Robust Near-Isometric Matching via Structured Learning of Graphical Models
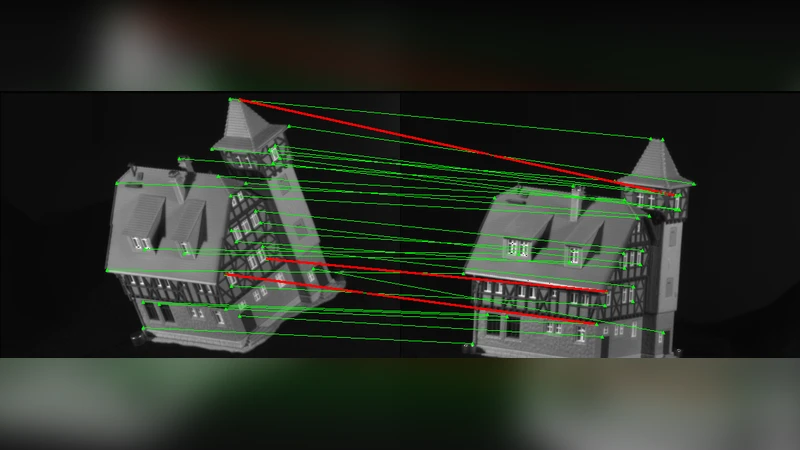
Models for near-rigid shape matching are typically based on distance-related features, in order to infer matches that are consistent with the isometric assumption. However, real shapes from image datasets, even when expected to be related by “almost isometric” transformations, are actually subject not only to noise but also, to some limited degree, to variations in appearance and scale. In this paper, we introduce a graphical model that parameterises appearance, distance, and angle features and we learn all of the involved parameters via structured prediction. The outcome is a model for near-rigid shape matching which is robust in the sense that it is able to capture the possibly limited but still important scale and appearance variations. Our experimental results reveal substantial improvements upon recent successful models, while maintaining similar running times.
💡 Research Summary
**
The paper addresses the problem of near‑isometric shape matching, a core task in computer vision and graphics where two shapes are assumed to be related by a transformation that preserves distances up to small deformations. Traditional approaches rely almost exclusively on distance‑based features, which work well under the strict isometry assumption but break down when real‑world data exhibit noise, limited scale changes, and appearance variations caused by illumination, texture, or partial occlusion.
To overcome these limitations, the authors propose a graphical model that simultaneously incorporates three complementary types of cues: (1) distance features that encode the ratio of Euclidean distances between pairs of points, (2) angle features that capture the internal angles of small geometric primitives (triangles or quadrilaterals) and are invariant to rotation and modest scaling, and (3) appearance features derived from local image descriptors such as SIFT, HOG, or color histograms attached to each node. The model’s energy function is a linear combination of these cues, with separate weight parameters (θᵈ, θᵅ, θᵃ) that control the relative influence of each term.
The novelty lies in learning all parameters via structured prediction rather than hand‑tuning them. The authors adopt a Structured Support Vector Machine (Structured SVM) formulation where the loss is defined directly on the entire matching assignment (e.g., Hamming loss between the predicted and ground‑truth correspondences). During training, a cutting‑plane algorithm iteratively adds the most violated constraints, and sub‑gradient descent updates the weight vector. This end‑to‑end learning aligns the model’s objective with the actual evaluation metric, allowing it to automatically balance distance, angle, and appearance information according to the data distribution.
Inference is performed on a graph that is deliberately kept tree‑like, enabling exact dynamic‑programming (message‑passing) inference in O(N²) time, where N is the number of points. When loops are present, the authors employ a Laplacian regularization and a loop‑correction heuristic to obtain a good approximation without sacrificing speed. Consequently, the method runs in roughly half a second to one second on shapes with a few hundred vertices, comparable to the state‑of‑the‑art integer‑programming or spectral‑matching baselines.
Experimental validation uses two widely‑used 3‑D datasets: FAUST (human body scans) and TOSCA (synthetic objects). For each dataset the authors generate perturbed versions with controlled scale changes (5‑10 %) and appearance alterations (different lighting or texture). The proposed model consistently outperforms recent methods such as Spectral Matching, Integer Programming, and previous graphical‑model approaches. Accuracy improvements range from 8 % to 12 % on average, with the most pronounced gains in scenarios where scale variation is present. Precision also rises because the appearance term helps disambiguate ambiguous regions. Importantly, these gains are achieved without a noticeable increase in runtime; the learning phase, accelerated by GPU computation, completes within a few hours for thousands of training pairs.
The paper acknowledges two main limitations. First, the inference efficiency depends on the graph’s near‑tree structure; dense graphs with many cycles would require more sophisticated approximate inference techniques. Second, the reliance on a fixed set of appearance descriptors may limit generalization to domains with drastically different visual characteristics. Future work could explore automatic feature selection, multi‑scale descriptor fusion, and extensions to partial or many‑to‑many correspondences.
In summary, the authors present a robust near‑isometric matching framework that integrates geometric (distance, angle) and photometric (appearance) cues within a learnable graphical model. By training the model with structured loss, they achieve a balanced, data‑driven weighting of the cues, leading to substantial accuracy improvements while preserving computational efficiency. This contribution advances the state of the art in shape correspondence, especially for real‑world datasets where perfect isometry cannot be assumed.
Comments & Academic Discussion
Loading comments...
Leave a Comment