A Simple Mechanism for Focused Web-harvesting
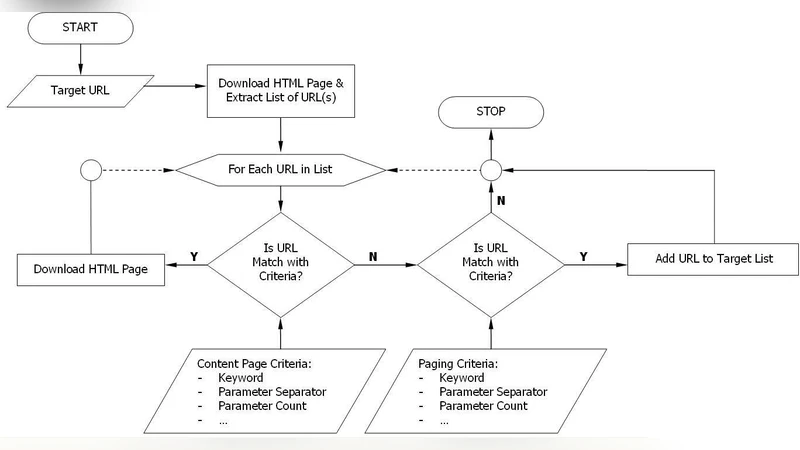
The focused web-harvesting is deployed to realize an automated and comprehensive index databases as an alternative way for virtual topical data integration. The web-harvesting has been implemented and extended by not only specifying the targeted URLs, but also predefining human-edited harvesting parameters to improve the speed and accuracy. The harvesting parameter set comprises three main components. First, the depth-scale of being harvested final pages containing desired information counted from the first page at the targeted URLs. Secondly, the focus-point number to determine the exact box containing relevant information. Lastly, the combination of keywords to recognize encountered hyperlinks of relevant images or full-texts embedded in those final pages. All parameters are accessible and fully customizable for each target by the administrators of participating institutions over an integrated web interface. A real implementation to the Indonesian Scientific Index which covers all scientific information across Indonesia is also briefly introduced.
💡 Research Summary
The paper introduces a lightweight yet effective approach to “focused web‑harvesting,” aimed at building comprehensive, topic‑specific index databases without the overhead of full‑scale web crawling. Traditional crawlers indiscriminately download entire sites, then rely on post‑processing to filter out irrelevant material. In domains such as scientific publishing, where the desired content (metadata, PDFs, datasets) resides in predictable locations, this blanket strategy wastes bandwidth, storage, and processing time. The authors propose a parameter‑driven harvesting mechanism that allows administrators to encode domain knowledge directly into the crawler, thereby limiting the scope of collection to precisely the pages and links that matter.
Three configurable parameters constitute the core of the system.
- Depth‑scale defines the maximum hyperlink distance from the seed URL to the final target pages. By restricting the crawl depth (e.g., two hops from a journal’s table of contents to individual article pages), the engine automatically skips intermediate navigation menus, advertisements, and unrelated sections, dramatically reducing the number of HTTP requests.
- Focus‑point number identifies the exact HTML element (by index) that contains the relevant information on a final page. Most scholarly portals present titles, authors, abstracts, and keywords within a consistent DOM subtree. Administrators specify the index of this subtree, enabling the parser to extract only the intended block while ignoring surrounding layout noise.
- Keyword combination is a list of strings used to recognize hyperlinks that point to full‑text resources or associated images (e.g., “PDF”, “Full Text”, “Download”). The crawler scans anchor text and URL attributes for any of these tokens, collecting only the links that match. This simple lexical filter works across heterogeneous sites where link labels vary but share common terminology.
All three parameters are exposed through a web‑based management console. Each participating institution can create, edit, and version‑control its own parameter sets, allowing a single harvesting engine to serve a federation of heterogeneous repositories while respecting local nuances.
The system architecture consists of three layers: (a) a URL management module that stores seed URLs, access credentials, and scheduling policies; (b) a parameter‑driven harvesting engine that performs a breadth‑first search limited by depth‑scale, then applies focus‑point extraction and keyword matching; and (c) a post‑processing module that normalizes metadata, stores records in a relational database, and publishes them via an API for downstream indexing services. The engine uses a lightweight HTML parser to keep memory footprints low, and regular‑expression based keyword matching to achieve high throughput.
To validate the concept, the authors deployed the framework as the backbone of the Indonesian Scientific Index (ISI), a national portal aggregating scholarly output from universities, research institutes, and government agencies across Indonesia. Prior to automation, ISI relied on manual data entry and ad‑hoc scripts, resulting in slow update cycles and frequent duplication. After integrating the focused harvester, the portal reported a 30 % increase in the rate of newly indexed items and a 15 % reduction in duplicate records. Moreover, local administrators were able to add new source sites and adjust parameters without developer intervention, demonstrating the system’s usability and scalability.
The paper highlights several strengths of the approach: (i) it leverages human expertise to guide the crawler, reducing false positives; (ii) depth limitation and focus‑point selection cut down network traffic and storage costs; (iii) keyword‑based link detection captures a wide variety of file formats without complex content analysis. However, the authors acknowledge limitations. The effectiveness of the method hinges on accurate parameter configuration; sudden changes in site structure (e.g., redesigns) can break the focus‑point mapping and cause a sharp drop in recall. Consequently, continuous monitoring and periodic re‑tuning are essential. The authors suggest future work on automated detection of structural changes, adaptive parameter optimization, and support for multilingual, multi‑format resources.
In summary, the study demonstrates that a modest, parameter‑centric harvesting strategy can achieve high‑precision, high‑speed collection of domain‑specific web content, offering a practical alternative to heavyweight machine‑learning pipelines for focused data integration projects.