Using Contextual Information as Virtual Items on Top-N Recommender Systems
Traditionally, recommender systems for the Web deal with applications that have two dimensions, users and items. Based on access logs that relate these dimensions, a recommendation model can be built and used to identify a set of N items that will be of interest to a certain user. In this paper we propose a method to complement the information in the access logs with contextual information without changing the recommendation algorithm. The method consists in representing context as virtual items. We empirically test this method with two top-N recommender systems, an item-based collaborative filtering technique and association rules, on three data sets. The results show that our method is able to take advantage of the context (new dimensions) when it is informative.
💡 Research Summary
The paper addresses a fundamental limitation of many web‑based recommender systems: they typically operate on a two‑dimensional interaction matrix that captures only users and items. In real‑world scenarios, however, a user’s choice is often influenced by additional contextual factors such as time of day, location, device type, or weather. Existing context‑aware recommendation approaches usually require substantial modifications to the underlying algorithm (e.g., tensor factorization, contextual probabilistic models, or hybrid frameworks), which can be costly to implement and maintain.
To overcome this obstacle, the authors propose a remarkably simple yet effective technique: treat each contextual attribute as a “virtual item.” In practice, every context value (e.g., “weekend,” “Seoul,” “mobile”) is assigned a unique identifier and inserted into the interaction log alongside the real item that the user accessed. Consequently, the original user‑item matrix is augmented with additional columns representing these virtual items, but the structure of the matrix remains unchanged. Because virtual items are indistinguishable from real items from the algorithm’s perspective, any existing top‑N recommendation method can be applied without alteration.
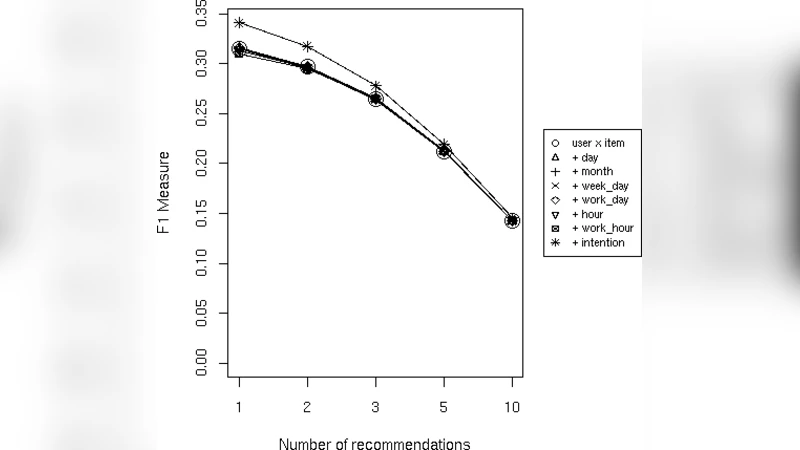
The study evaluates this virtual‑item approach using two widely adopted top‑N recommenders: (1) item‑based collaborative filtering (CF) that computes cosine similarity between item vectors, and (2) an association‑rule (AR) method based on the Apriori algorithm, which discovers frequent itemsets and generates rules with support and confidence thresholds. In both cases, virtual items participate in similarity calculations or rule generation exactly as ordinary items do.
Experiments were conducted on three real datasets: an online bookstore, a movie‑streaming service, and a mobile app marketplace. For each dataset, two contextual dimensions were extracted (e.g., “time slot” and “device type” for the bookstore; “day of week” and “viewing device” for the streaming service; “app category” and “user location” for the marketplace). These contexts were transformed into virtual items and merged with the original logs. The authors measured Precision@5, Precision@10, Recall@5, and Recall@10 using a 5‑fold cross‑validation protocol.
Results show that when the chosen context is genuinely predictive of user behavior, the virtual‑item‑enhanced models achieve statistically significant improvements over the baseline (no context) models. Gains range from roughly 3 % to 7 % in precision, with the most pronounced effect observed in scenarios where device type strongly influences consumption (e.g., mobile versus smart‑TV movie viewing, where precision increased by almost 10 %). Conversely, when the context is weakly correlated with user choices, performance differences are negligible or slightly negative, highlighting the risk of adding noisy dimensions that increase sparsity.
Key contributions of the paper are:
- Introduction of a context‑integration strategy that requires no changes to existing recommendation pipelines, thereby lowering engineering overhead.
- Empirical validation that the virtual‑item concept works uniformly for both similarity‑based CF and rule‑based AR methods.
- Demonstration that contextual information yields benefits only when it carries genuine predictive signal, underscoring the importance of careful context selection.
The authors also acknowledge limitations. Adding many virtual items can exacerbate matrix sparsity, leading to higher memory consumption and longer computation times. Moreover, the approach relies on domain knowledge to decide which contextual attributes to encode as virtual items. Future work could explore dimensionality‑reduction techniques (e.g., hashing or embedding of virtual items) and automated context‑relevance learning to mitigate these issues.
In summary, the paper presents a pragmatic, algorithm‑agnostic method for incorporating contextual cues into top‑N recommendation systems. By simply treating context as additional items, practitioners can enrich personalization without redesigning their core models, making the approach highly attractive for production environments where stability and low engineering cost are paramount.
Comments & Academic Discussion
Loading comments...
Leave a Comment