Getting in the Zone for Successful Scalability
The universal scalability law (USL) is an analytic model used to quantify application scaling. It is universal because it subsumes Amdahl’s law and Gustafson linearized scaling as special cases. Using simulation, we show: (i) that the USL is equivalent to synchronous queueing in a load-dependent machine repairman model and (ii) how USL, Amdahl’s law, and Gustafson scaling can be regarded as boundaries defining three scalability zones. Typical throughput measurements lie across all three zones. Simulation scenarios provide deeper insight into queueing effects and thus provide a clearer indication of which application features should be tuned to get into the optimal performance zone.
💡 Research Summary
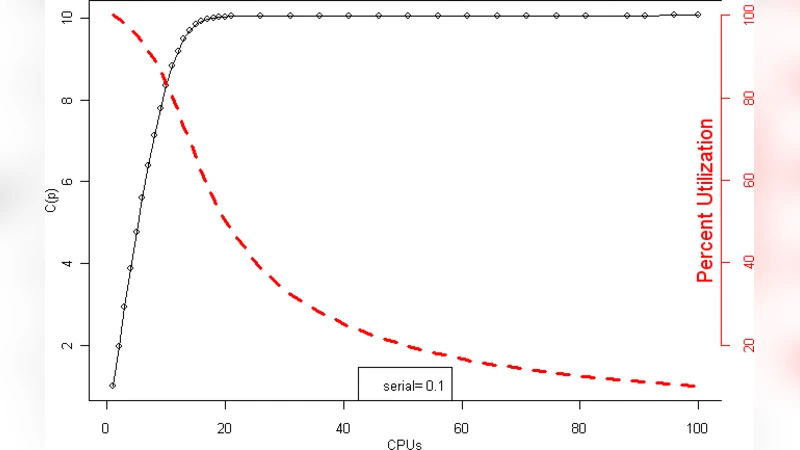
The paper presents a comprehensive study of the Universal Scalability Law (USL), positioning it as a unifying analytic model that subsumes both Amdahl’s law and Gustafson’s linear scaling as special cases. The authors first demonstrate, through discrete‑event simulation, that the USL is mathematically equivalent to synchronous queueing in a load‑dependent Machine Repairman (MRM) model. In this mapping, the USL throughput formula S(N)=N/(1+α(N‑1)+βN(N‑1)) corresponds directly to the MRM repair rate λ/(1+α+βN), where α captures the serial fraction of work and β represents contention or communication overhead that grows quadratically with the number of processors N.
The simulation framework assumes Poisson arrivals and exponential service times, while varying α and β to explore a wide parameter space. The resulting throughput curves reveal three distinct regions that the authors term “scalability zones.”
-
Serial‑limited zone (α‑dominant) – For small N, the linear term α(N‑1) dominates, reproducing Amdahl’s law. Performance gains diminish quickly as N approaches the critical point N₁≈1/α.
-
Ideal‑scaling zone (both α and β negligible) – In an intermediate range, the quadratic β term is still small, and the system behaves like Gustafson’s linear scaling, with near‑linear throughput increase.
-
Contention‑saturation zone (β‑dominant) – For large N, the βN(N‑1) term overwhelms the numerator, causing throughput to plateau or even decline. The transition point is approximated by N₂≈1/√β.
Empirical measurements from real‑world applications often span all three zones, showing a characteristic “knee” where performance abruptly shifts from the ideal region into saturation. By interpreting measured data through the USL/ MRM lens, the authors can pinpoint whether a system’s bottleneck is primarily serial work (high α), communication/contention (high β), or a combination of both.
The paper then translates these insights into concrete tuning recommendations:
- Reduce α by refactoring code to eliminate unnecessary sequential phases, applying more fine‑grained parallel algorithms, and exploiting compiler optimizations.
- Maintain N within the ideal‑scaling zone by matching the number of active cores to the workload’s parallelism, avoiding over‑provisioning that pushes the system into the β‑dominant region.
- Mitigate β through asynchronous designs, reducing lock contention, employing hierarchical communication patterns, and optimizing data locality, especially on NUMA or distributed‑memory platforms.
Additional simulation scenarios examine CPU‑bound, I/O‑bound, and mixed workloads across multi‑socket, NUMA, and cloud‑virtualized environments. The results confirm that CPU‑bound tasks tend to exhibit larger α values, while I/O‑bound or network‑intensive tasks show pronounced β effects.
In conclusion, the authors provide a unified theoretical foundation that links USL to a well‑understood queueing model, clarifies the three scalability zones, and offers a practical roadmap for performance engineers. By diagnosing which zone a system occupies and adjusting α or β accordingly, practitioners can steer applications into the optimal performance region, achieving scalable throughput without incurring the diminishing returns typical of large‑scale parallel systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment