d Swiss co n figura tion ar e show n be low in Figur e 8. Figure 8 . Board test res u lts SP vs. S wiss Self Play Th e results sh ow t ha t th e Self -Play(S -P) a gent gets 4 move s co r r ect w h il e th e be st Sw iss soc ial agent i n th e 4 po pul ati on (SO4) gets 5 whil e th e one i n th e 6 (SO6) gets 6 corr ec t . Th is impli es t ha t t h e Self play agent pla y s at a be gi n n er l ev el whil e th e SO6 i s play i n g at an in ter mediate leve l co m par ed to th e other agent s. None of t h e agents ar e advanced. Th e other tes t w as w i th th e Ro un d R obin Co n figur ati on. Th e r esults ar e in sh ow n in Figur e 9. Figure 9 . Round Robin A ge nt P erfo rmance Another o bs er vation f r om th e soc i al agent s i s th at a s more an d more agen ts (>8) a r e use d in th e population ther e is a n in crease in th e n umbe r of in term ediate agents in one genera tion. T h is is m ore e vide n t in th e Sw iss tourn amen t setting as oppo sed to th e Ro un d Ro bin configura tion. Bo t h co n figura tions w er e tested w i th 16 a nd 32 agent siz ed populations. When th e populations ar e in cr ease d with t h e modif i ed Sw iss c onfigur ati on m ore th an o n e i nt ermediat e agent e mer ges. In some s t ages up to 6 in term ediate agen ts emerge. With th e Ro un d R ob in co n figurat ion 2 in ter mediate play i n g agen ts h ave eme r ged. By i n tr oduc i n g mul tipl e diff erent agen ts a s oppo n ents in th e tr ai n in g ph ases, one h as b een able t o create agents th at ar e superior t o th e S-P agent. B. Play Test Result s for Modi fied Sw iss Th e play test w a s co n ducted on th e Sw i ss Configura tion so cial agen ts. A sample of th e bo ar d test r esults is sh ow n i n Table 2. T ABLE 2 A V E RAGE S WI SS S OCI AL AGENT P LA Y T EST All of t he agen ts play ed 5000 gam es aga in st each oth er. In th e a bo ve tab l e th ere ar e 4 soc i al agents a n d one self -pl ay agent. The s elf play agent is t h e bes t age nt that w as ke pt duri n g in it ial izat ion an d t r ain i ng o f th e a gents. Thus t he be st agent th at per fo r med in th e bo ar d tests is used. In th e abo ve table t h e S-P agent wo n 3041 games aga in st SO, w hi le SO1 w on 3084 games a gain st. Th us t h e diff eren ce is 43 gam es more tha t w ere w on b y SO 1. This indi cates t ha t w h en an agent star ts a game fir st they are more likely to win. T he agents on a v erage in th e abo ve configura tion ar e w in n in g ov er 60 % of t he ga mes t h ey star t fir st. Th is sh ow s th e agents still ha ve w eakn esse s in defe n di ng. Th is i s expec t ed as th e agents ar e a ll play in g a t a ve ry lo w lev el. Th e soc i al agent s on ave r a ge b eat th e self-play agen ts 50 t imes or m ore. VII. C ON CLUS ION Th e agents all play th e ga me at b egin n er lev el. Thi s is in dicated by h ow th ey perform at th e bo a r d test. All of th e agents far e v ery we l l on the easy bo ar ds but str uggle on th e in term ediate ones an d th e di ff icult ones. T her e a r e a n umber of in ter mediate a gents th at ar e created in th e soc ia l se t tin gs. Th us w i th out in creasin g th e n umber of tr ain i n g cy cles , but by in tr oduc i n g n on-stati onar y oppo n ent s in so cial settin gs th e agent’ s pe rforman ce have bee n impr ov ed. T h e lar ger t he population sizes th e more li kely t h e number of superior agents. In th i s paper a sma ll n umbe r w a s used w i th po sit ive results a n d it is expe cted t ha t w ith lar ge po pul ati on sizes th e agents will have be t ter perfo rm an ce in creases. Th is w ould be a mimi c of r eal w orl d po pulati ons of play ers w her e y ou ha ve th ous an ds of play er s in an y sport. In th e pl ay tests th e be gi n ner leve l of th e agent s is f urt h er show n a s th ey al l h ave h i gher cha n ce s of winn i ng if th ey star t th e ga me f ir st. Th e soc ial agent s have m ade it poss i ble to create agents that are superior to th e be st s elf-play a gents. Th is is a po sitive r esult an d merit s th e pote n t ial fo r t h e use of so cial meth ods in agen t l earn i ng. A CK N OWLEDGMENT V. N. Mar ivate th an ks Simon Jagoe fo r h is assistan ce with setting up t h e e n vir onment s as w ell as Gerh ar d Ne uman n w i th t h e assistan ce with th e setup of t he t oo lbo xes. R E FERENCES [1] M . J. Woold ridge , Introd uction to Multiage nt Sy stems. New York, NY, US A: Joh n Wi ley & So ns , Inc. , 2002 , [2] J. Sc haeff er, " A Gamut of Games ," AI Magazine , vo l. 22 , pp . 29 -46, 200 1. [3] S . Ko tsiantis , I. Zaharakis and P. Pinte la s, "Machi ne learning : a revie w of clas sif icatio n a nd comb ining tech niq u es ," Artif. Intell. Re v., vol. 26 , pp. 159 -190, 11 . 200 6. [4] R. S. Sutton and A. G. Barto, Reinfo rce men t Lea rning : An In trod uctio n. ,1st e d.Camb ridg e, Mass.: MIT Pres s, 1998, pp. 322. [5] J. K enne dy and R. Eb erh a rt, " Particl e sw arm op timiz ation, " i n Neural Networks, 1 995 . Procee ding s., IEEE In terna tiona l Co nfere nce o n, pp. 194 2-194 8, 19 95 . [6] P . M oscato , " Meme tic algo rithm s: a sho rt intro duction ," Mcg raw-Hill'S Adva nce d Top ics in Comp uter Scien ce S eries, pp. 219 -234, 19 99 . [7] L . Kael blin g, M. Littman and A. Moore , "Re info rce ment Le a rnin g: A Survey ," Jo ur nal of Artificial Intellige nc e Re sea rch, vol . 4, pp. 237 -285, 199 6. [8] E . H urwitz , Multi-Agen t Mode lling us ing In telligen t Age nts in Comp etative G ame s. J ohan ne sb u rg, South Afri ca: M.Sc. T hes is, Un ivers ity of the Witw atersrand , 20 07 , [9] A . Sto ut, G. K onidaris and A . Barto, "In trinsic ally mo tivated rein forc eme nt learni ng : A prom isi ng fram ework for de velo pmen ta l rob ot learning ," in P r oce ed ings o f the AAAI Spring Symp os ium on Deve lopme nta l Robotics , 200 5, [10] G. Neumann , "Rein forc emen t Learnin g Toolb ox," url: http ://ww w.igi .tugraz.at/ri l- toolbo x/gen eral/ove rview .html , last a cc ess ed 29 August 2008 . [11] R. S. Sutton, Reinfo rceme nt Lea rning . Bos ton: Kluwe r Ac a dem ic Publis hers , 19 92 , pp . 17 1. [12] A . Bandura, Soc ial Learnin g Theo ry. Engle woo d Clif fs , NJ: Pre ntice Ha ll, 198 6, [13] L. S . Vyg ots k y, The De velo pme nt o f Hig her Psycho logic al Proce ss. Cambrid ge, M a ss .: Harvard U nivers ity Pre ss, 1 97 8, [14] T. Sandh olm and R. H. Crites , "On multiage nt Q- learning in a s emi- co mp etitive dom ain," in Procee ding s of the Worksho p o n Adap tion a nd Learn ing in Multi-Agen t Syste ms, 199 6, pp. 1 91 -205-205 . [15] P ieter, Jan ’t Hoen , K. Tu yls , L. Panait, S. Luke and J . La Po utré, "An ove rview of coop erative a nd co mpe titiv e multiage nt learn ing ," in L e arn ing and Ada ption in Multi-Age nt Sy stems , v ol. 38 98 /200 6, A no nym ous Berlin / Heid elb erg: S prin ger, 2006 , pp . 1-46. [16] E. Ok ulicz, W. Vi alle and I. Ve renikina, "T he Devel opm ent of Exp ertise Withi n a Co mmunity of Practi ce of Sc ra bble Playe rs," Learnin g a nd Soc io-Cu ltural The ory : Exp loring Mode rn V y go tskian P ers pec tives Intern ation al W orks ho p, vol . 1, 20 07 . [17] T. Just and D. Bu rg, U.S. Ch ess Federa tion's Official Rules of Ches s. McK ay, 200 3, [18] O. Cybe r, "Tic T ac T oe ," " T ic Ta c Toe, " url: http ://ww w.cy beroc u lus.c om/tic -tac- toe. asp, last acc ess ed 30 June 2008 . [19] H. Manne n, "L earning to play che ss using re info rcem en t le ar nin g w ith database game s, " 20 03 .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment