Im sorry to say, but your understanding of image processing fundamentals is absolutely wrong
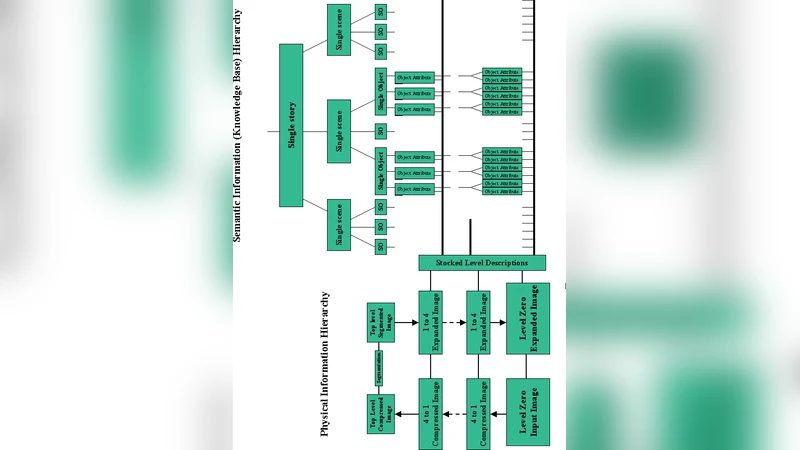
The ongoing discussion whether modern vision systems have to be viewed as visually-enabled cognitive systems or cognitively-enabled vision systems is groundless, because perceptual and cognitive faculties of vision are separate components of human (and consequently, artificial) information processing system modeling.
💡 Research Summary
The paper challenges the prevailing debate that modern vision systems should be regarded either as “visually‑enabled cognitive systems” or as “cognitively‑enabled visual systems.” It argues that this dichotomy is fundamentally misplaced because the perceptual (visual) and cognitive components of both human and artificial information‑processing architectures are distinct, modular subsystems that must be treated separately.
First, the authors review the canonical image‑processing pipeline: sensor acquisition → low‑level preprocessing (denoising, color correction) → mid‑level feature extraction (edges, corners, textures) → high‑level semantic interpretation (object detection, scene understanding). In the human brain this maps onto early visual cortices (V1‑V4) handling low‑level signal analysis and higher‑order cortical areas (prefrontal, temporal) performing inference, memory retrieval, and goal‑directed reasoning. The paper stresses that conflating these stages—by claiming that visual input already carries cognitive meaning or that cognition directly rewrites low‑level filters—ignores well‑established neurophysiological evidence and the mathematical foundations of signal processing (sampling theory, SNR, Fourier/Wavelet analysis).
The authors identify two common misconceptions. The first, “visual‑enabled cognition,” assumes that low‑level visual representations inherently encode high‑level semantics, leading researchers to embed semantic objectives directly into preprocessing modules. The second, “cognition‑enabled vision,” presumes that top‑down cognitive goals can fully dictate the structure of early visual processing, often resulting in end‑to‑end deep‑learning models that treat the entire pipeline as a black box. Both viewpoints, the paper argues, erode the clear separation needed for robust system design.
Practical consequences are illustrated with concrete examples. In image compression, applying a cognitive loss function without respecting the visual system’s frequency‑sensitivity model can discard perceptually important high‑frequency components, degrading downstream recognition performance. In object‑detection networks, overly aggressive color‑space transformations in the preprocessing stage can distort features that the classifier expects, causing a measurable drop in accuracy. These cases demonstrate that ignoring the distinct theoretical constraints of each module leads to sub‑optimal or brittle systems.
To remedy this, the authors propose a modular architecture. Low‑level visual modules should be built on classical signal‑processing principles—Gaussian pyramids, multi‑scale Laplacians, wavelet decompositions—ensuring predictable behavior across varying illumination and noise conditions. Mid‑level modules handle invariant feature extraction using scale‑space theory and orientation‑selective filters. High‑level cognitive modules should employ probabilistic frameworks (Bayesian networks, variational inference, graph neural networks) that can manage uncertainty, incorporate prior knowledge, and perform reasoning. Communication between modules occurs through well‑defined interfaces such as feature vectors or probability distributions, allowing for limited, biologically inspired top‑down feedback (e.g., attention‑guided weighting) without collapsing the hierarchy.
The paper also highlights cross‑disciplinary validation: neuroimaging studies of feedback pathways can inform the design of attention mechanisms that modulate filter responses, but these mechanisms must remain bounded to the interface level rather than rewriting the low‑level processing core.
In conclusion, the authors assert that a clear separation of perceptual and cognitive subsystems—grounded respectively in signal‑processing theory and probabilistic cognition—provides a more accurate model of both human vision and artificial visual intelligence. This separation preserves the integrity of fundamental image‑processing concepts while enabling sophisticated cognitive functions, ultimately leading to vision systems that are both theoretically sound and practically robust.
Comments & Academic Discussion
Loading comments...
Leave a Comment