TRANS-Net: an Efficient Peer-to-Peer Overlay Network Based on a Full Transposition Graph
In this paper we propose a new practical P2P system based on a full transposition network topology named TRANS-Net. Full transposition networks achieve higher fault-tolerance and lower congestion among the class of transposition networks. TRANS-Net p…
Authors: Stavros Kontopoulos, Athanasios K. Tsakalidis
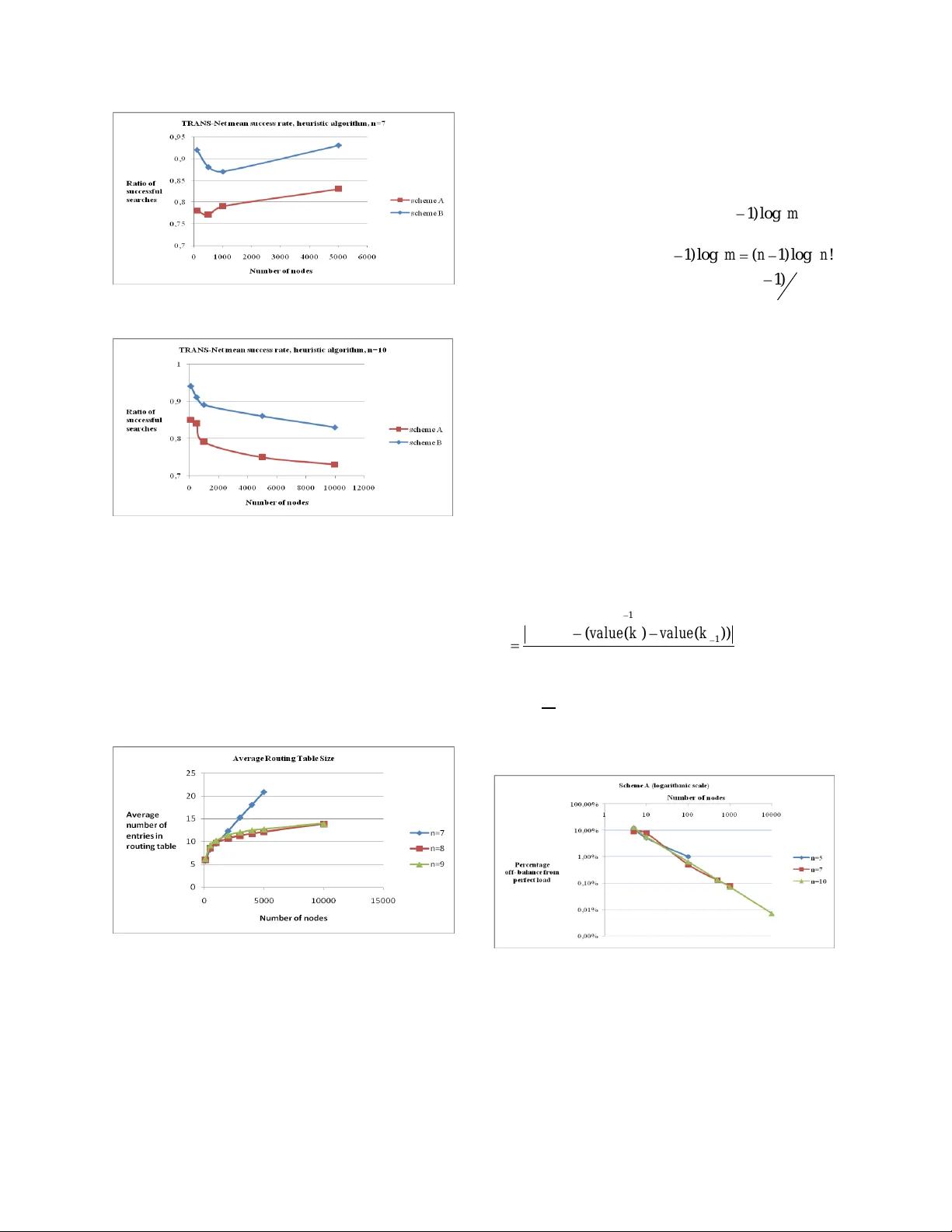
TRANS-Net: an Efficient Peer- to -Peer Overlay Network Based on a Full Transpositi on Graph Stavros Kontopoulos Athanasios Tsakalidis Comp. Eng . & I nf. Dept. Comp. Eng. & I nf. Dept. University of Patras University of Patras kontopou@ceid.upatras.gr & Computer Technology I nstitute Patra, PO 22500 tsak@cti.gr Abstract In this paper we propose a new pra ctical P2P system based on a full transposition network topology named TRANS-Net. Full transposition networks achieve h igher fault -tolerance and lower congestion among the class of transpo sition netwo rks. TRANS - Ne t provides an efficient lookup service i.e. k h ops with high probability where k satisfies 2 ( l o g ) ( l o g ) n m k m , where m denotes the numb er of system nodes and n is a system parameter related to the maximum numb er that m can ta ke (up to n!) . Experiments show that the look-up performance achieves the lower limit of the co mplexity relation . TRANS-Net also preserves data lo cality and p rovides efficient loo k-up performan ce for co mplex queries such as multi-dimensional q ueries. 1. Introduction and related work P2P system s emerged as a class of distributed system s focusing on load balancing and providing guarantees for the lo okup pro cess counted in num ber o f hops in the virtual top ology. In our work we introduce a new p rotocol that uses a transposition network with nodes arranged also in a ring topology. Our sy stem keeps the order of data and suppor ts one dimensional range queries, multi- dimensional queries. Most structured P2P systems fall under the categor y of distributed hash tab les (DHT s) which form an overlay netw ork that maps keys to network nodes and objects using some consistent hashing fun ction. Some popular DHTs are CAN[11], Chord[14], Pastry[12] , Tapestry[1], Koorde[4] . Some P2P system s fall under the category of tr ee based systems . T he latest, Baton* [3] is a tree based system that exhibits (l og ) t Om lookup performance with O( t ) ro uting spac e overhead wh ere t is the tree fanout. Baton* is a non-trivial improvem ent over the Baton [ 2] system w ith Baton being a sim ilar tree b ased system w ith fan-out 2. All results are achieved at the presence of m nod es in the system . The query support of our system is n ot available to DHT s sys tems. Compared to Bato n* our system is b ased on a sym metrical topolo gy which guarantees th at traffic w ill be equally sh ared among available links in a flash crowd scenario. Moreover o ur system is more fault-tolerant than Bato n*. Koo rde is a P2P system based o n a sparse De Bruij n network embedded in a ring. The sparse network is a necessary condition for Koorde to guarantee optimal performance. Compared to Koorde our system works efficiently for b oth dense and sparse netw orks. There are three b asic top ologies based on transpositions: star netw orks [8], [9 ], p ancake networks [8] , [9] and full transposition networks [6]. P ancake networks were used as o verlay networks in [5] , [10] . Compared to [5 ] , our system is optimized f ro m a m ore practical perspective avoid ing the usage of moving virtual peers and data order is preserve d. Mo reover in [10] a P2P system is prop osed that uses a tree based framework to achieve O(1) load balancing w .h.p. The framew ork emulates a pancake overlay. Again here virtual nodes are necessary. An interesting issue here is whether full transposition n etworks can be em ulated by a sim ilar and/or other frameworks. T he rest of the p aper is structured as follow s. In section 2 we define full transposition networks. In sections 3 to 8 we introd uce our new P2 P system design based on full transposition netw orks and discuss parameters of our design such as basic system operations, load balancing, multi- dimensional query support, load -balancing, fault- tolerance and congesti on. In sectio n 9 we analyze the performance of the new overlay n etwork. Section 10 concludes the paper and d escribes future w ork. Overall, our con tribution is that: We introduce a new pr actical, competitive yet simple P2P system based on an innovative design, using a transposition netw ork. Our sy stem simultan eously op timizes or achieves good values for several P 2P design parameters leading to a good overall d esign compared to other systems . We show how o ur system explicitly supports multi -dimensional queries, without proper modification or extension. Since our system does not fall to a specific categor y w e have chosen to compare it with the popular P 2P system Chord when th at is applicab le . 2. Prelim inaries 2.1. Notation In th is context w ith m w e denote th e num ber of peers in a P2P system , n is a sys tem parameter that is used to represent the number of symbols that constitute a permutation. As it is describ ed in the following sections, n influences th e number of p eers in a static star network which is n ! and inevitably the maxim um num ber of peers, again n !, participating in our proposed P2P system , T RANS-Net. 2.3. Full Transpositi on Networks Definition 1 Let G be the finite group o f permutations on a set with n elements numbered as {1, 2 ,…n} and S be a set of generators for the group clo sed under inverses w ith S be ing: ,, i,j 1 2 1 1 1 1 12 { ( ) , ( ) } w ith π ( ) . . . ... , . . . ... i j i j j i j i j i n j i n S p P p P p p p p p p p p p p p p p p p p wh ere P is the set of all possible permutations. Then the Full Transposition Network (FT N) on G is the graph with vertex set G and edge set E defined as follows , { ( , ( ) } , , , { 1 , 2 , . . , } , ij E p p i j n i j . The number o f the unique links is 2 2 n n . Basic properties o f this graph, wh ich is also a Cayley graph, such as diameter and fault-tolerance ar e analyzed here [6]. FTN has a diameter of n- 1. This sm all d iameter is wh at w e seek to explo it in our routin g alg orithm. In order to use a FTN network for one dimensional exact query matching we m ust p rovide a routing algorithm wh ich finds a path from a certain node to another node. Routing algorithms on tr ansposition networks, usually exploit the underly ing mathem atical structure of permutations w hich leads to op timal routing design as in [ 15]. In our appro ach a greedy algorithm is chosen for fault-tolerance issues and its simplicity and imm ediate applicab ility in a P2P syst em . On a FT N netw ork with n ! nodes we can route a message from a node 1 ... n X x x to some nod e 1 ... n Y y y by means of transpositions at each step co rrecting a digit of X from left to right until X is replaced b y Y . Since all transpositions are available we can route a m essage in O( n ) steps. 3. A Pee r- to -Peer Syste m Based on FTN s. FTN n etworks are static n etworks. In the field of P2P system design it is necess ary for the top ology of the sys tem to be dynam ic. In other words i t cannot be assum ed that all peers will be present in the system . In order to cop e with that we simply embed a FT N netw ork in a Chord like ring . When a node links to some m issing node it replaces it w ith its im mediate successor on the ring. T his way we ensure that we can approach greedily the target at the absence of some nodes in the netw ork transf orming the sy stem to a dynam ic one. Now we are ready to describe a P2P system based o n the modified FT N network just described. We call this modified FT N networ k TRANS-Net. 3.1. System model Let n be a parameter of the system. Eac h p eer has a unique identifier taken from the set of n! permutations using some hashin g function and then the permu tation identifier is mapped to a number in the key space [ , ] le ft ri gh t NN .The choice o f the map function and of the appropr iate values of , le ft ri gh t NN will be discussed in section 5 (the load balancing section). Collisions here can be checked by a simple lo okup of the key generated by the hashing function o r they can be avoided with the p roper value of n . Data elements in the network are indexed by an identifier taken from the interval [ , ] le ft ri gh t NN . Each peer v is responsible for the keys that belong to the interval ( . , ] v predece ssor v wh ere v.pred ecessor is the clo sest preceding node to v . Our sy stem inherits the good properties of the Chord ring like dynam ic manipulation of node j oins and leaves. 4. System Operat ions TRANS- Net offers the basic operations f ound in most DHTs sy stems w hich are key lo okup, key insertion/deletion and p eer join/leave. T hese op erations are described here. The key lookup is performed by locating the successor peer on the r ing for a key followin g FTN links (star links ). Here we introduce two algorithm s for searching in a TRANS- Net . 4.1. Greedy Algorithm The first routing algorithm fin ds amon g the available links of the current node the one that leads us closer to the tar get node. T his is done by checking its routing table. Comparisons for pickng the ap propriate link ar e made using the virtual distance from the tar get node and sp ecifically from the left and right b ounds of the key space allocated to the candidate node for the next step. T his is necessary for the cor rectness of our algorithm and it implies that we hold for ea ch routing table entry , additional inf ormation for the key space manag ed by the node in that entry. The pseudocod e of the greedy algorithm is given nex t: Algorithm 1 Greedy_Search_key (x, k) Input : x is current node, k is the key to be found Output: node that holds k //O is the node that owns key k if the netw ork had n! //nodes. 1. Node O=owner (k); 2. Node C=find_closest_to_target_in_route_table( O); 3. Greedy_Search_key (C, k); Figure 1. TRANS- Net ’s greedy a lgorithm. The search algor ithm ensures that the wh ole pro cedure converges to the target peer. 4.2. Heuristic Algori thm Along with the ab ove algorithm we im plemented a heuristic that corrects one digit o f the current node’s permutation id accord ing to the target node’s id. This algorithm may fail to track the tar get nod e but this fact does not make the algorithm useless since its hit rate is high accor ding to our experimen tal results ( see experimental section). The followin g theorems indicate the performance of bo th algor ithm s. In a T RANS- Net netw ork with m peers routing a message is accomplished in () On hops in the worst case. In the average case the routing algorithm performs much better depending only on the current number m o f peers. We have the follow ing theorem: Theorem 1 : In a TRANS- Net netw ork with m p eers routing a mess age is accomplished in k hops in the average case where k satisfies 2 ( l o g ) ( l o g ) n m k m . Proof. The set of all possible permutations with each permutation having n sym bols ca n be distrib uted to n classes according to the leftm ost sy mbol. Each class can be further divided to subclasses accord ing to the next digit from the left. The i -th digit from the left divides the previous class to n-i subclasses. We proceed until we have subclasses of size 1. Let m be the num ber of peers in the system. Now suppo se w e choose for those m p eers randomly a per mutation identifier from the set of n ! possible permutations. On the average case the p ermutation identifiers are evenly distributed to all classes. For example each mem ber o f the first group of classes acco rding to the leftmost sym bol should have on the average m n peers. Let X b e a peer who searches for a key q wh ich is owned by peer Y. W e must mention here that the permutation id of the node T which would have own ed q if n! nodes were present belongs to Y ’s key space too. Let X be the first peer o n the cir cle and Y b e the last one. Hence, we have the m aximu m p ossible distance to the target which is 0 D m in terms of the num ber of peers. In the first step of the ro uting algorithm the leftm ost d igit is corrected, we get closer to the target and the distance becomes: 1 ( 1 ) mm D m n nn . In the second step the distance becomes 1 ( 2 ) ( 1 ) ( 1 ) m m m D n n n n n n . In the final k -th step we have for the distance: 1 ( 1 ) ( 1 ) k m D n n n k . It holds that: , 3 ( 1 ) ( 1 ) 2 k k m m m n n n n k n wh ich implies that 2 log l o g n m k m . This analysis is enough for the heu ristic algorithm. In order to extend to the greedy algorithm we need to take into consideration the fact that it is po ssible that the closest distance may not b e th e one that lead s to a node that cor rects the appropr iate digit according to T ’s id . T his may lead to a slow -down o f the algorithm as a matter of fact it may lead to a serialized movem ent on the ring. We clarify this by an example and show that this event is rar e and hopefully it can be tracked and avoid ed . Su ppo se the initial node fo r the key look up is X =365241 for a TRANS- Net w ork with n=6 and we search for a key for wh ich T ’s id is 413562 (see next figure). Figure 2. Example for proof o f theorem 2. It is obvious that our algorithm will cho ose the successor o f node 36 5241 w hich is S =3651 24 as closest to the target (fig.2 black ar row), instead of the successor node in its routing table of node 465 231. Following such a node do esn’t lead to a new node wh ere some of its digits in its permutation id are equal to the respective d igits in taget’s node id. Luckily that’s not a p roblem. As we move closer to the target inevitably we will get to a node where its digits ar e in accordance with those of the target. In practice, in order to move fast to a node which finally cor rects the relative digit and avoid a serial move on the ring, we mus t detect this event. Notice here that between S and T there can be a large number of nodes w hich we want to leave b ehind. Detection is easy b ecause we will b e forced, ac cording to the greedy algorithm, to move repeatedly to nodes w hich leave the approp riate digit incorrect and slow ly lead to the target. In any of these steps we can j ump to a node which corrects the digit. In the example this m eans that w e sh o uld move to node 465231 (fig. 2 , red ar row) and continue from there the key loo k-up. This is an adequate solution, since as we show next the event is as a matter of fact rar e. Let’s see wh y. The left most digit of the tar get’s id should be one greater than the leftmost digit of the initi al node’s id. This happens with probability 1 n . Moreover, the seco nd leftm ost digits of the two identifiers should have the appropr iate difference counted in number of positions in the sorted per mutation I, 1 23456 in our example. In the example the second leftmost permutation d igit of the initial node is 6 while the second leftm ost permutation digit o f the target id is 1. T he difference h ere is 1. This mak es node’s 36 5 2 41 successor closer to the tar get than the successor of node 465 231 . We count the p robability of having the app ropriate distance for all relevant combinations of digits being at most 1 min us the probability of not having it for the cases wh ere this is determined only from the current leftmost digit. T he last prob ability is : n n- 1 2 . n2 Hence the total probability of the event describ ed in the abo ve example is at most 1 2 n . Hence with high probab ility as n gets big enough the event is rare. This fact concludes our proof and sug gests that the constant in the expression of the theorem is small as it is derived from the experimental results. T hough our analysis is not tight it is obvious that the quantity ( 1 ) ( 1 ) m n n n k is close to k m n and this fact is proven from the exper imental results that achieve the lower bound of the complexity of the theorem (see experimental evaluation section for more details). Remark : Exploiting the ord er of the identifiers on the ring, the ra nge queries of the form [ , ] lr kk require ( ) O n A hops in the w orst case and ( ) O k A in the average, where A is the number of permutation-based identifiers betw een the peers responsible for , lr kk respectively. Now we will extend theor em 2 to hold with high probability. Theorem 2 : In a T RANS- Net netw ork with m peers routing a message is acco mplished in k hops with h igh probability where k satisfies 2 ( l o g ) ( l o g ) n m k m . Proof. Again we use the idea of the d istribution of permutations to classes accor ding to the pr oof of theorem 2 . Permu tations are distributed unif ormly at random. Let m be the num ber o f peers in the system. In itially , for the leftmost symbol of a p ermutation we Successor of 465231 S=36512 4 X=36421 5 T=41 3562 have n classes which get m n permutations each, on the average. Now for mn it is a classical r esult that the maxim um load will be with high probability () m n . Within of each of these n classes the load () m n is distributed to n-1 classes again according to the next sym bol from left to right and so on. For each distribution it hold s the same bo und for the maxim um load except for the last few distrib utions for which the load is almost equal to the number of available classes. For the last case the maxim um load deviation is lo g ( ) lo g lo g v v w.h .p. where v is the lo ad. Let X be a p eer wh o searches for a key q which is ow ned by peer Y. We have the maximum p ossible distance to the target wh ich is 0 D m in terms of the number of peers. I n the first step of the routing algorithm the leftmost digit is co rrected, we get clo ser to the target and t he distance becomes: 1 () m D n w.h .p. in the worst case . In the second step the distance becomes 1 ( ) ( 1 ) m D nn w.h .p in the worst case . I n some step j it holds ( 1 ) . . . ( 1 ) m n n n n j and so the distance left is at most lo g ( ( 1 )) lo g lo g n n n . In two steps from that step on w e reach the destination. We have for the to tal distance co vered : ( ) 1 ( 1 ) ( 1 ) k m D n n n k . It hold s th at: , 3 ( 1 ) ( 1 ) 2 k k m m m n n n n k n which implies that 2 ( l o g ) ( l o g ) n m k m . 4.3. Key Insertion/Del etion, Node join/leave Insertion and deletion of keys is easily done by means o f the above searching algorithm and it is trivial to im plement them. Hence, the cost in the number of hops for insertion or deletion of a key is () On . Each new node in order to j oin the sys tem must first generate a new permu tation to acquire its identifier. Then it contacts a peer w hich is know n to be alm ost surely active. The peer contacted by the new peer conducts a key lookup for th e identifier of the new node. Assum ing n o collisions, it fin ds the successor and informs the new node about its position on the ring. The new node enters the ring in a way similar to that in Chord by setting his pred ecessor and successor links and notifying for his pr esence both his predecessor and successor peers. After that the new peer needs to set his FTN links. In order to do this it searches for all nodes wh ich are closest successors or predecessors to the keys produced by transpositioning the d igits of its identifier relevant to some specific digit. The cost for joining the network is 3 () On in the worst case and 2 ( ) O n k in the average. The pro cedure of leaving the netw ork is simple. The pee r leaving the network contacts its neighbors and informs them that it is about to leave. Since a node points to 2 () On nodes the total cost of this operation is 2 () On . 5. Load Balancing In o ur system obj ect identifiers are chosen from the key space and the system does not impose any restriction on this procedure. Hence, the ord er of the data can be preserved . System nodes id entifiers are chosen as follows. A new node q , selects in a uniform ly random way, a permu tation from the set of the ! n po ssible permutations. Let this selected permutation b e 12 [ , , . .., ] n D d d d . Then this permutation is mapped to a number in th e key space [ , ] le ft rig ht NN . Here we describe tw o key assignm ent schemes in the sense that they equally distribute the load of keys to each peer . Other mapping functions are possible. 5.1. Key Assignment Scheme A The first key assignm ent schem e represents each permutation as a n digit num ber in the n +1 -ary number system . As a result the identifier o f the new node q would be : 12 12 ( ) 1 1 .. . 1 nn n f q d n d n d . For this scheme, the bounds , left right NN are set to values 0 and 11 n n respectively. T he key assignm ent f is a bij ection and in o rder to use it along with the greed y algorithm described previously we implem ented the reverse function finding the node that holds a particular key, owner of the key. T he mapping we use here raises the q uestion whether it p roduces a balanced distribution of the node identifiers over the sp ace referenced abo ve. We provide a simple analysis that reveals that this is in fact a balanced and simple identifier assignmen t scheme follow ed by extensive experimental results. Let 1 2 ! { , , .. ., } n S Y Y Y be the set of all po ssible permutations sorted by their value. We select randomly and unif ormly m d istinct permutations from S and let 12 { , , . .., } m Q q q q be the set of these permutations. If we pick two successive permu tations 1 , ii qq then it holds on the average: 1! , i j i n j m q Y q Y . Now let m = n and , 1 , 2 , [ , , ... , ] j j j j n Y y y y . Also let , 1 1 [ , , .. ., ] A j n Y y x x , , 1 1 [ , , ... , ] B j n Y y x x , where 1 ... n x x , 1 , 1 , ..., 1 , 2 , . . . , nj x x n y and 1 { , , . . . , } j A A B Y C Y Y Y S . T he set d enoted b y C is sorted like S and contains (n -1)! permu tations. Similary ! 1 ( 1 ) ! { , , . . . , } n C C D j j n m Y D Y Y Y S , wh ere , 1 1 [ 1 , , . . . , ] C j n Y y w w , , 1 1 [ 1 , , . . . , ] D j n Y y w w and 1 ... n w w , 1 , 1 , .. ., 1 , 2 , . . . , ( 1 ) nj x x n y . Obviously ( 1 ) ! , j j n YY differ in their first digit from the left and since their total distance in the permutation s order is (n-1)!, their value difference ( 1 ) ! ( ) ( ) j n j v a lu e Y v a l u e Y is 1 ( 1 ) n n . The perfect load for a node in the network is for m = n , PLoad = 1 11 1 n n n n n . Hence, w e achieved almost optimal lo ad balancing. T he same ideas hold for 23 , , . . ., n m n n n movin g one digit to the right in each case. 5.2. Key Assignment Scheme B The seco nd key assignm ent scheme is more flexible as it will be clear from our discussion. Let { 1 , 2 , .. ., } Fn be the set of symbols wh ich form a permutation and S be the set of all possible permutations. T he sym bols i n F ar e common numbers and so we can order them in the ordinary way 1 2 ... . n . This order implies that we can order S as well according to the lexicographic order. As a result we can present S with its elements o rdered: 1 2 ! { , , .. ., } n S Y Y Y , 1 2 ! ... p p p n Y Y Y . T he sym bol p in an expression as p x y obviously denotes that x preced es y in the order of permutations. Let { 1 , 2 , ..., !} Wn . Our goal is to find a bij ection : f S W wh ere f will b e the mapping function. F plays the role of ( ) value mention ed in scheme A. If w e carefully observe the representation of a permutation we can deduce that its first digit from the left can be used to divide S in n classes of permutations with each class containing per mutation s that have the same leftmost digit. Each class co ntains ( 1 ) ! n mem bers. T hinking in a similar w ay we can d ivide further each class to subclasses accord ing to the next digit from left to right stopping at a class with size 1. Each class is equally divided each time w e m ove from one digit to the other. Since permutations are ord ered, classes can be ordered in the same manner. Easily then we can find the p osition o f a p ermutation X in S b y counting the total number of permutations belonging to classes prec eding X . It is straigh tforward to see that f should be: 12 1 1 2 2 ( , , ..., ) ( ) ( 1 ) ! ( ) ( 2 ) ! . . . 1 1 ! 1 n f x x x w x n w x n wh ere 12 ... n X x x x S . Let 1 [ , , ..., ] i i i n S x x x and ( ), j p x i j n be the p osition nu mber of j x if we sort i S . T hen ( ) ( ) 1 i i i w x p x . Now suppose that we would like to cr eate the key space for o ur T RANS- Net wh ich has ! n peers. We assign to each peer K keys wh ere K is a constant system par ameter. The first peer is assigned the keys [0,K -1], the second peer the keys [K,2K-1] etc. T he last peer is assigned the key s [( n!- 1)K, n!K-1]. The total key sp ace is [0, n!K-1 ] and bounds , le ft ri gh t NN are set to values 0 and n!K- 1 respectively. Searching f or a key x in TRANS- Net wh ich uses mapping function B is easy. W e first calculate the pee r P wh o is resp onsible for x, 1 x P K . Then we calculate the weights () ii wx , by solving the following eq uation 12 ( , , ..., ) n f x x x P , wh ich is a simple task and is ac complished by simple division. Next we ca lculate () i px and then i x . At last we have the P’s per mutation id wh ich allows to route through the TRANS- Net . T he mapping function B is more flexible than A since it is not restrictive and key space can be customized easily. On the other hand function A is presented in this pap er because we believe it is a useful candidate for future P2 P design involving networks based on permutations. 6. Multi-Dimensional Queries As we w ill show shortly our sy stem is capable o f handling multi-dim ensional queries. Firstly we think of data as a set of n-dimensional ar rays of the f orm: 1 { , .. . } n x x x wh ere n is our system’ s p arameter and 1 2 1 2 , , 1 , . . . , , , i x D D i n D D . Each data array x is normalized (min-m ax) to an array y, 1 { , .. . } n y y y , for which it holds: 21 ( 1 ) 1 ii i xD y n DD . Each data array y is assigned to the node which ow ns the closest permutation id entifier 1 [ , . . . , ] n P z z such as ( ) ( ) f P f y , ( ) f refers to the mapping function used by schemes A and B . W hat we have accomplished here is to distrib ute multidimens ional data o n our netw ork nodes in a meaning ful w ay allowin g queries on the data to be answ ered effectively. We underline here that it is easy to see that r ange multi-dimensional queries can also be supported by visiting consecutive nodes. W e leave as future work imm ediate app lications such as P2P image sim ilarity. One possible r estriction of our schem e is the parameter n which is defined as a constant thus determining the maxim um num ber of dimensions . 7. Fault-Tolerance and Congestion In this section we investigate the fault-tolerance and congestion parameters of our sy stem. Bisection width (BW) is a co mm on metric for both the capacity of the netw ork and the fault-tolerance. Large capacit y mean s large tolerance o n cong estion and failures. Bisection width is of primary im portance in the case of high loads with random destinations. Formally bisection w idth is defined as the smallest num ber of edges betw een two partitions of equal size of the grap h d escribing the netw ork under consideration. In [7] a comparison is made of several popular topologies based on their bisection width. For Baton* a new ly developed system not m entioned in [7], it is easy to prove its bisection width value, which is Θ (m). From [7] ,[13] we can see that the full transpo sition network (r egarding the complete topology graph of netw orks being compared) has a larger value than the value of a star netw ork wh ich is sim ilar to a pancake network. T he ratio is 4 n . Furtherm ore, we can ded uce that for B utterfly n etworks and De B ruizn networks which have co mparable bisection w idth values, their BW values are lar ger than the BW of a full transposition netw ork. The ratio for the co mplete graphs of each topology is Θ (n). CAN and Chord ar e co mparable to Baton* [ 7]. Vertex connectivity is another fault to lerance metric of a netw ork. Regarding the vertex connectiv ity metric the full transposition topology is optimal [6]. T here are ( 1 ) 2 nn distinct paths betw een tw o nodes in the netw ork and this is equal to the number of distinct paths for a co mplete De Bruizn topolo gy of the same num ber of nodes. In [4] it is proven that a network in order to stay connected when all nodes fail with probability ½ some nodes need to have degree (l o g ) m , where m is the number o f nod es in the system . It is easy to notice from the experimental discussion of the routing table size that as our network gets dense it satisfies this requirement. This can not b e fulfilled in all cases by other tr ansposition n etworks such as pancake and star networks which have a maxim um degree of n-1 . For example for a com plete netw ork o f n! nodes a pancake network has a degree n - 1 wh ich is far less than logn!. Formally we can prove by induction on n, for n>3, it hold s that deg ( ) 1 l o g ! ree pancak eNet n n . On the other hand, for a com plete transposition network we can prove also by induction on n that: 2 deg ( ) l o g ! , n > 2. 2 n n ree FTN n 8. Implem entation In ord er to evaluate our system in prac tice we implem ented a simulator and conducted extensive experiments. Both mapping functions describe d ab ove were fully implemented. The simulation sy stem w as implem ented in Java and it pr ovides a graphical user interface for basic op erations such as network initialization, netw ork p arameter setting and statistical metric reporting. 9. Experimental Evaluation In the following paragraphs w e pr esent experimental results that are indicative of our sy stem efficiency and give support to the theoretical analy sis wh ere it is available. E xperiments run on an Intel Core Duo 1.99 GHz co mputer with 1 Gbs of RAM. All experiments were repeated 4 0 times to avoid the effect of randomness. 9.1. Key Look-up Perf ormance In the next figures it is shown the average loo kup cost in num ber of hops for the search of a randomly generated key and with the search operation initiated from a random node in a T RANS- Net netw ork of N=100, 5 00, 10 00, 5000, 100 00 nodes. In each experiment w e chose 100 random nodes among the available ones and executed 100 ran dom search key lookups from ea ch node. Each experiment was executed several times. The p arameter n was set to values 7, 10. The results were acquired using the greedy algorithm (fig. 3 , 4 ) and the heuristic algorithm (fig. 5 , 6). W e also compare d our P2P system ’s performan ce with the one exhibited by C hord. Figure 3 . Search key look up performance f or TRANS-Net for n=7 when g reedy algorithm was used. Figure 4 . Search key look up performance f or TRANS-Net for n=10 w hen greedy algorithm was used. Figure 5. Search k ey loo k up perfo rmance for TRANS- Net for n=7 when heuristic a lgorithm was used . Figure 6. Search k ey loo k up perfo rmance for TRANS-Net for n=10 when heuristic algorithm was used . The results abo ve for the heuristic algor ithm follow our theoretical analysis and they are also comparab le to those of the greedy algorithm. We mus t note here that the mean length path for the heuristic algorithm is counted for successful searches only. Our heuristic algorithm made at most three attempts to find a key restarting a search operation from a diff erent random node found in its routing table when the search operation initially failed. In addition for the key assignm ent B , the K p arameter doesn’t affect the mean path length. It is clear from the results that T RANS- Net show s significantly bette r key look-up performance than Chord. Com pared to other more efficient P 2P system s, T RANS-NET exhibits similar per formance. For example it is comparable to that of Baton*. Fo r the latest we can tune its performance by adj usting the tree fan o ut. By tun ing n parameter in our system we ca n also manage p erformance sp eed-up. Our heuristic algorithm shows hig h success rates as it is depicted from the f ollowing results (fig. 6, 7): Figure 7. Mean success rate for the heuristic algorithm , n=7. Figure 8. Mean success rate for the heuristic algorithm, n=10. 9.2. Routing Space Overhead In this section we investigate the growth in size of the routing tab le of a node, as the sy stem’s number of nodes increases. Specifically, we count the average num ber of distinct entries in the routing tab le of a node as the netw ork grows in size. Figure 9- Average ro uting table for n=7,8 ,9. From the figures above we can deduce that there is an analogy to the population of the network and the size of the routing table. For example if the netw ork contains half of its maximu m num ber of nodes then it is expected for a node to co ntain approximately half o f the maximum p ossible d istinct entries in its routing table. It is well-kn own that there is a trade-off between diameter and d egree b ased o n the Mo ore bound and is easy to see that T RANS-NET is not optimal. Generally this is not a problem and our system is not inefficient. For example Baton* has a degree of ( 1 ) l og t t m wh ere m is the nu mber of nodes in the system . Suppose t=n and m=n! , then we have ( 1 ) l o g ( 1 ) l o g ! tn t m n n . For TRANS-NET we have a degree of ( 1 ) 2 nn wh ich is smaller than the degree of Bato n*. 9.3. Load Balancing Schemes Evaluation Here we evaluate the tw o key d istribution schemes that we proposed earlier . We verified the theoretical analysis given ab ove by means of extensive experiments . For each schem e, scheme A and schem e B, we co nducted an experimen t for each value o f n =5, 6, 7, 8, 9, 10, 1 1 and for each value of generated permutations k =5, 10, 100, 5 00, 1000, 1000, 10000 . Each experiment was repeated several times. The experiment was as follows. Firstly we generated k permutations, for some n and sorted them acco rding to their values. Then for each pair of successive permutations 1 , ii kk we calculated the quantity 1 ( ( ) ( )) ii PLoad v al ue k v al ue k A PLoad wh ere PLoad is the load for each node if keys were evenly distributed, namely ! n k . In the next figures we show the mean value of A for the values of n=5, 7, 10, k=5, 1 0, 10 0, 50 0, 1000, 1000, 10000 where k<=n! . Figure 10 - Mean value o f A for scheme A, logarithmic sca le for b oth ax es was used wit h base 10 . Figure 11 - Mean value o f A for scheme B, logarithmic sca le for b oth ax es was used with ba se 10 . From the results ab ove we can conclude that the schemes d istribute evenly the lo ad to the peers of the proposed overlay netw ork and this distribution r apidly approaches the optimal as new peers join the netw ork. 10. Conclusion and Future Work We have just described a highly practical P2P overlay netw o rk, TRANS- Net , based on the full transposition network. As far as we know this is the first P2P system d esigned based on this type of netw ork. Our P 2P system eff iciently supports multi- dimensional q ueries. It also exhibits almost op timal load b alancing properties on the average, w hen scheme A is used. Future work includes, but is not limited to, extensive implementation , further more detailed analysis of TRANS- Net and exploitation of the framew ork for P2P applications such as P 2P image similarity . 11. References [1] Ben Zhao B., Kub iatowicz J., Joseph A., Tapestry: An infrastructure for fault-to lerant wide-area location and routing .Technical Report UCB/CSD- 01 -11 41, Computer Science Division, U. C. Berkeley, A pril 20 01. [2] Jagadish H. V., Ooi B. C. , and Q. Vu. BATON : A Balanced Tree Stru cture for Peer - to -Peer Networks . In Proceedings of the In ternational Conference on V LDB, 2005, 661 - 672. [3] Jagadish, H. V ., Ooi, B. C., Tan, K., Vu, Q. H., and Zhang, R. 200 6. Speeding u p searc h in peer- to -peer networks with a multi-way tree structure. In Proceedings of the 2006 ACM SIGMOD interna tion al Conference on Mana gement o f Da ta (Chicago, IL, USA, June 27 - 2 9, 2 006). SIGMOD '06. ACM Press, New York, NY, 1- 12 [4] Kaashoek F. M ., Karger R. D., Koorde: A simple degree-optimal distrib uted hash table . In Pro c. 2 nd IPTPS, Berkeley , CA, Feb. 2003 . [5] Kuh n F., Sch mid S. Smit, J., and Wattenhofen R., A Blueprint for constructin g peer- to - peer system s ro bust to d ynam ic worst-case join and leaves, Quality of Service, 2 006, IWQoS, 14 th IEEE Intern ational Workshop on, vol., pp.12 -19 , June 200 6. [6] Latifi , S. an d P .K. Srimani, Transposition n etworks as a class of f ault-to lerant robust networks, IEEE Trans. Parallel Distrib. Sy s., Vol. 45, no. 2, Feb. 1996, pp. 230 - 238. [7] Loguino v, D., Kuma r, A., Rai, V., and Ganesh, S. Graph-theoretic analysis of structured peer - to - pe er system s: routing distan ces and fault resilience. In Proceedings o f the 2003 Conference on Applicatio ns, Technologies, Architectures, and Protocols For Computer Communica tions (Karlsruhe, Germany , August 25 - 2 9, 20 03). SIGCOMM '03. ACM, New York, NY, 395 - 406. [8] Mo rales L. and Sudbo rough Ha l I., Compa ring S tar and Pancake Netwo rks , Th e Essence of Compu tation , LNCS 2566, pp . 18 -36, 2 002. [9] Qu C., Nejdl W., and Kriesell M. , Cayley DHTs - A GroupTheoretic Framework for Analyzing DHTs Based on Cayley Graphs . In Internation al Symposium on Parallel and Distrib uted Processing and Applications (ISPA), 200 4. [10] Ratajczak D., Hellerstein J., Deconstructing DHTs, Intel Research Tec hnical Repo rt IRB- TR - 03 - 042. [11] Ratnasamy , S., Francis, P ., Handley, M., Karp, R., and Schenker, S. 200 1. A scalable content -addressable network. In Proceedings of th e 2001 Conference o n Applications, Technologies, Architectures, and Proto cols For Computer Comm unications (San Diego, California, United States). SIGCOMM '01 . ACM Press, New York, NY, 161- 172. [12] Rowstron A., Druschel P., Pastry: Scalable, distributed object locatio n and routing for large -scale peer-topeer systems , in Middleware, 2001. [13] Stacho, L. and Vrt'o, I. Bisection widths of transpositi on graphs. In Proceedin gs of the 7 th IEEE S ymposium o n Parallel and Distribu teed Processing (October 25 - 28 , 1995). SPDP . IEEE Com puter Society, Washington, DC, 681. [14] Stoica, I., Mo rris, R., Karger, D., Kaashoek, M. F., and Balakrishnan, H. , Chord: A scalable peer- to -peer lookup service for in ternet application s. In Pro ceedings of th e 20 01 Conference on Application s, Technologies, Architectures, and Proto cols F or Computer Comm unication s (San Diego, California, Unit ed States). SIGCOMM '01. ACM Press, New York, NY, 149 -160. [15] Tajozzake rin H. R. , and Sarbazi-Azad H. , En hanced- Star: A New Topo logy Based o n th e Sta r Grap h . Lecture Notes in Computer Science, Sp ringer Berlin / Heidelberg, Volume 3358 /2004 .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment